Clear Sky Science · pt
Mapeamento abrangente da dinâmica e interação de modificações de RNA via aprendizado profundo e sequenciamento direto de RNA por nanoporo
As marcas de pontuação ocultas do RNA
As moléculas de RNA de nossas células não são cadeias simples de A, C, G e U. Elas são decoradas com dezenas de pequeníssas marcas químicas que funcionam como sinais de pontuação, ajudando a controlar quais genes são ativados, como as proteínas são produzidas e como as células respondem ao estresse e às doenças. No entanto, até agora os cientistas vinham estudando essas marcas majoritariamente uma a uma, o que dificultava ver como elas atuam em conjunto ao longo de todo o genoma. Este artigo apresenta o ORCA, um sistema de aprendizado profundo que lê moléculas de RNA nativas diretamente e constrói um mapa global e em múltiplas camadas dessas marcas químicas e de suas interações.
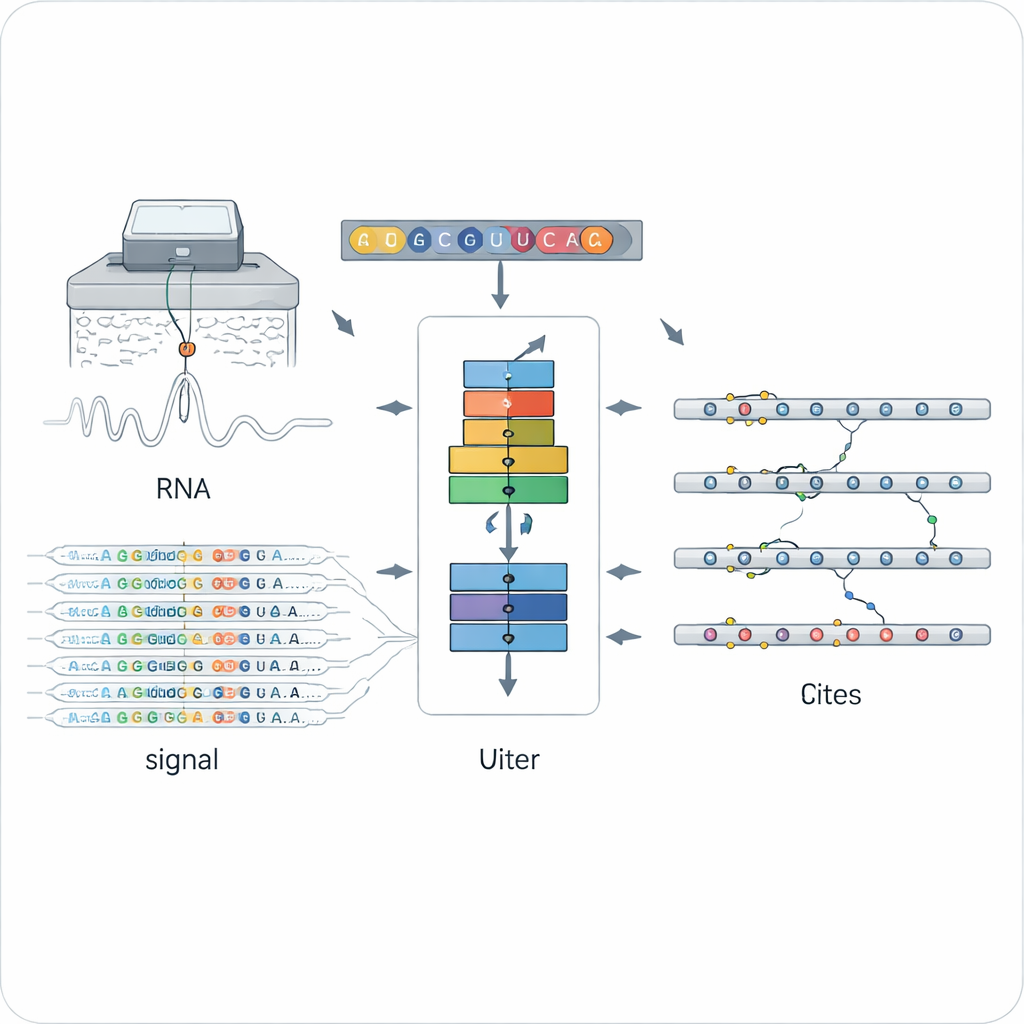
Uma nova maneira de ler marcas químicas no RNA
Os métodos tradicionais para identificar modificações de RNA geralmente dependem de anticorpos específicos ou de reações químicas voltadas a um único tipo de marca, como a popular N6‑metiladenosina (m6A). Isso os torna poderosos, porém estreitos: cada técnica detecta apenas um tipo de marca, muitas vezes em um único contexto experimental. O sequenciamento direto de RNA por nanoporo abriu outra possibilidade ao puxar moléculas individuais de RNA através de um poro minúsculo e medir mudanças na corrente elétrica que dependem da estrutura química exata de cada base. Letras modificadas e não modificadas distorcem o sinal e o processo de chamada de bases de maneiras sutilmente diferentes, mas interpretar esses dados ruidosos e de alta dimensionalidade em vários tipos de modificação tem sido um grande desafio.
Treinando uma rede neural para detectar qualquer marca
O ORCA (Omni‑RNA modification Characterization and Annotation) enfrenta esse desafio em duas etapas. Primeiro, foca numa pequena janela em torno de cada posição do RNA e agrega tanto o sinal elétrico bruto quanto o padrão de erros de sequenciamento ao longo de muitas leituras. Como apenas uma fração das cópias de RNA carrega uma dada marca, sítios realmente modificados mostram distribuições de sinal mais enviesadas e erros de chamada de base mais frequentes nessa posição. O ORCA usa uma rede neural recorrente profunda treinada com uma estratégia “adversarial” para aprender padrões gerais que distinguem sítios modificados de não modificados, sem se prender a um único tipo químico conhecido. Isso permite ao ORCA atribuir a cada sítio uma pontuação de modificação e uma estimativa da fração de moléculas modificadas.
Aprendendo a identidade de cada marca
Na segunda etapa, o ORCA aprende a rotular qual tipo de marca química está presente. Os autores alimentam o modelo com um conjunto de sítios de alta confiança de bancos de dados públicos, onde experimentos convencionais já identificaram m6A, 5‑metilcitosina (m5C), pseudouridina (Ψ), inosina, 2′‑O‑metilação e várias marcas mais raras. O ORCA comprime os padrões de sinal, o contexto de sequência e pequenos “motivos” de sequência ao redor de cada sítio em um mapa de dimensionalidade reduzida, então ajusta‑se finamente para prever o tipo de modificação e a base exata onde ela ocorre. Crucialmente, sítios não rotulados também são usados como exemplos de “fundo”, o que ajuda o modelo a evitar forçar marcas desconhecidas em categorias incorretas. Uma vez treinado, o ORCA pode transferir esses rótulos aprendidos para dezenas de milhares de sítios anteriormente não anotados no transcritoma.
Vendo muitas modificações ao mesmo tempo
Ao aplicar o ORCA a células humanas e de camundongo, os autores mostram que ele não apenas iguala ou supera a precisão de ferramentas líderes para marcas específicas como m6A, m5C e Ψ, mas também pode detectar marcas para as quais não foi explicitamente treinado. Por exemplo, mesmo quando os dados de m6A foram omitidos durante o treinamento, o ORCA recuperou a maioria dos sítios de m6A medidos independentemente e os distinguiu corretamente de motivos de sequência semelhantes que não são modificados. Fez o mesmo para grupos 2′‑O‑metil, sítios de edição por inosina e uma grande variedade de alterações químicas em RNA ribossômico, incluindo muitas modificações raras detectadas por espectrometria de massa. No geral, o ORCA amplia muito o catálago conhecido de sítios de modificação de RNA, com aumentos múltiplos em anotações de m5C, Ψ, m7G e outras marcas de baixa abundância em comparação com bancos de dados existentes.
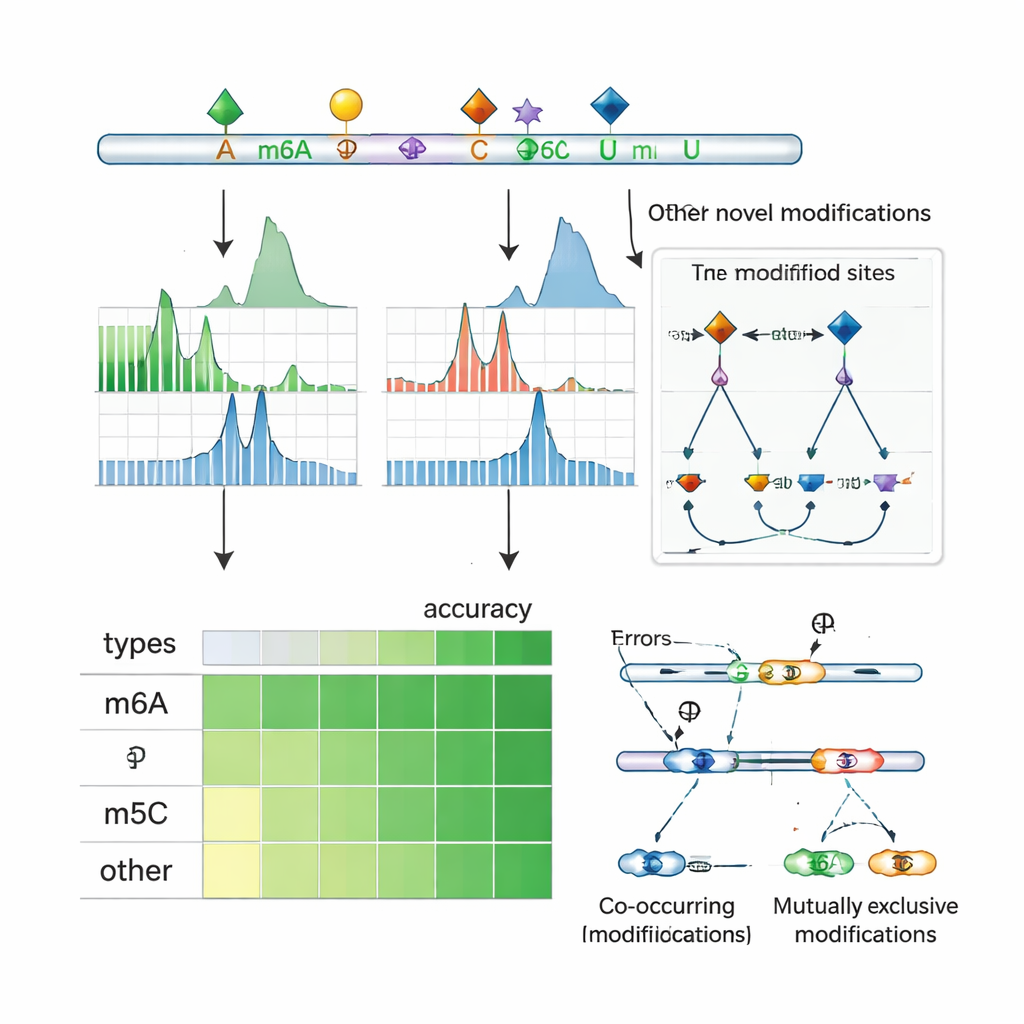
Revelando interação entre marcas e controle do splicing
Porque o sequenciamento por nanoporo lê moléculas inteiras de RNA, o ORCA pode examinar quais marcas aparecem juntas no mesmo transcrito e quais tendem a se excluir mutuamente. Os autores agrupam marcas próximas ao longo dos RNAs e usam um modelo probabilístico para inferir se pares de sítios são frequentemente co‑modificados ou mutuamente exclusivos em moléculas individuais. Eles encontram ocorrência frequente de m6A junto com m5C e outras marcas, assim como muitas regiões onde um sítio é modificado apenas quando o sítio vizinho não o é. Em linhagens celulares humanas, esses padrões frequentemente ocorrem próximos a éxons que são alternativamente incluídos ou pulados, e se sobrepõem a sítios de ligação de reguladores de splicing e proteínas “leitoras” que reconhecem RNA modificado. Em genes específicos, o ORCA revela que determinadas variantes de splicing são enriquecidas por um padrão de marcas, enquanto variantes alternativas apresentam outro padrão, conectando a decoração química local do RNA à forma como as mensagens são cortadas e costuradas.
Por que isso importa para a biologia e a medicina
Ao combinar sequenciamento direto de RNA com aprendizado profundo flexível, o ORCA transforma um sinal elétrico complexo em um mapa rico e em múltiplas camadas de marcas químicas pelo transcritoma. Para não especialistas, o resultado principal é que os cientistas agora podem ver não apenas onde ocorrem modificações individuais de RNA, mas quantas marcas diferentes decoram a mesma molécula e como essas combinações se relacionam com a regulação gênica, especialmente o splicing do RNA. Essa estrutura torna possível estudar a “epigenética” do RNA em muitos tipos celulares e condições sem precisar projetar um novo experimento para cada marca, abrindo caminho para descobertas sobre como esses pequenos ajustes químicos contribuem para o desenvolvimento, função cerebral e doenças como câncer e transtornos neurológicos.
Citação: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Palavras-chave: Modificações de RNA, sequenciamento por nanoporo, aprendizado profundo, epitranscritoma, splicing alternativo