Clear Sky Science · pt
Reconstrução 3D de alta fidelidade do patrimônio cultural via super‑resolução e Gaussian splatting progressivo
Por que relíquias digitais mais nítidas importam
Museus e arqueólogos ao redor do mundo correm para criar cópias 3D fiéis de artefatos frágeis, de vasos de porcelana a portais de templos. Esses equivalentes digitais nos permitem estudar, compartilhar e preservar tesouros culturais sem tocar os originais. Mas, no mundo real, fotos de objetos do patrimônio frequentemente são escuras, borradas ou feitas de ângulos inadequados, o que pode levar os métodos atuais de reconstrução 3D a produzir modelos deformados ou incompletos. Este artigo apresenta uma nova abordagem que enfrenta esse problema diretamente, tanto limpando as fotos de entrada quanto estabilizando o processo de modelagem 3D.
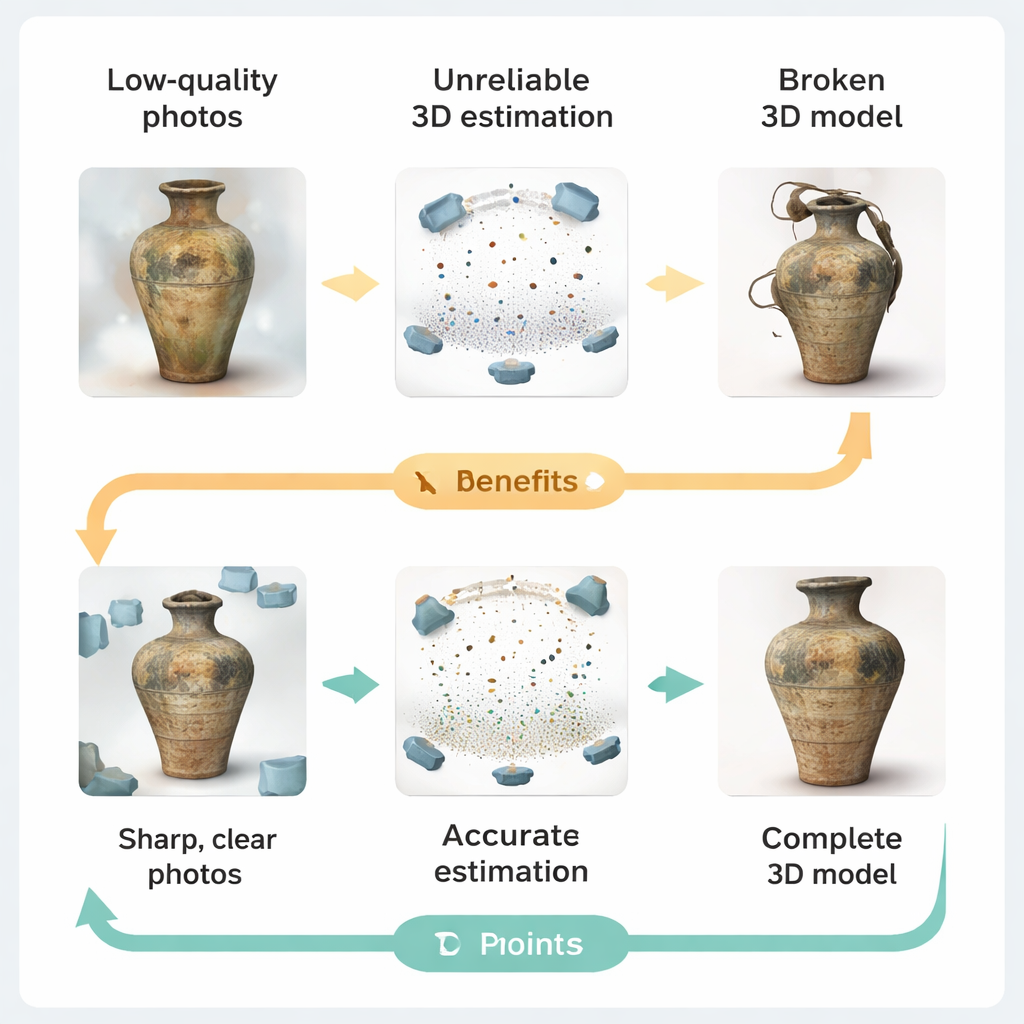
Quando fotos ruins quebram modelos 3D
Os fluxos de captura 3D atuais tipicamente seguem uma ideia simples: tirar muitas fotos, estimar onde cada câmera estava, inferir a forma do objeto e, finalmente, renderizar um modelo 3D. Na prática, sítios de patrimônio raramente oferecem condições de estúdio. Pouca luz, superfícies desgastadas ou irregulares, reflexos de vitrines e restrições na posição da câmera degradam as imagens. Os autores mostram como essas falhas se propagam pelo pipeline. Fotos borradas ou de baixa resolução dificultam o software a casar características entre vistas, levando a erros nas poses das câmeras e estimativas de profundidade fragmentadas. Quando essas medições pouco confiáveis alimentam renderizadores modernos de "Gaussian splatting" — sistemas que constroem cenas a partir de milhares de pequenas manchas coloridas — o resultado pode ser otimização instável, manchas redundantes e geometria visivelmente distorcida.
Afiando fotos com aprimoramento de imagem mais inteligente
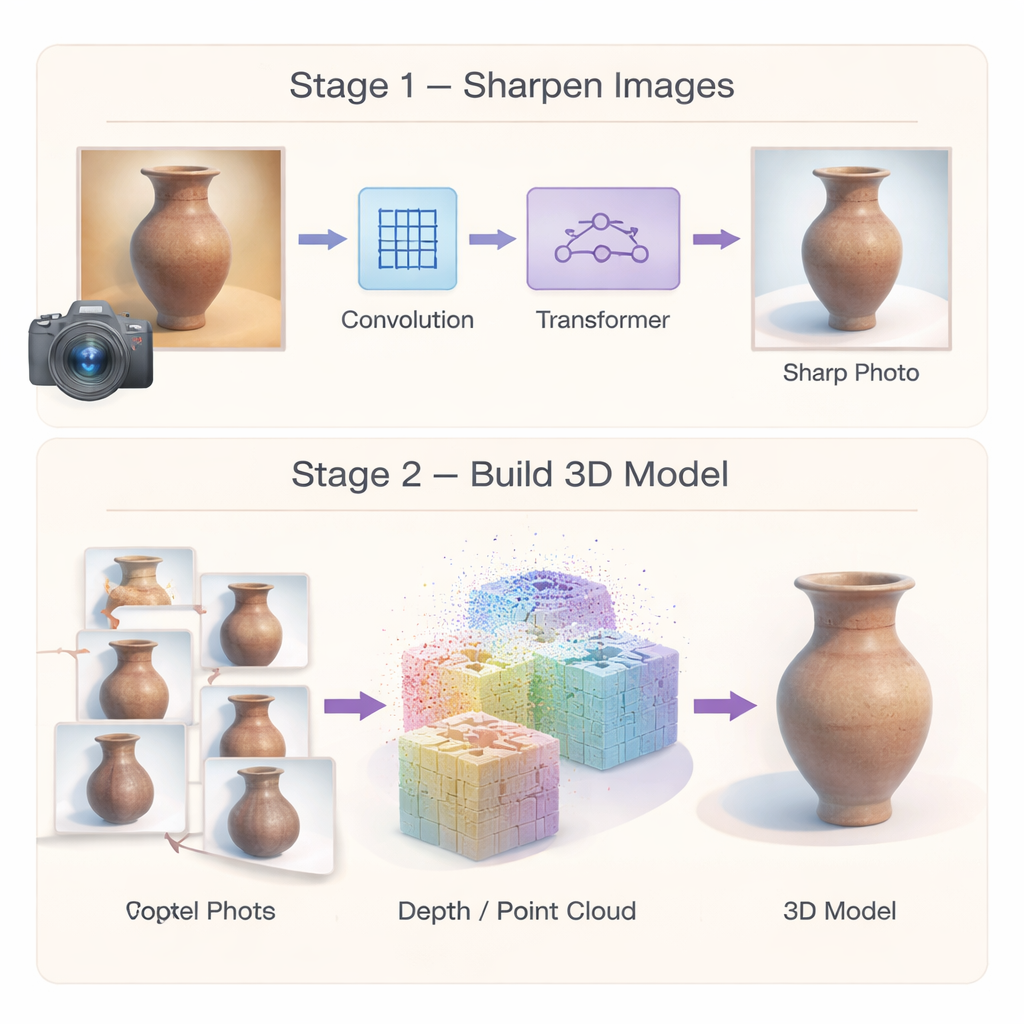
Para conter erros na origem, os autores constroem primeiro uma rede especializada de super‑resolução de imagem que transforma fotos de patrimônio de baixa qualidade em imagens mais nítidas e detalhadas. Em vez de depender de um único tipo de processamento, a rede combina duas forças. Um módulo convolucional multiescala foca em detalhes locais — como trincas, pinceladas ou linhas entalhadas — ao observar a imagem em vários tamanhos de vizinhança ao mesmo tempo. Um módulo Transformer eficiente captura então padrões mais amplos, como motivos repetitivos ou curvas longas que percorrem um objeto. Um terceiro componente reforça seletivamente regiões genuinamente semelhantes na imagem enquanto suprime o ruído, de modo que texturas fracas sejam clarificadas em vez de borradas. Juntos, esses elementos produzem imagens de alta resolução que preservam tanto o ornamento fino quanto a estrutura global, oferecendo às etapas 3D subsequentes um ponto de partida muito melhor.
Construindo formas 3D mais estáveis a partir de muitas vistas
Imagens melhores por si só não bastam; a própria reconstrução 3D também deve ser robusta. A segunda parte do framework repensa como o modelo 3D é inicializado e otimizado. Em vez de confiar em um conjunto esparso de pontos casados, os autores usam um método de correspondência "densa" que produz nuvens de pontos ricas e poses de câmera mais confiáveis desde o início. Esses pontos densos atuam como um esqueleto geométrico robusto para a cena. Sobre isso, eles introduzem uma representação híbrida: o espaço ao redor do artefato é dividido em células 3D grossas, e um decodificador compartilhado prevê a cor e a forma detalhada de muitas pequenas manchas dentro de cada célula. Como os parâmetros são amplamente compartilhados em vez de duplicados, o método reduz o uso de memória e incentiva superfícies suaves e coerentes, tornando o modelo final menos propenso a ondulações e buracos aleatórios.
Treinamento em etapas suaves em vez de tudo de uma vez
Os autores também mudam como o sistema é treinado. Em vez de forçar o modelo a corresponder tanto a aparência quanto a geometria desde o início — uma receita para ficar preso em soluções ruins — eles adotam uma estratégia em três etapas. Primeiro, o sistema aprende apenas a reproduzir as cores das fotos de entrada, assegurando consistência visual global. Em seguida, adiciona gradualmente informação de profundidade derivada das nuvens de pontos densas, que guia o modelo em direção a superfícies plausíveis. Na etapa final, refina detalhes em pequena escala impondo consistência entre patches de imagem sobrepostos de diferentes vistas. Testado em um novo conjunto de dados de Relíquias Culturais com porcelana, móveis, artesanatos e têxteis, bem como em um benchmark padrão de cenas externas complexas, essa abordagem em estágios não só melhora a qualidade visual como também reduz o tempo de treinamento e o uso de memória em comparação com as alternativas líderes.
O que isso significa para preservar o passado
Para não especialistas, a mensagem central é direta: esse framework ajuda a transformar fotografias imperfeitas de museus ou de campo em réplicas 3D mais limpas e precisas de objetos do patrimônio cultural, sem tocá‑los fisicamente. Ao aprimorar imagens de baixa qualidade, começar a partir de um esqueleto geométrico mais sólido e treinar o modelo 3D em estágios cuidadosamente controlados, o método produz artefatos digitais que capturam melhor a decoração fina e a forma geral enquanto usam menos recursos computacionais. Em termos práticos, isso facilita para museus, conservadores e pesquisadores construir coleções virtuais confiáveis a partir de sessões fotográficas ordinárias, ajudando a salvaguardar objetos delicados e a compartilhá‑los amplamente com estudiosos e o público.
Citação: Jia, Q., He, J. High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting. npj Herit. Sci. 14, 84 (2026). https://doi.org/10.1038/s40494-026-02355-4
Palavras-chave: digitalização do patrimônio cultural, reconstrução 3D, super‑resolução de imagem, Gaussian splatting, preservação digital