Clear Sky Science · pt
Identificação de informações visuais e Q&A de herdeiros do patrimônio cultural imaterial usando um framework aprimorado de Graph-Retrieval
Levando Tradições Ocultas para a Era Digital
Em toda a China, mestres de ópera tradicional, recorte de papel, teatro de sombras e outras artes vivas preservam habilidades transmitidas por gerações. Ainda assim, grande parte do que sabemos sobre esses herdeiros existe apenas em arquivos e imagens dispersas online, tornando difícil para o público — ou mesmo para pesquisadores — encontrar informações confiáveis. Este artigo apresenta um novo framework computacional que lê automaticamente os “cartões-visuais” dos herdeiros do patrimônio cultural imaterial (PCI) e, em seguida, usa modelos de linguagem avançados para responder perguntas e gerar relatórios legíveis sobre eles.
De Cartões Ilustrados a Conhecimento Estruturado
Muitas instituições culturais agora publicam cartões digitais que combinam texto, layout e gráficos simples para apresentar cada herdeiro: nome, ofício, localização, biografia e mais. Humanos conseguem percorrê-los rapidamente, mas computadores têm dificuldade porque os cartões vêm de muitas regiões, usam designs diferentes e frequentemente contêm texto faltante ou danificado. Os autores constroem um grande conjunto de dados com 5.237 desses cartões para herdeiros do PCI chinês, cada um cuidadosamente rotulado com dez tipos de informação-chave, como número do projeto, nome do projeto, região, gênero, unidade de trabalho e uma breve descrição. Eles primeiro usam reconhecimento óptico de caracteres (OCR) para ler o texto e registrar onde cada trecho aparece no cartão, e então empregam grandes modelos de linguagem para ajudar a padronizar os rótulos antes de especialistas humanos os verificarem.
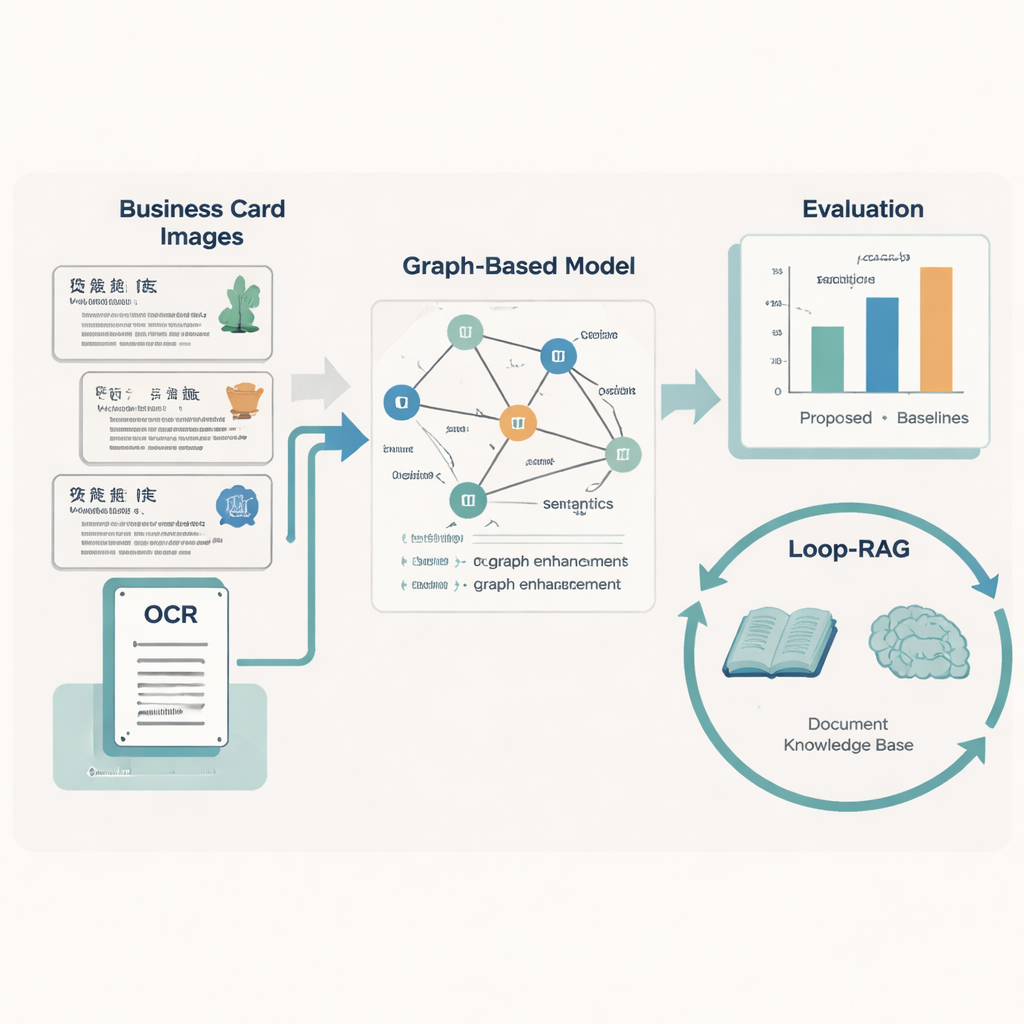
Ensinando Máquinas a Ler Layout e Significado
Para transformar cada cartão em dados limpos e estruturados, a equipe projeta um modelo “Graph-Retrieval” que imita como as pessoas usam tanto palavras quanto o layout. Cada fragmento de texto no cartão torna-se um nó em um grafo, e as relações espaciais entre fragmentos — esquerda, direita, acima, abaixo — formam as arestas. Um componente de linguagem baseado em RoBERTa e um LSTM bidirecional aprende o significado do texto, apoiado por um dicionário personalizado com quase 5.000 termos específicos do PCI para que nomes de ofícios incomuns ou expressões locais sejam tratados corretamente. Sobre isso, uma rede neural de grafos propaga informação entre nós vizinhos, melhorando as previsões sobre o que cada fragmento de texto representa (por exemplo, decidir se um topônimo é uma região ou uma unidade de trabalho).
Tornando o Sistema Robusto à Desordem do Mundo Real
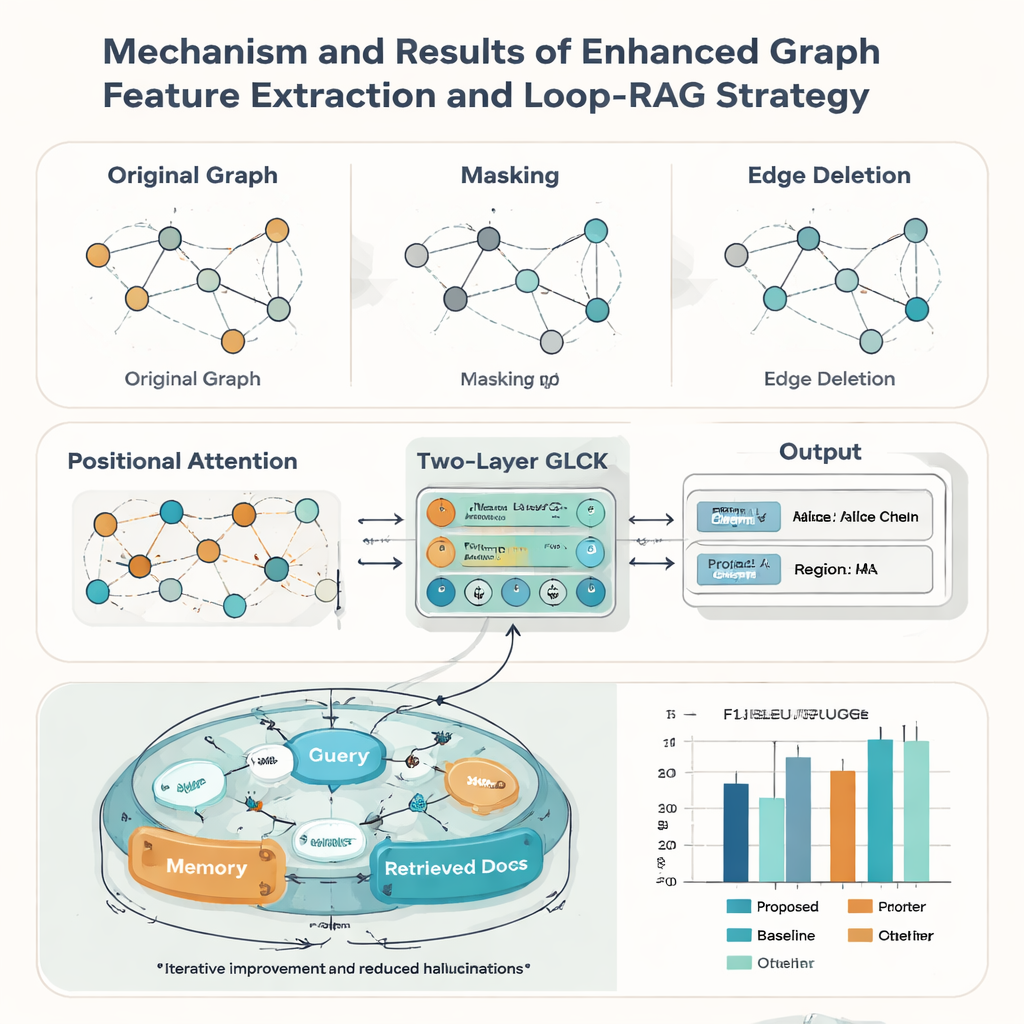
Registros patrimoniais raramente são perfeitos: cartões podem estar gastos, recortados ou mal digitalizados. Para lidar com isso, os autores fortalecem seu modelo de grafo com três ideias emprestadas de aumento de dados. Eles mascaram aleatoriamente alguns nós para que o sistema aprenda a inferir informações faltantes a partir do contexto; deletam aleatoriamente algumas arestas para que ele tolere variações no layout; e adicionam um mecanismo de atenção posicional que captura a “ordem de leitura” geral dos elementos no cartão. Juntos, esses truques ajudam o modelo a generalizar para muitos estilos e qualidades de documento. Em testes contra nove métodos concorrentes bem conhecidos, a nova abordagem alcança a maior pontuação F1 macro-média (0,928) no conjunto de cartões do PCI e também lidera em cinco benchmarks públicos de documentos, sugerindo que é amplamente útil além das aplicações de patrimônio.
Resposta a Perguntas Mais Inteligente com Recuperação em Loop
Reconhecer o texto é apenas metade da história; a segunda contribuição do artigo é uma estratégia Loop-RAG (Loop Retrieval-Augmented Generation) que funciona com grandes modelos de linguagem como GPT-4, Llama e ChatGLM. Sistemas tradicionais aumentados por recuperação buscam documentos de contexto uma vez e então geram uma resposta, que ainda pode ficar incompleta ou errada. Em contraste, Loop-RAG adiciona um loop interno que verifica repetidamente se o modelo de linguagem tem informação suficiente para a resposta atual e, se não, dispara outra busca direcionada em uma base de conhecimento vetorizada do PCI. Um loop externo então analisa muitas interações passadas para aprender quais caminhos de recuperação e estilos de prompt funcionam melhor, reduzindo gradualmente buscas desperdiçadas e erros factuais.
De Registros Brutos a Narrativas Culturais Confiáveis
Usando esse framework combinado, o sistema pode criar automaticamente relatórios curtos sobre um herdeiro — resumindo seu ofício, região, obras representativas e status — e responder milhares de perguntas factuais sobre pessoas e práticas. Medido por scores padrão de qualidade de linguagem como BLEU, METEOR e ROUGE, Loop-RAG com GPT-4 supera tanto modelos de linguagem puros quanto configurações de recuperação mais simples, ao mesmo tempo em que atinge a melhor precisão (F1 até 0,941) em perguntas e respostas, mesmo quando são fornecidos apenas poucos exemplos. Para um leitor leigo, isso significa que futuras plataformas de patrimônio cultural poderão oferecer explicações interativas e confiáveis sobre artes tradicionais sob demanda, transformando registros digitais dispersos em histórias ricas e navegáveis que ajudam a manter as tradições vivas visíveis e valorizadas.
Citação: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Palavras-chave: patrimônio cultural imaterial, extração de informação, redes neurais de grafos, geração aumentada por recuperação, humanidades digitais