Clear Sky Science · pt
Melhorando a predição por escores poligênicos para grupos sub-representados por meio de aprendizado por transferência
Por que seu escore de risco genético pode não funcionar para você
“Escores” genéticos de risco estão sendo usados cada vez mais para estimar a probabilidade de uma pessoa desenvolver condições comuns, como diabetes, doenças cardíacas ou hipertensão. Mas a maioria desses escores foi construída com dados de DNA de pessoas de ascendência europeia. Como consequência, eles frequentemente têm baixa precisão para pessoas de outras origens, levantando preocupações sobre equidade e utilidade na prática clínica. Este estudo faz uma pergunta simples: podemos reaproveitar o que aprendemos com grandes conjuntos de dados europeus para construir escores genéticos melhores e mais justos para grupos sub-representados—sem compartilhar os dados brutos de ninguém?
De milhões de marcadores de DNA a um único escore de risco
Um escore poligênico é como um boletim que soma os pequenos efeitos de muitos marcadores genéticos espalhados pelo genoma. Cada marcador recebe um peso que reflete o quanto ele se associa a uma característica, com base em grandes estudos genéticos. Quando esses estudos envolvem majoritariamente europeus, o escore resultante tende a funcionar melhor nessa população. Diferenças nas múltiplas origens genéticas—como a frequência de certas variantes de DNA e a maneira como elas são herdadas em conjunto—fazem com que os mesmos pesos frequentemente falhem em populações afro-americanas, hispânicas e outras. Coletar conjuntos de dados igualmente grandes para cada grupo é caro e demorado, então os autores recorreram a uma estratégia de aprendizado de máquina chamada aprendizado por transferência: em vez de começar do zero para cada população, ajustam um modelo existente treinado em outro lugar.
Como emprestar conhecimento sem compartilhar dados brutos
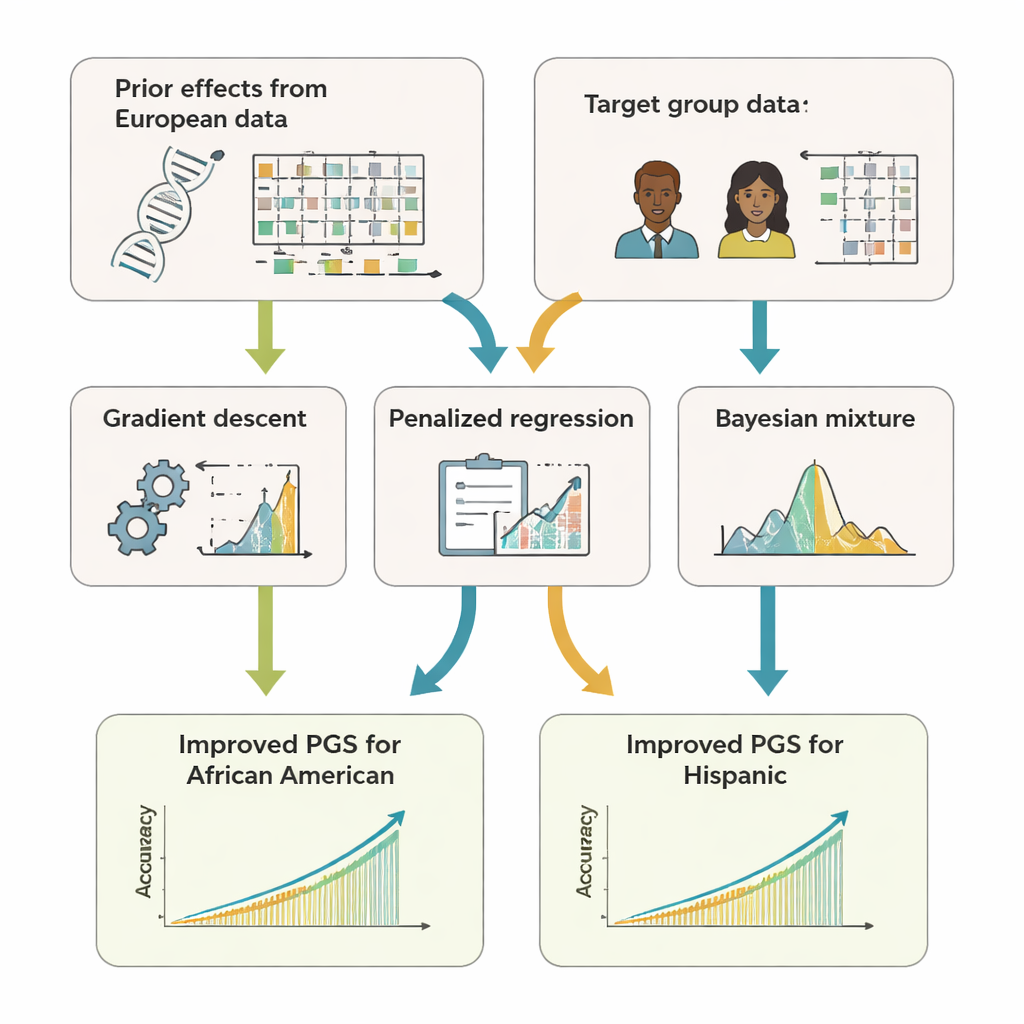
A equipe desenvolveu o GPTL, um pacote de software em R de código aberto que implementa três abordagens de aprendizado por transferência para escores genéticos. As três partem de estimativas existentes dos efeitos do DNA obtidas em um grande conjunto de ascendência europeia e então ajustam essas estimativas usando dados de um grupo-alvo, como afro-americanos ou hispânicos. Um método modifica os pesos europeus passo a passo usando gradiente descendente e para cedo, antes de sobrescrevê-los completamente. Um segundo método, chamado regressão penalizada, puxa ativamente as novas estimativas em direção aos valores originais, a menos que os dados do grupo-alvo forneçam evidência forte em contrário. O terceiro, um modelo de mistura bayesiano, permite que cada marcador de DNA escolha entre várias fontes de informação—como múltiplos grupos de ancestralidade ou até uma opção de “sem efeito”—e as combine conforme o quanto explicam os dados do grupo-alvo.
Colocando os métodos à prova
Para avaliar o desempenho dessas abordagens, os autores usaram tanto simulações computacionais quanto dados reais de centenas de milhares de voluntários do UK Biobank e do programa de pesquisa All of Us dos EUA. Focaram em participantes afro-americanos e hispânicos como grupos-alvo e usaram dados de ascendência europeia como principal fonte de informação prévia. Em 11 características—incluindo altura, índice de massa corporal, lipídios sanguíneos, pressão arterial e marcadores renais—os escores ajustados por aprendizado por transferência previram consistentemente melhor do que escores construídos apenas dentro do grupo-alvo ou reutilizados diretamente dos europeus. Frequentemente, sua acurácia igualou ou superou ligeiramente a de métodos “multi-ancestrais” mais complexos, que exigem combinar dados brutos de várias populações. Crucialmente, os métodos do GPTL precisam apenas de estatísticas sumárias—números agregados sobre efeitos genéticos—de modo que instituições podem colaborar sem expor registros genéticos em nível individual.
Quando mais DNA nem sempre é melhor
Os pesquisadores também examinaram como escolher melhor quais marcadores genéticos incluir. Ao contrário da crença comum de que usar todos os marcadores disponíveis sempre ajuda, eles descobriram que, para grupos afro-americanos e especialmente hispânicos, incluir milhões de sinais muito fracos pode na verdade prejudicar o desempenho, particularmente ao usar representações altamente simplificadas das correlações genéticas. Focar em marcadores com suporte mais robusto e usar informações mais ricas sobre como variantes são herdadas em conjunto frequentemente resultou em escores mais precisos. O estudo também mostrou que adicionar informação prévia de múltiplos grupos de ancestralidade e modelar cuidadosamente as diferenças entre populações melhorou ainda mais as previsões.
O que isso significa para uma predição genética mais justa
Para populações não europeias, os escores genéticos prontos para uso de hoje podem ter desempenho muito inferior, potencialmente ampliando disparidades em saúde. Este trabalho demonstra que o aprendizado por transferência—refinar com inteligência escores baseados em europeus usando conjuntos de dados modestos de grupos sub-representados—pode reduzir grande parte dessa lacuna. Na prática, isso significa que sistemas de saúde e pesquisadores podem construir ferramentas genéticas mais precisas e equitativas sem agrupar dados brutos entre instituições ou ancestralidades, aliviando preocupações de privacidade. Embora nenhum método seja ideal para toda característica e população, o conjunto de ferramentas GPTL mostra que uma predição genética mais justa está tecnicamente ao alcance se tratarmos modelos anteriores não como produtos fixos, mas como pontos de partida adaptáveis a todos.
Citação: Wu, H., Pérez-Rodríguez, P., Boehnke, M. et al. Improving polygenic score prediction for underrepresented groups through transfer learning. Nat Commun 17, 1973 (2026). https://doi.org/10.1038/s41467-026-68696-7
Palavras-chave: escores de risco poligênicos, aprendizado por transferência, predição genética, disparidades em saúde, genética de populações