Clear Sky Science · pt
Redes neurais físicas usando treinamento sensível à acuidade
Por que isso importa para o futuro do hardware de IA
À medida que a inteligência artificial se torna mais poderosa, ela é cada vez menos limitada por algoritmos engenhosos e cada vez mais pelos chips que os executam. Uma rota promissora é construir redes neurais diretamente em hardware físico usando luz, eletrônica analógica ou outros sistemas baseados em ondas. Este artigo apresenta uma nova forma de treinar essas “redes neurais físicas” para que permaneçam precisas mesmo quando o mundo real é imperfeito — quando dispositivos são ligeiramente mal fabricados, há deriva térmica ou componentes saem de alinhamento.
De cérebros digitais a máquinas físicas
A IA moderna tipicamente roda em hardware digital como processadores gráficos, onde o treinamento depende do algoritmo de backpropagation para ajustar milhões de pesos numéricos. Redes neurais físicas tentam deslocar esse cálculo para materiais e dispositivos reais — como chips fotônicos, malhas de interferômetros ou arranjos ópticos difrativos — cujo comportamento imita naturalmente a matemática das redes neurais. Porque esses sistemas processam informação onde ela é armazenada, podem ser muito mais rápidos e energeticamente eficientes do que chips convencionais. Mas treiná-los é difícil: ou você treina um modelo digital e espera que ele corresponda ao hardware, ou treina diretamente no próprio dispositivo. Ambos os caminhos enfrentam problemas quando dispositivos reais divergem de modelos ideais ou derivam com o tempo.
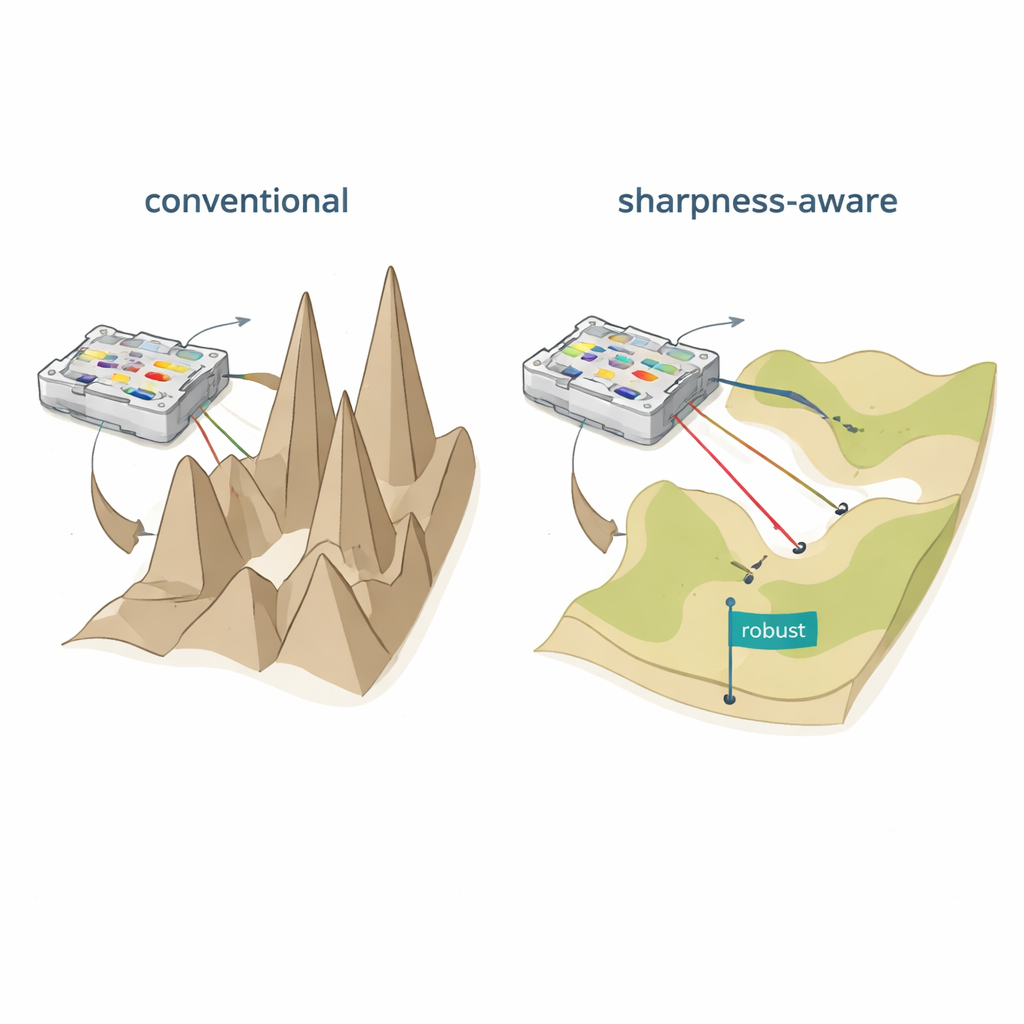
Duas maneiras falhas de ensinar redes físicas
A primeira abordagem, chamada treinamento in silico, aprende todos os parâmetros em um modelo computacional e depois os copia para o hardware. Isso só funciona bem se o modelo matemático corresponder quase exatamente ao dispositivo fabricado, o que raramente acontece quando se incluem variações de fabricação, ruído elétrico e efeitos térmicos. A segunda abordagem, treinamento in situ, integra o dispositivo físico diretamente ao processo de aprendizado, medindo repetidamente as saídas enquanto os parâmetros são ajustados. Embora isso contorne erros de modelagem, cria outros problemas: obter informações de gradiente é difícil e custoso, o treinamento se torna específico do dispositivo, e os parâmetros resultantes geralmente não podem ser transferidos para outro chip nominalmente idêntico. Em ambos os casos, pequenas mudanças após a implantação — como um leve deslocamento de temperatura ou desalinhamento — podem derrubar a acurácia e forçar retrainings caros.
Achatando a paisagem de aprendizado
Os autores propõem o treinamento sensível à acuidade (SAT), inspirado numa ideia de aprendizado de máquina chamada minimização sensível à acuidade. Em vez de apenas encontrar configurações que dão baixo erro nos dados de treinamento, o SAT também busca regiões onde o erro muda lentamente quando os parâmetros físicos subjacentes são perturbados. Em termos geométricos, o treinamento tradicional frequentemente encontra um vale profundo porém estreito na “paisagem de perda”, onde mesmo pequenos deslocamentos em correntes, fases ou posições fazem o desempenho colapsar. O SAT procura deliberadamente vales largos e planos onde o desempenho permanece alto sob tais perturbações. Matematicamente, adiciona um termo ao objetivo de treinamento que penaliza regiões pontiagudas e de alta curvatura no espaço de parâmetros, e aproxima essa penalidade de forma eficiente usando dois passos de gradiente cuidadosamente escolhidos em vez de cálculos caros de segunda derivada.
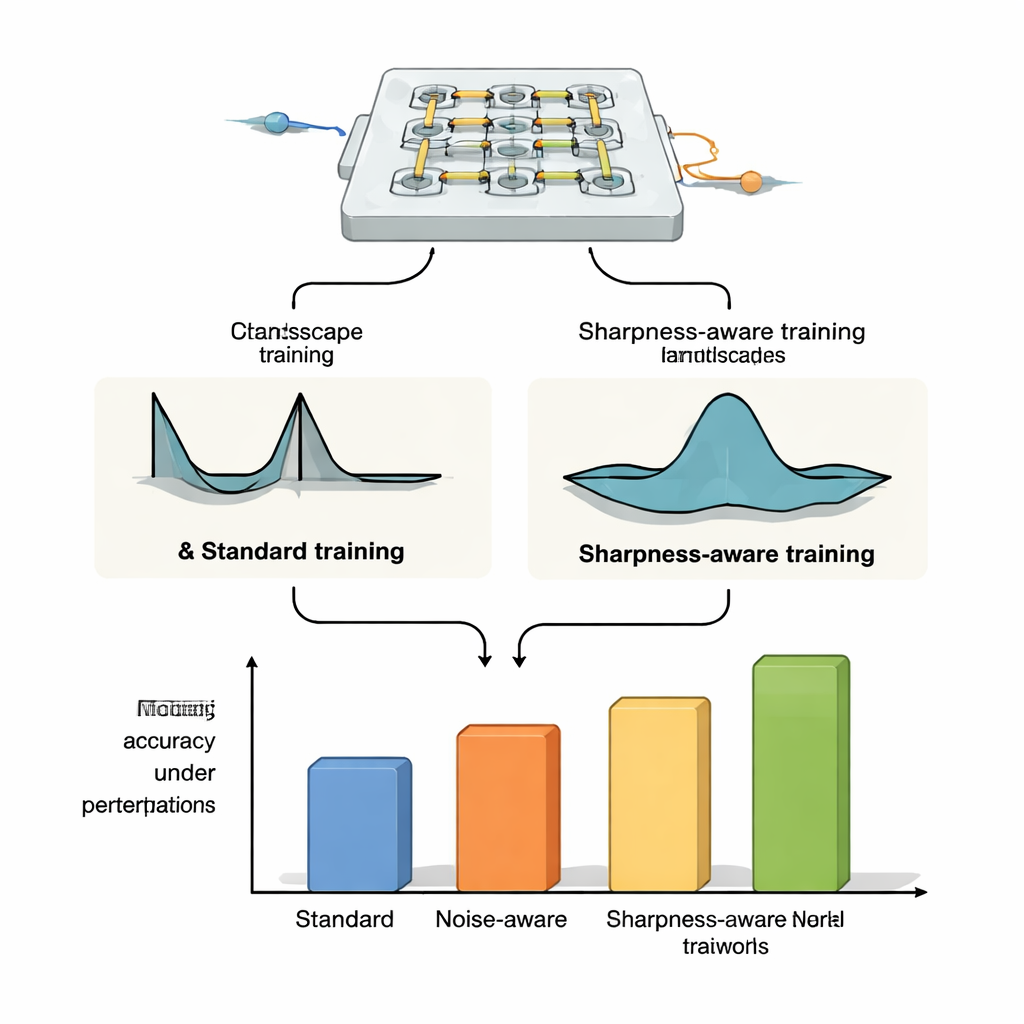
Provando robustez em diferentes plataformas ópticas
Para mostrar que o SAT não está ligado a um dispositivo específico, os autores o aplicam a três plataformas distintas de redes neurais ópticas. Em bancos de pesos por microring-resonators — pequenos laços de silício que roteiam luz em diferentes comprimentos de onda — demonstram que sistemas treinados com SAT mantêm alta precisão de classificação mesmo quando a temperatura varia alguns graus Celsius, enquanto o treinamento padrão e métodos de injeção de ruído falham dramaticamente. Eles estendem isso para tarefas mais exigentes como classificação de imagens no CIFAR-10, compressão e reconstrução de imagens e geração de imagens, onde o SAT mantém o desempenho estável enquanto métodos convencionais se degradam com modestos deslocamentos térmicos. Em simulações de malhas de interferômetro Mach–Zehnder, modelos treinados com SAT são muito mais tolerantes a erros realistas de fabricação e, crucialmente, parâmetros treinados em um dispositivo podem ser transferidos para outros chips com imperfeições diferentes sem perder acurácia. Finalmente, em um arranjo óptico difrativo em espaço livre usando um display OLED, lentes e um modulador espacial de luz, o SAT melhora a tolerância a desalinhamentos físicos como rotação, deslocamentos de pixels e escala, mesmo quando a relação exata entre esses desalinhamentos e os parâmetros da rede não é modelada explicitamente.
Um caminho prático para IA física confiável
Em termos simples, este trabalho mostra como ensinar redes neurais em hardware de uma forma que “perdoa” as inevitáveis peculiaridades de dispositivos reais. Ao orientar o aprendizado para regiões planas e estáveis da paisagem de erro, o treinamento sensível à acuidade torna redes neurais físicas mais precisas e mais robustas a variações de fabricação, mudanças de temperatura e desalinhos mecânicos. Como pode ser usado com ou sem modelos físicos detalhados e funciona em diversos tipos de hardware óptico, o SAT oferece uma receita prática para escalar sistemas de IA física rápidos e energeticamente eficientes de demonstrações de laboratório para aplicações reais.
Citação: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Palavras-chave: redes neurais físicas, computação fotônica, treinamento robusto, otimização sensível à acuidade, hardware neuromórfico