Clear Sky Science · pt
Geo-TCAM: um método de legendagem de Thangka integrando modelagem de tópicos com atenção espacial guiada por geometria
Arte antiga encontra tecnologia inteligente
Pinturas Thangka — os rolos coloridos vistos em muitos templos tibetanos — estão repletas de pequenos detalhes e camadas de significado religioso. Para visitantes de museus ou espectadores online sem formação especializada, grande parte desse simbolismo é difícil de compreender. Este estudo apresenta o Geo‑TCAM, um sistema de inteligência artificial (IA) projetado para gerar automaticamente descrições ricas e precisas de imagens Thangka, ajudando pessoas ao redor do mundo a entender melhor e preservar esse patrimônio cultural singular.
Por que as imagens Thangka são difíceis para computadores
Diferentemente de fotos do dia a dia, as obras Thangka são deliberadamente densas e simbólicas. Uma única pintura pode conter uma divindade central, dezenas de figuras menores, bordas com padrões e gestos das mãos, objetos, cores e posturas específicas que carregam significado religioso. Programas padrão de legendagem de imagens costumam lidar bem com cenas simples como “um cachorro na praia”, mas aqui eles encontram dificuldades: podem nomear o Buda principal e ainda assim deixar de identificar se ele segura uma tigela ou uma espada, interpretar mal sua postura ou confundi‑lo com outra divindade de aparência parecida. Esses erros não são triviais — podem inverter a história e a doutrina que a pintura pretende transmitir, minando seu valor educativo e cultural.
Um novo projeto para descrever imagens sagradas
Geo‑TCAM resolve esses problemas combinando três ideias: recursos visuais em múltiplos níveis, conhecimento de tópicos sobre a arte Thangka e atenção guiada por geometria para áreas-chave como rostos. Primeiro, usa uma rede profunda (ResNet50) para examinar cada imagem em vários níveis simultaneamente: camadas de nível médio capturam contornos, texturas e formas simples, enquanto camadas mais profundas resumem a composição geral. Ao fundir esses níveis, o modelo pode notar tanto detalhes finos como ornamentos quanto a disposição ampla de figuras e fundos, oferecendo uma compreensão visual mais rica do que sistemas anteriores que se concentravam em uma única camada. 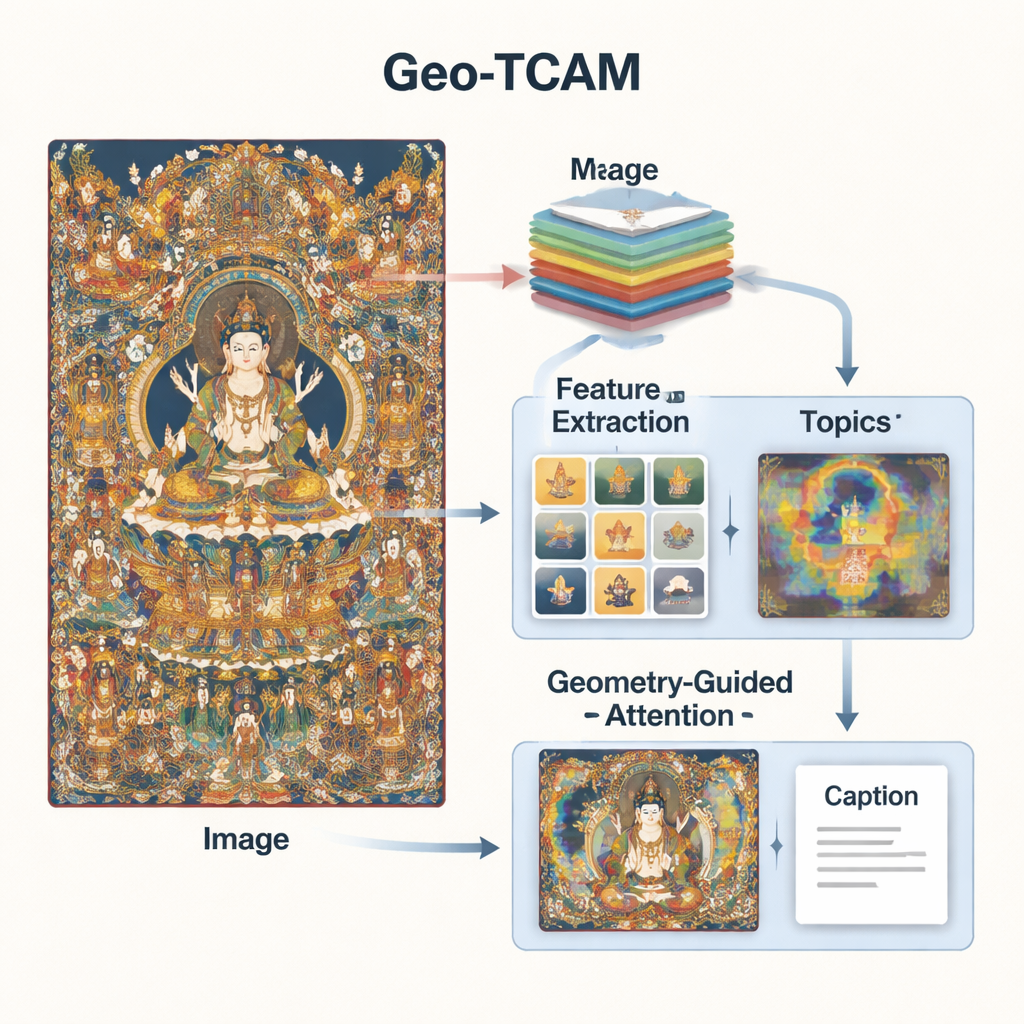
Ensinando ao modelo os “tópicos” Thangka
A visão por si só não basta; o sistema também precisa de algum senso da linguagem e dos temas Thangka. Para isso, os pesquisadores treinaram um modelo de tópicos em milhares de descrições de Thangka escritas por especialistas. Esse modelo agrupa palavras em um punhado de temas comuns — por exemplo, relacionados a Budas, Bodisatvas, tronos de lótus, instrumentos rituais ou divindades protetoras. Para cada nova imagem, o Geo‑TCAM estima quais temas são mais relevantes e mistura essa informação com os recursos visuais. Um mecanismo de atenção então destaca as regiões da imagem que melhor correspondem aos tópicos prováveis. Na prática, o conhecimento prévio sobre quais objetos e símbolos tendem a aparecer juntos direciona a IA para descrições mais significativas e culturalmente informadas.
Deixar a IA “olhar” onde importa mais
A terceira inovação é um módulo de atenção espacial facial guiada por geometria (GFSA). As composições Thangka costumam posicionar o rosto da figura principal em regiões aproximadamente previsíveis da pintura. O Geo‑TCAM usa ferramentas simples de detecção de bordas para localizar essa área e as mãos e a postura ao redor, aplicando então um mecanismo de atenção dedicado que reforça a influência desses pixels na formação da legenda. Essa estratégia de “localizar primeiro, guiar depois” ajuda a evitar a identificação equivocada inicial da divindade central, o que, de outra forma, desencadearia uma cadeia de erros textuais sobre gestos, atributos e status. Mapas de calor visuais mostram que, com o GFSA, o modelo concentra‑se mais claramente no rosto da figura principal e em objetos-chave, sem perder de vista motivos de fundo importantes. 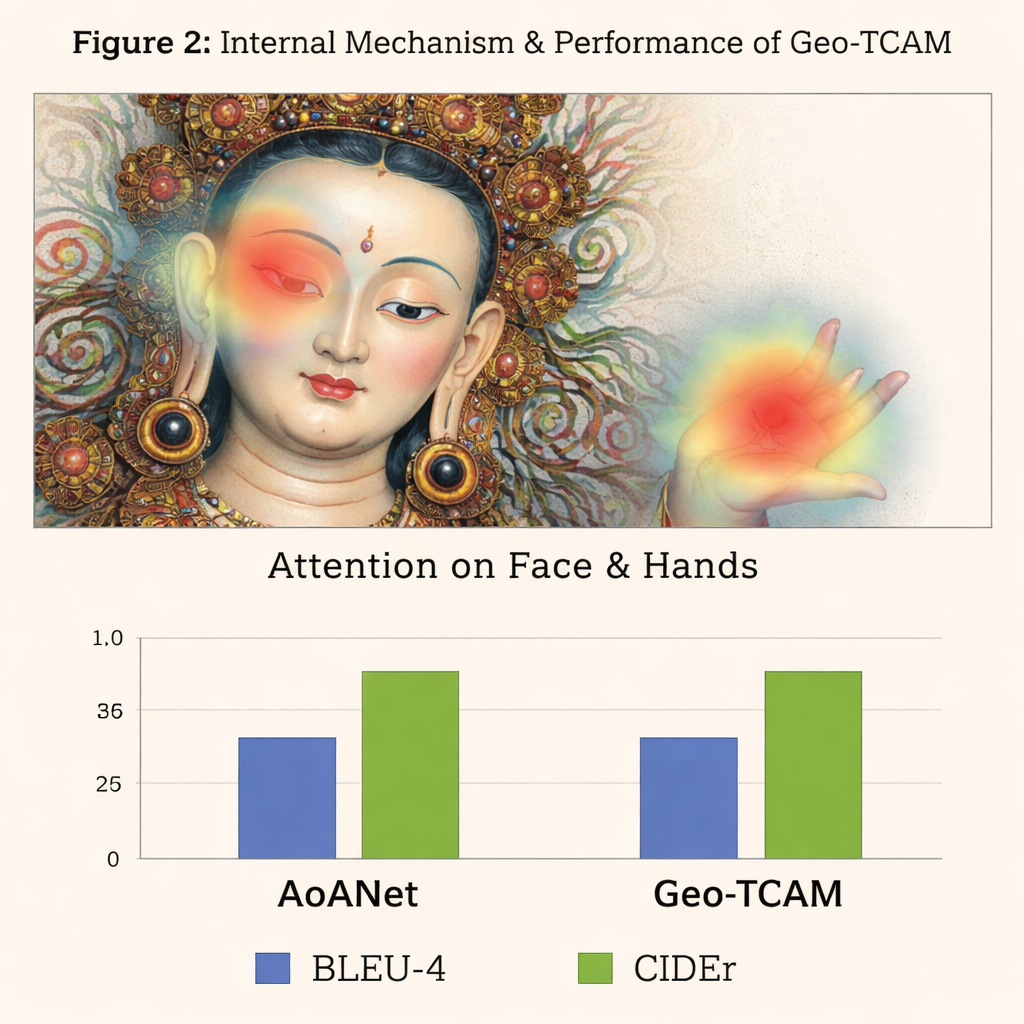
Quão bem o Geo‑TCAM funciona?
Para testar sua abordagem, os autores construíram um conjunto de dados especializado, D‑Thangka, com quase 4.000 imagens cuidadosamente anotadas, cada uma com descrições detalhadas de especialistas. Nesse conjunto, o Geo‑TCAM superou claramente vários sistemas fortes de legendagem, incluindo o popular AoANet e grandes modelos visão–linguagem. Dependendo da métrica, suas pontuações melhoraram em até cerca de 120% em relação à linha de base, e avaliadores humanos preferiram em grande maioria suas legendas por precisão, fluência e riqueza de detalhes. Importante: quando o mesmo modelo foi avaliado em uma coleção padrão de fotos do cotidiano (o conjunto COCO), manteve‑se competitivo com métodos líderes, mostrando que seu projeto é potente e ainda assim de propósito geral.
O que isso significa para o patrimônio e além
Para não especialistas, a principal conclusão é que o Geo‑TCAM pode transformar pinturas Thangka visualmente complexas em narrativas claras e informativas que ressaltam quem está representado, o que está sendo feito e por que esses detalhes importam. Ao combinar análise visual em camadas, tópicos aprendidos a partir de textos de especialistas e atenção especial a rostos e gestos, o sistema alinha suas legendas muito mais de perto com a forma como especialistas humanos interpretam essas obras. A longo prazo, tais ferramentas podem apoiar arquivos digitais, guias de museus e plataformas educacionais, tornando a arte religiosa esotérica mais acessível e ajudando conservadores e estudiosos a documentar e proteger tesouros culturais frágeis.
Citação: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Palavras-chave: Legendagem de imagens Thangka, IA para patrimônio cultural, atenção visual, modelagem de tópicos, preservação de arte