Clear Sky Science · pt
Estimativa e edição neural de iluminação a partir de vista única para exibição dinâmica de campo de luz
Por que seu mundo virtual deve combinar com sua sala de estar
Qualquer pessoa que já usou um headset de realidade virtual ou mista já notou: um objeto digital que parece deslocado, com iluminação e sombras que não combinam com o ambiente real. Este artigo aborda esse problema. Os autores apresentam um método para que headsets “compreendam” a iluminação do seu ambiente real a partir de apenas uma visão de câmera, e então usem esse conhecimento para fazer objetos virtuais parecerem realmente parte do seu mundo — sem sondas de luz especiais, capturas elaboradas ou recálculos pesados.
Tornar a luz no espaço mais fácil de manejar
Em física e computação gráfica, a aparência de uma cena é governada pelo seu “campo de luz” completo: todos os raios de luz fluindo pelo espaço em todas as direções. Reconstruir esse campo exatamente normalmente exige muitos dados, com várias imagens e medições cuidadosas. Técnicas 3D modernas, como campos de radiância neurais, podem armazenar cenas em redes neurais, mas tipicamente “assam” a iluminação presente durante a captura. Isso significa que a cena virtual fica correta apenas sob aquelas condições originais e se desfaz quando a iluminação do ambiente real muda. Os autores procuram romper essa limitação encontrando uma descrição compacta da iluminação do mundo real a partir de dados mínimos, e então usá-la para reiluminar flexivelmente uma cena 3D neural.
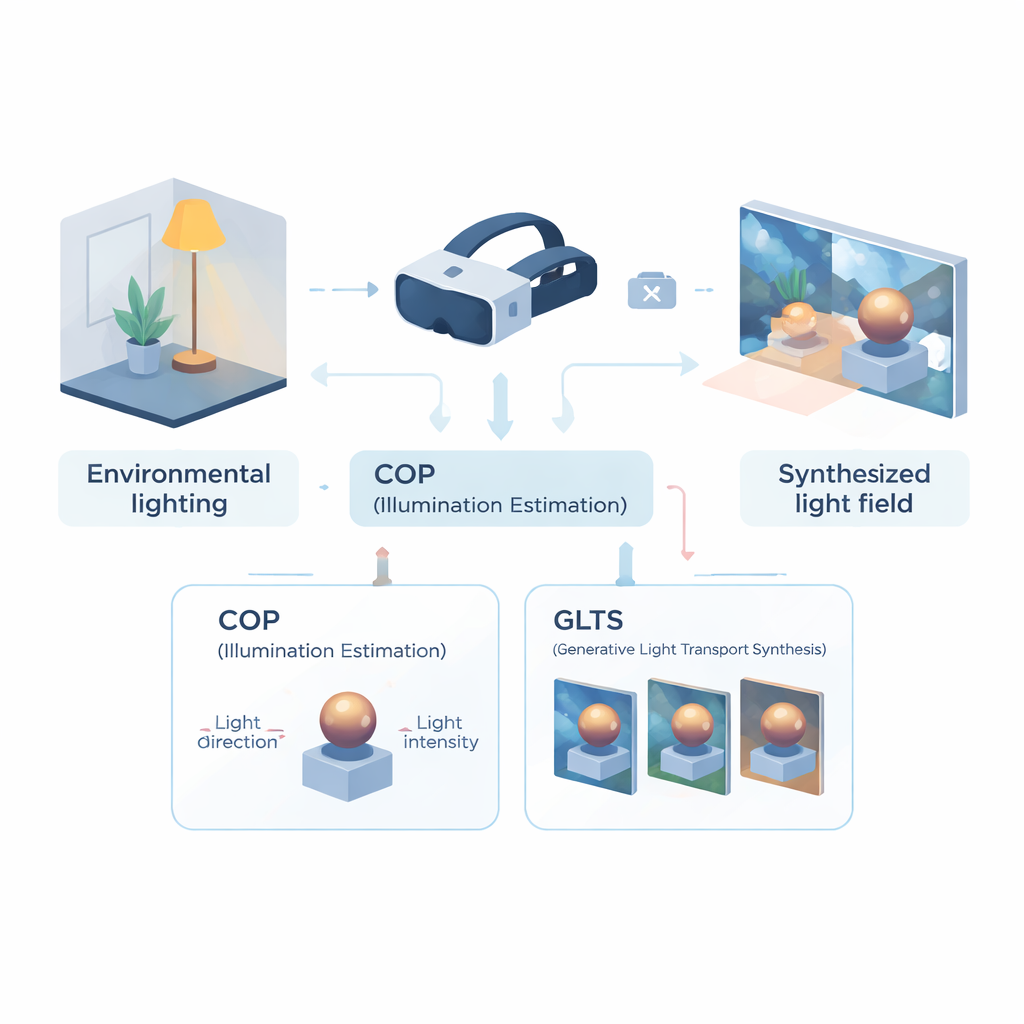
Ensinando um headset a ler a sala
A primeira parte do sistema é um módulo de percepção óptica computacional (COP), projetado para ler a iluminação a partir de uma única vista de câmera. Em vez de reconstruir todo o campo de luz, o COP foca na fonte de luz dominante: sua direção e intensidade. Uma rede neural multiescala varre a imagem de entrada em busca de pistas físicas — reflexos brilhantes, gradientes de sombreamento e sombras — enquanto uma etapa especial de interpolação corrige a forma não linear como as câmeras comprimem o brilho. Isso produz estimativas numéricas de intensidade e direção da luz que são mais fiéis à energia real na cena. Uma segunda etapa, chamada intérprete semântico, refina esses números e gera uma descrição curta e textual da iluminação (por exemplo, que a luz vem de cima e da direita). Essa combinação de números e palavras torna a estimativa mais estável e mais fácil de usar nas etapas seguintes.
Pintando novamente objetos com nova luz
Munido dessa descrição compacta da iluminação, o segundo módulo — síntese generativa de transporte de luz (GLTS) — assume o controle. O GLTS parte de uma representação 3D neural existente de um objeto ou cena, renderizada uma vez sob sua iluminação antiga, incorporada. Guiada pela direção inferida da luz, intensidade e pela descrição textual, uma rede generativa “repinta” essa vista para que realces e sombras combinem com o novo ambiente. Para manter o resultado tanto realista quanto específico ao objeto, o GLTS mistura dois tipos de orientação: controle global a partir dos parâmetros de iluminação e detalhes finos extraídos diretamente da imagem observada. Por meio de um processo de treino especializado que se concentra apenas em como um único objeto responde a diferentes iluminações, o modelo aprende a deslocar reflexos e a suavizar bordas de sombra de maneiras fisicamente plausíveis, em vez de simplesmente aplicar um filtro de estilo genérico.
Construindo um campo de luz 3D consistente a partir de muitas vistas
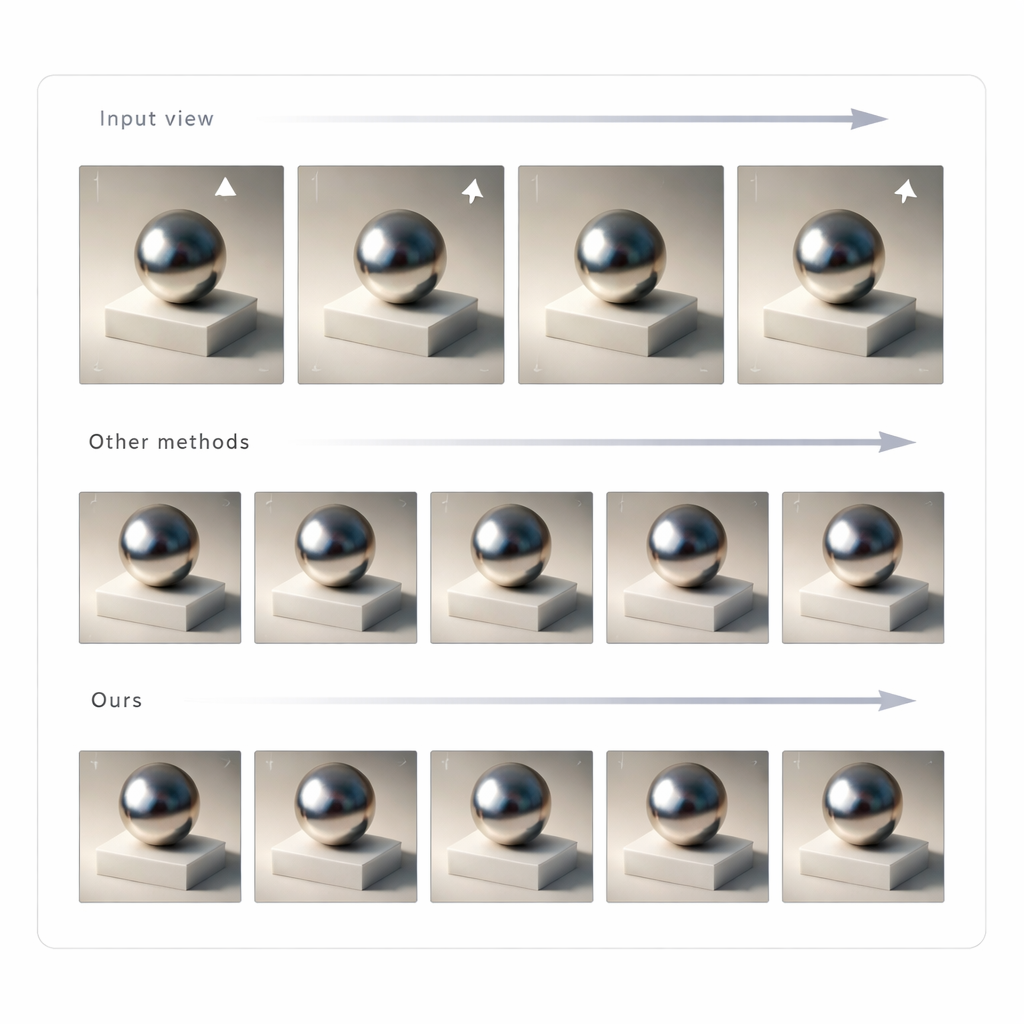
Mudar uma única imagem não basta para realidade mista convincente; a iluminação precisa permanecer consistente conforme você move a cabeça. Para conseguir isso, os autores usam o GLTS para gerar um conjunto de imagens reiluminadas a partir de muitas vistas e então tratam essas imagens como alvos para reconstruir a cena 3D. Um processo de otimização conjunta ajusta simultaneamente a representação 3D neural e as posições das câmeras virtuais de modo que renderizar o novo modelo reproduza todas as vistas sintetizadas. Essa etapa corrige distorções sutis introduzidas pela rede generativa e produz um ativo 3D coerente cuja aparência permanece estável e crível de qualquer ângulo. A equipe testou seu método contra várias abordagens de reiluminação de ponta e constatou que ele entregou maior concordância com imagens de referência e sombras e reflexos mais naturais, conforme avaliado tanto por métricas em nível de pixel quanto por métricas baseadas na percepção.
O que isso significa para headsets futuros
Para não especialistas, a principal conclusão é que este trabalho mostra como dispositivos futuros de VR, AR e realidade mista podem adaptar conteúdo virtual à iluminação do mundo real com apenas um rápido olhar pela câmera do headset. Em vez de montagens de captura trabalhosas ou de treinar modelos sob medida para cada cena nova, o sistema estima as condições principais de iluminação, regenera como a cena deve parecer nessas condições e reconstrói uma representação 3D consistente. O resultado são objetos virtuais cujo brilho, brilho de superfície e sombras respondem ao seu ambiente de forma semelhante a objetos reais, abrindo caminho para experiências de realidade mista que parecem menos gráficos sobrepostos e mais adições genuínas ao mundo físico.
Citação: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Palavras-chave: iluminação em realidade mista, campos de luz neurais, reiluminação a partir de vista única, displays de realidade virtual, imagem computacional