Clear Sky Science · pt
BiG-SCAPE 2.0 e BiG-SLiCE 2.0: agrupamento de sequências de clusters gênicos metabólicos escalável, preciso e interativo
Tesouros químicos ocultos no DNA microbiano
Muitos dos remédios e agentes de proteção de culturas dos quais dependemos vêm de pequenas moléculas produzidas por microrganismos. Esses organismos escondem as receitas para tais moléculas em trechos de DNA chamados clusters gênicos. À medida que o sequenciamento de DNA avança rapidamente, os pesquisadores estão inundados de dados, mas ainda conhecem apenas uma pequena fração do que os micróbios podem produzir. Este artigo apresenta o BiG-SCAPE 2.0 e o BiG-SLiCE 2.0, duas ferramentas de software atualizadas que ajudam cientistas a vasculhar vastos arquivos genômicos para mapear, comparar e organizar essas “fábricas moleculares” ocultas, aproximando a próxima geração de antibióticos e compostos agrícolas da descoberta.
Por que os clusters gênicos importam para a saúde e a agricultura
Os micróbios usam pequenas moléculas especializadas para competir, comunicar-se e adaptar-se ao ambiente. As plantas genéticas para produzir ou quebrar essas moléculas costumam estar agrupadas em clusters gênicos metabólicos. Isso inclui clusters gênicos biossintéticos que constroem produtos naturais complexos e clusters gênicos catabólicos que permitem aos micróbios se alimentarem de compostos específicos ou exsudatos radiculares. Como genes em um cluster atuam em conjunto, encontrar uma dessas regiões em um genoma é como identificar uma “linha de fábrica” autocontida que pode sugerir a estrutura e a função de uma molécula. Ferramentas de mineração de genomas já detectam essas fábricas em bactérias e fungos, mas o desafio real é comparar centenas de milhares de clusters para entender como eles se relacionam e que diversidade química podem abrigar.
Dois motores para ordenar fábricas moleculares
BiG-SCAPE e BiG-SLiCE foram originalmente criados para agrupar clusters gênicos com características centrais semelhantes em “famílias de clusters gênicos”. Cada família deve produzir a mesma molécula ou moléculas intimamente relacionadas. O BiG-SCAPE constrói redes detalhadas de similaridade entre clusters, enquanto o BiG-SLiCE é calibrado para velocidade, capaz de lidar com milhões de clusters transformando-os em impressões digitais numéricas simples e então agrupando essas impressões. Juntos, eles sustentam um ecossistema crescente de pipelines de mineração de genomas, bancos de dados e visualizadores interativos que ajudam pesquisadores a navegar pela química microbiana em escala planetária.
O que há de novo no BiG-SCAPE 2.0
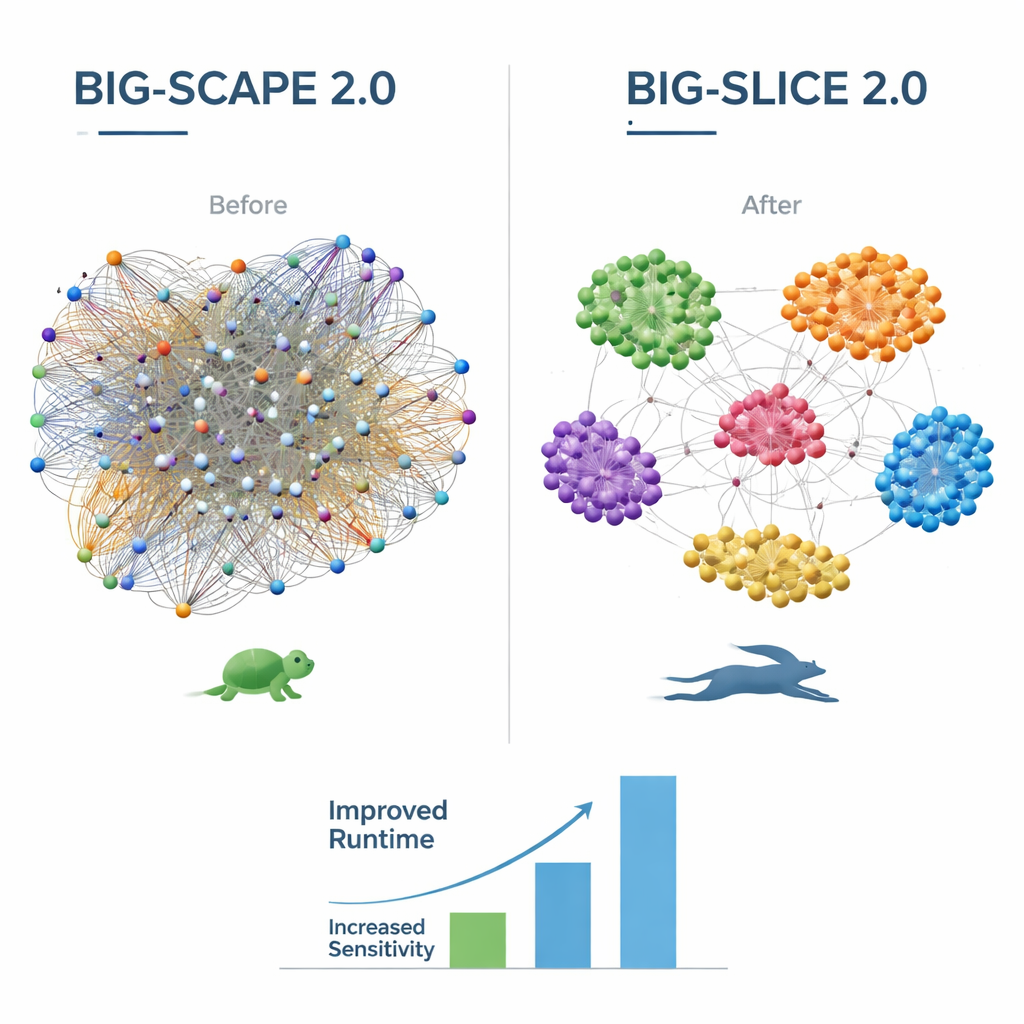
A versão 2.0 do BiG-SCAPE introduz uma série de melhorias voltadas tanto para a biologia quanto para a computação. Agora ela entende o conceito mais refinado de “região” usado pela ferramenta amplamente adotada antiSMASH, que separa clusters gênicos sobrepostos ou híbridos em blocos menores e mais significativos chamados protoclusters. Novos modos e estratégias de alinhamento permitem que o BiG-SCAPE 2.0 foque nos genes centrais realmente importantes dentro de cada cluster, lidando melhor com genes rearranjados e limites de cluster imprecisos. Por trás das cenas, a base de código foi completamente reescrita para velocidade e sustentabilidade, usando um banco de dados SQLite compartilhado e uma biblioteca Python moderna para buscas por perfis. Como resultado, o BiG-SCAPE 2.0 pode rodar até oito vezes mais rápido que seu antecessor, usando cerca de metade da memória, e agora oferece múltiplos fluxos de trabalho prontos para agrupar, consultar, desduplicar e avaliar clusters gênicos por meio de uma interface web interativa aprimorada.
Como o BiG-SLiCE 2.0 acompanha a enxurrada de dados
O BiG-SLiCE 2.0 concentra-se em tornar análises ultra-grandes mais precisas sem perder sua conhecida velocidade. Versões anteriores tratavam todos os tipos de clusters gênicos da mesma forma, o que favorecia inadvertidamente algumas famílias em detrimento de outras. Ao migrar para uma medida de distância do tipo cosseno e atualizar sua biblioteca de assinaturas de proteínas biossintéticas para os padrões mais recentes, o BiG-SLiCE 2.0 agora agrupa tipos muito diferentes de clusters de forma mais equilibrada. Otimizações de código e a adoção da mesma biblioteca rápida de buscas por perfis usada pelo BiG-SCAPE trazem ganhos adicionais de velocidade, e novas opções para exportar todos os resultados como tabelas de texto simples facilitam integrar o BiG-SLiCE a outros pipelines de análise. Testes em nove conjuntos de dados de famílias gênicas manualmente curadas mostram que a precisão do BiG-SLiCE 2.0 agora se aproxima da do BiG-SCAPE, especialmente para clusters gênicos mais curtos e mais difíceis de detectar.
Revelando um vasto universo químico inexplorado
Os autores usaram ambas as ferramentas para examinar 260.630 regiões biossintéticas a partir de um banco de dados público de genomas microbianos. O BiG-SCAPE 2.0 e o BiG-SLiCE 2.0 produziram estimativas notavelmente semelhantes sobre quantas famílias distintas de clusters gênicos existem nesse conjunto de dados, corroborando trabalhos anteriores de que apenas cerca de 3% do potencial biossintético codificado em genomas bacterianos foi caracterizado até agora. Em outras palavras, a grande maioria das moléculas produzidas por micróbios permanece desconhecida. Ao possibilitar agrupar e visualizar clusters gênicos com precisão em centenas de milhares de genomas — e, eventualmente, milhões — o BiG-SCAPE 2.0 e o BiG-SLiCE 2.0 oferecem lentes poderosas para explorar esse universo químico inexplorado, abrindo caminho para novos medicamentos, ferramentas de proteção de culturas mais seguras e insights mais profundos sobre como os micróbios moldam ecossistemas e nossa própria saúde.
Citação: Draisma, A., Loureiro, C., Louwen, N.L.L. et al. BiG-SCAPE 2.0 and BiG-SLiCE 2.0: scalable, accurate and interactive sequence clustering of metabolic gene clusters. Nat Commun 17, 2000 (2026). https://doi.org/10.1038/s41467-026-68733-5
Palavras-chave: clusters gênicos biossintéticos, descoberta de produtos naturais, mineração de genomas, metabólitos microbianos, agrupamento computacional