Clear Sky Science · pt
Avanços e desafios no armazenamento de dados em ácidos nucleicos não canônicos
Por que armazenar dados em moléculas importa
Cada foto, mensagem e filme que criamos precisa ser armazenado em algum lugar, e hoje esse “lugar” são em sua maioria enormes depósitos de discos rígidos que consomem muita eletricidade e se desgastam em algumas décadas. Este artigo explora uma abordagem muito diferente: usar moléculas genéticas especialmente projetadas como fitas de dados minúsculas. Ao ajustar os blocos de construção familiares do DNA e do RNA, os cientistas pretendem criar armazenamento de informação mais denso, resistente e seguro do que qualquer chip de silício ou disco magnético.
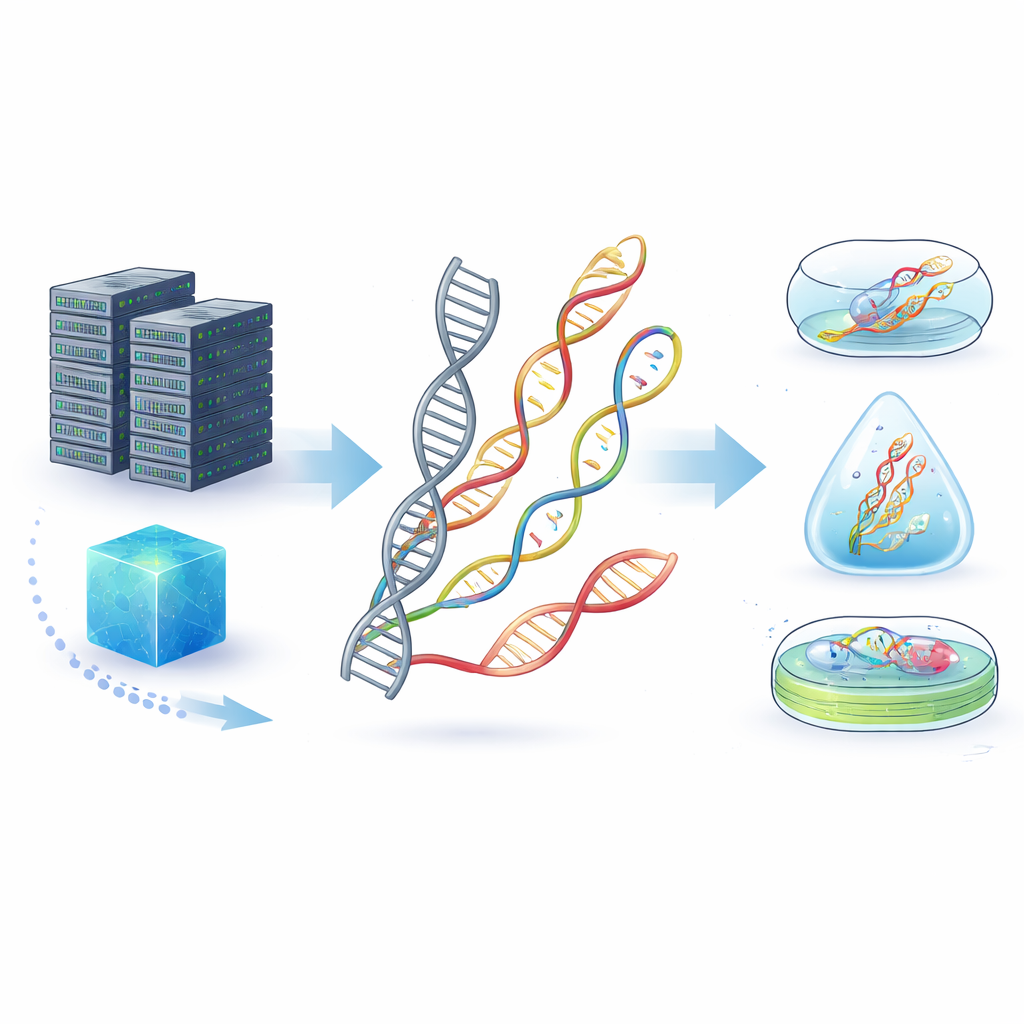
Do DNA frágil a novas moléculas resistentes
O DNA natural já é um meio de armazenamento impressionante, comprimindo enormes quantidades de informação em um espaço microscópico e sobrevivendo por dezenas de milhares de anos em fósseis. Mas em condições cotidianas — calor, umidade, substâncias químicas dispersas ou enzimas que degradam o DNA — ele pode se deteriorar rapidamente. Os autores apresentam os “ácidos nucleicos não canônicos” (ncNAs): moléculas semelhantes ao DNA e ao RNA cujas bases, açúcares ou esqueletos foram alterados quimicamente, ou até espelhados, para conferir novas propriedades. Essas modificações podem tornar as moléculas mais difíceis de serem degradadas por enzimas, mais resistentes a ácidos ou álcalis e melhores em sobreviver a ambientes agressivos do mundo real do que o DNA comum.
Adicionando novas letras ao alfabeto genético
Uma das ideias mais poderosas na revisão é expandir o alfabeto genético além das quatro letras usuais A, T, G e C. Químicos criaram pares de bases extras que ainda se encaixam em hélices duplas, mas não ocorrem na natureza. Com 8, 12 ou mais letras disponíveis, cada posição ao longo da cadeia pode codificar mais bits de informação, aumentando a capacidade de armazenamento muito além do que o DNA padrão oferece. Algumas dessas novas bases foram projetadas para se unirem por interações hidrofóbicas em vez das habituais ligações de hidrogênio, mostrando que as regras naturais de pareamento podem ser dobradas mantendo a informação legível.
Reconstruindo o esqueleto molecular
Além de mudar as “letras”, os pesquisadores também reconfiguram o açúcar e o esqueleto que sustentam uma fita genética. Substituir o açúcar habitual por alternativas como threose ou hexitol, ou trocar ligações fosfato carregadas por ligações neutras ou contendo enxofre, pode alterar drasticamente o comportamento da cadeia. Muitos desses ncNAs exibem estabilidade marcante em condições de calor, acidez ou presença intensa de enzimas, onde o DNA natural rapidamente se desintegraria. Algumas versões em imagem espelhada, como o L-DNA, são invisíveis para enzimas e defesas imunes normais, tornando-as promissoras para armazenamento de dados ultra-seguro e mensagens ocultas, embora atualmente sejam difíceis e caras de sintetizar e ler.
Como os dados são escritos, preservados e lidos
Transformar arquivos digitais em forma molecular segue um ciclo de quatro etapas: codificação, escrita, preservação e leitura. Os bits são primeiro traduzidos em sequências ou estruturas, que então são sintetizadas como fitas de ncNA usando métodos químicos ou enzimas especialmente projetadas. Essas fitas podem ser armazenadas fora de células vivas — encapsuladas em vidro, sílica ou polímeros — ou dentro de células e até plantas modificadas, onde a maquinaria natural de reparo pode ajudar a mantê-las. A leitura dos dados pode usar máquinas de sequenciamento de DNA familiares, dispositivos avançados de nanoporo que “sentem” cada unidade ao passar por um buraco minúsculo, ou microscópios que reconhecem formas em nanostruturas dobradas. Como muitos ncNAs ainda não podem ser sequenciados diretamente, muitas vezes são convertidos de volta em DNA regular antes da leitura, um passo que a pesquisa atual busca simplificar e aperfeiçoar.
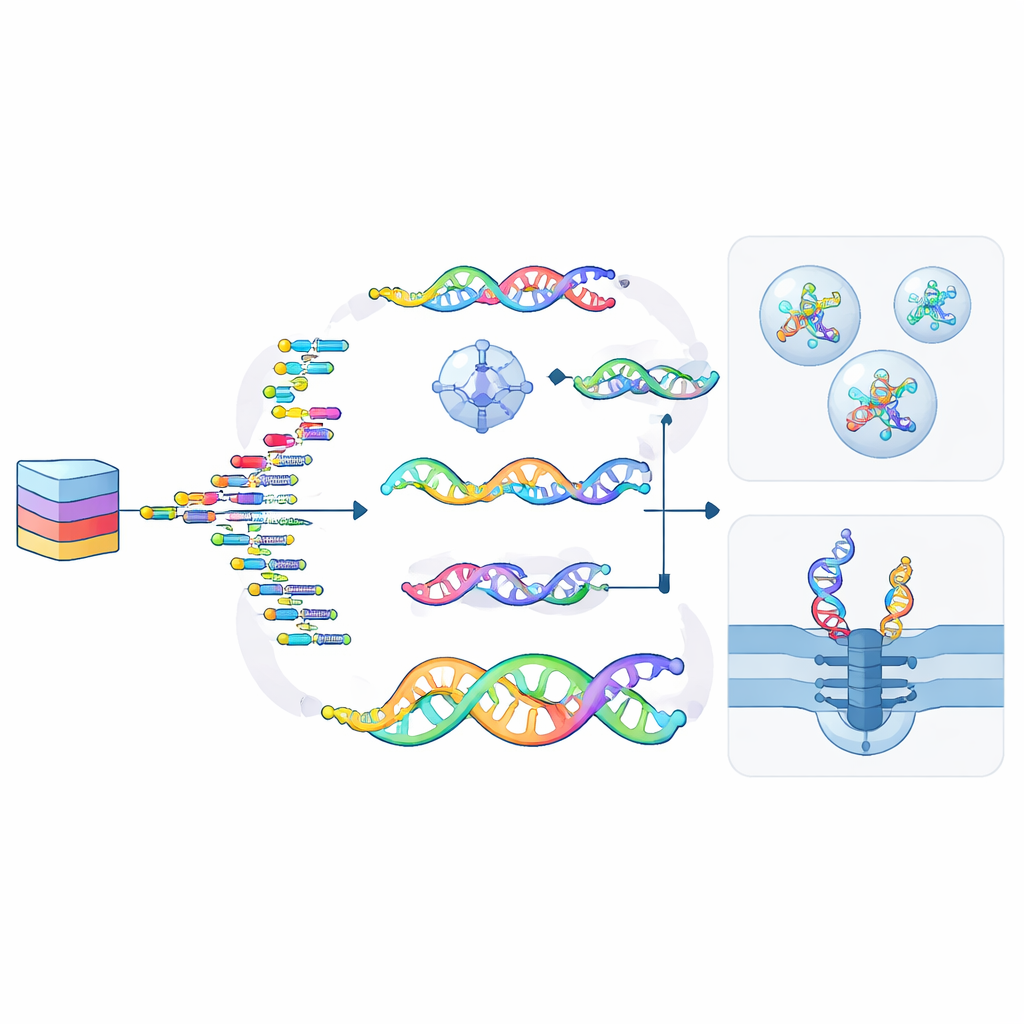
Novas possibilidades: computação, segurança e escrita paralela
O artigo destaca como os ncNAs fazem mais do que apenas armazenar dados — eles também podem processá-los. Circuitos lógicos e redes neurais baseados em DNA já existem, e acrescentar alfabetos quimicamente distintos facilita executar muitas operações em paralelo sem ruído indesejado entre elas. Certas modificações atuam como tinta invisível, permitindo que informações sejam ocultadas em fitas ou estruturas que apenas enzimas especiais ou condições específicas podem revelar. Outras, como adutos químicos reversíveis ou padrões de grupos metila, comportam-se como tipos móveis em uma prensa tipográfica: podem imprimir dados em fitas existentes em paralelo, apagá-los e reescrevê-los sem reconstruir a molécula inteira do zero.
Desafios pela frente e o que o sucesso significaria
Apesar das promessas, os autores enfatizam que o armazenamento em ácidos nucleicos não canônicos ainda está em estágio inicial. Produzir fitas longas e sem erros é caro e tecnicamente exigente, e muitas das químicas mais atraentes ainda não são compatíveis com tecnologias de leitura rápidas e acessíveis. Também existem questões importantes de segurança e ética sobre introduzir moléculas altamente estáveis e parcialmente não naturais em sistemas vivos. Ainda assim, a revisão descreve um roteiro em que síntese mais rápida, encapsulamento mais inteligente e leitores por nanoporo aprimorados por inteligência artificial poderiam tornar o armazenamento baseado em ncNA prático nas próximas décadas. Se isso acontecer, talvez um dia faremos backup de nossa civilização digital não em discos giratórios, mas em fitas minúsculas e robustas de moléculas projetadas.
Citação: Wang, Y., Pei, Y., Tang, L. et al. Advances and challenges in non-canonical nucleic acids data storage. Nat Commun 17, 2354 (2026). https://doi.org/10.1038/s41467-026-68708-6
Palavras-chave: armazenamento de dados em DNA, ácidos nucleicos não canônicos, memória molecular, pares de bases não naturais, sequenciamento por nanoporo