Clear Sky Science · pt
Aceleradores neurais nanofotônicos projetados por inverse para computação óptica ultracompacta
Por que encolher computadores feitos de luz importa
A inteligência artificial moderna roda em vastos hardwares eletrônicos que consomem enorme quantidade de energia e geram calor. Este estudo explora um caminho bem diferente: usar padrões minúsculos de luz em um chip, em vez de fluxos de elétrons, para realizar partes do cálculo de redes neurais. Os autores mostram que, ao “esculpir” a luz na escala nanométrica, eles podem construir aceleradores ópticos ultracompactos que reconhecem dígitos manuscritos e imagens médicas usando muito menos espaço e, em princípio, bem menos energia do que a eletrônica atual.
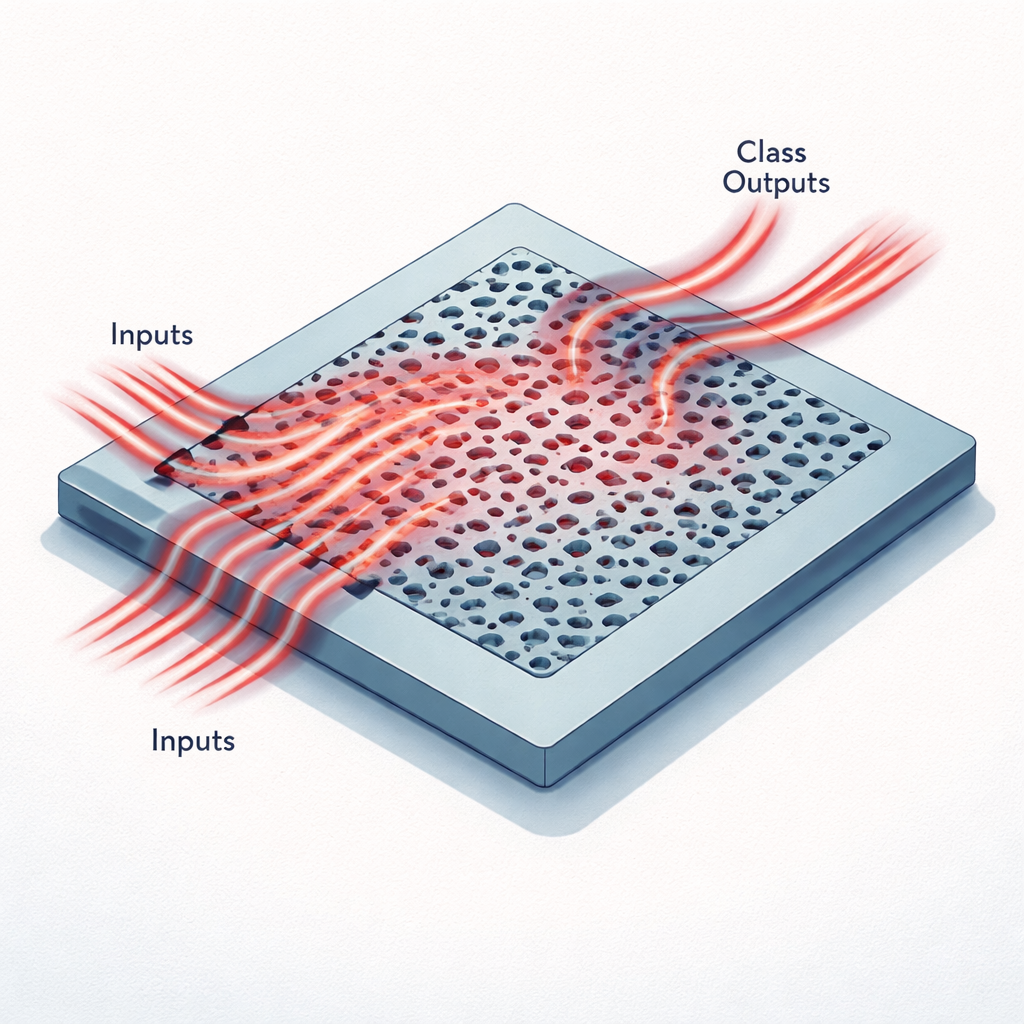
Chips minúsculos que pensam com luz
Em vez de fios e transistores, esses aceleradores usam um pedaço plano de silício padronizado com furos e canais menores que o comprimento de onda da luz infravermelha. Dados de uma imagem são primeiro comprimidos em um pequeno conjunto de números, que em seguida são codificados como o brilho da luz entrando em várias guias de onda estreitas em um único comprimento de onda de telecomunicações. À medida que essa luz flui para a região padronizada, ela é espalhada, interfere consigo mesma e é redirecionada para um conjunto de guias de onda de saída. Cada saída corresponde a uma classe possível, como um dos dez dígitos do conjunto MNIST ou uma das seis categorias em um conjunto de imagens médicas chamado MedNIST. O padrão de potência óptica nas saídas desempenha o mesmo papel da última camada de uma rede neural digital.
Deixar algoritmos desenharem o projeto óptico
Projetar tal estrutura manualmente seria quase impossível, porque cada pequeno “voxel” de material pode alterar como a luz se propaga. Os pesquisadores usam em vez disso uma abordagem de projeto inverso: começam a partir de um padrão aleatório de silício e vidro, simulam como a luz se propaga através dele em três dimensões e então ajustam o padrão para reduzir uma função de perda que mede os erros de classificação. Eles aproveitam a linearidade das equações de Maxwell — as leis que regem a luz — para tornar esse treinamento eficiente. Em vez de simular cada imagem de treinamento separadamente, simulam cada canal de entrada uma vez e depois reconstróem os campos para todas as imagens como combinações lineares desses campos pré-computados. Uma técnica matemática chamada método adjunto fornece então gradientes exatos que dizem ao algoritmo como ajustar cada voxel para melhorar o desempenho.

Classificadores de imagem compactos no tamanho de um grão de areia
Usando essa estratégia, a equipe projetou dois aceleradores de rede neural nanofotônicos em uma plataforma padrão de silício sobre isolante. Um, com apenas 20 por 20 micrômetros de área, classifica dígitos manuscritos do conjunto MNIST; o outro, 30 por 20 micrômetros, classifica imagens médicas do MedNIST. Em simulações, esses dispositivos minúsculos alcançaram acurácias de 97,8% e 99,1%, respectivamente. Versões fabricadas dos mesmos projetos, testadas com lasers e detectores reais, atingiram 89% de acurácia para MNIST e 90% para MedNIST — números notáveis dado o tamanho diminuto dos chips. As estruturas ópticas compactam cerca de 160.000 a 240.000 parâmetros treináveis em áreas menores que um grão de poeira, correspondendo a aproximadamente 400 milhões de parâmetros por milímetro quadrado.
Projetados para velocidade, eficiência e escala
Como os dispositivos são passivos — não há partes móveis ou elementos reprogramáveis durante a inferência — eles não precisam de ajuste contínuo uma vez fabricados. Os “pesos” da rede neural estão codificados na geometria da nanostrutura, de modo que o cálculo ocorre à velocidade da luz com processamento essencialmente em memória: a luz entra com os dados codificados e sai já misturada em pontuações de classe. O método de treinamento também foi concebido para ser escalável. Cada passo de otimização requer apenas um número fixo de simulações de física completa determinado pelo número de entradas e saídas, não pelo tamanho do conjunto de dados, e essas simulações podem ser distribuídas por múltiplas unidades de processamento gráfico. Os autores ainda descrevem como vários desses núcleos ópticos poderiam ser empilhados com fotodetectores entre eles, de modo semelhante a camadas em uma rede neural profunda, e como multiplexação em comprimento de onda ou no tempo poderia aumentar a taxa de processamento.
O que isso significa para o hardware de IA no futuro
Em termos simples, este trabalho mostra que é possível “crescer” pedaços personalizados de vidro e silício que se comportam como camadas especializadas de redes neurais, tudo dentro de uma área suficientemente pequena para acomodar centenas ou milhares deles em um único chip. Embora computadores totalmente ópticos ainda estejam no horizonte, esses aceleradores nanofotônicos projetados por inverse podem descarregar algumas das partes mais consumidoras de energia das cargas de trabalho de IA dos processadores eletrônicos. Se combinados com moduladores rápidos, detectores e um design de sistema inteligente, apontam para hardwares compactos e de baixo consumo em que a luz, em vez da eletricidade sozinha, faz grande parte do trabalho pesado em aprendizado de máquina.
Citação: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Palavras-chave: redes neurais fotônicas, nanofotônica, computação óptica, aceleradores de hardware, projeto inverso