Clear Sky Science · pt
Construção do corpus anotado por classes gramaticais das Vinte e Quatro Histórias, antigo-moderno
Por que as antigas crônicas importam na era da IA
Por mais de dois milênios, historiadores chineses registraram guerras, cortes, fomes e a vida cotidiana na vasta série conhecida como as Vinte e Quatro Histórias. Hoje, esses clássicos estão sendo redescobertos não só por estudiosos, mas por computadores. Este estudo descreve como pesquisadores transformaram essas crônicas antigas e suas traduções para o chinês moderno em um banco de dados linguístico cuidadosamente rotulado. Esse recurso pode ajudar a inteligência artificial a ler, traduzir e analisar textos históricos com maior precisão — e tornar o passado distante muito mais acessível ao público.
De volumes empoeirados a texto digital
O projeto começa com uma tarefa básica, porém intimidadora: transformar milhões de caracteres impressos em texto digital limpo e preciso. A equipe recorreu a duas fontes — uma edição moderna definitiva das Vinte e Quatro Histórias e uma grande coleção online — para alimentar um sistema de reconhecimento óptico de caracteres. Em seguida, eliminaram laboriosamente trechos corrompidos, corrigiram caracteres mal lidos e removeram ruídos como cabeçalhos e rodapés de página. O resultado foi um conjunto paralelo de arquivos, um em chinês antigo e outro em chinês moderno, que correspondiam fielmente aos livros originais, mas estavam prontos para análise computacional. 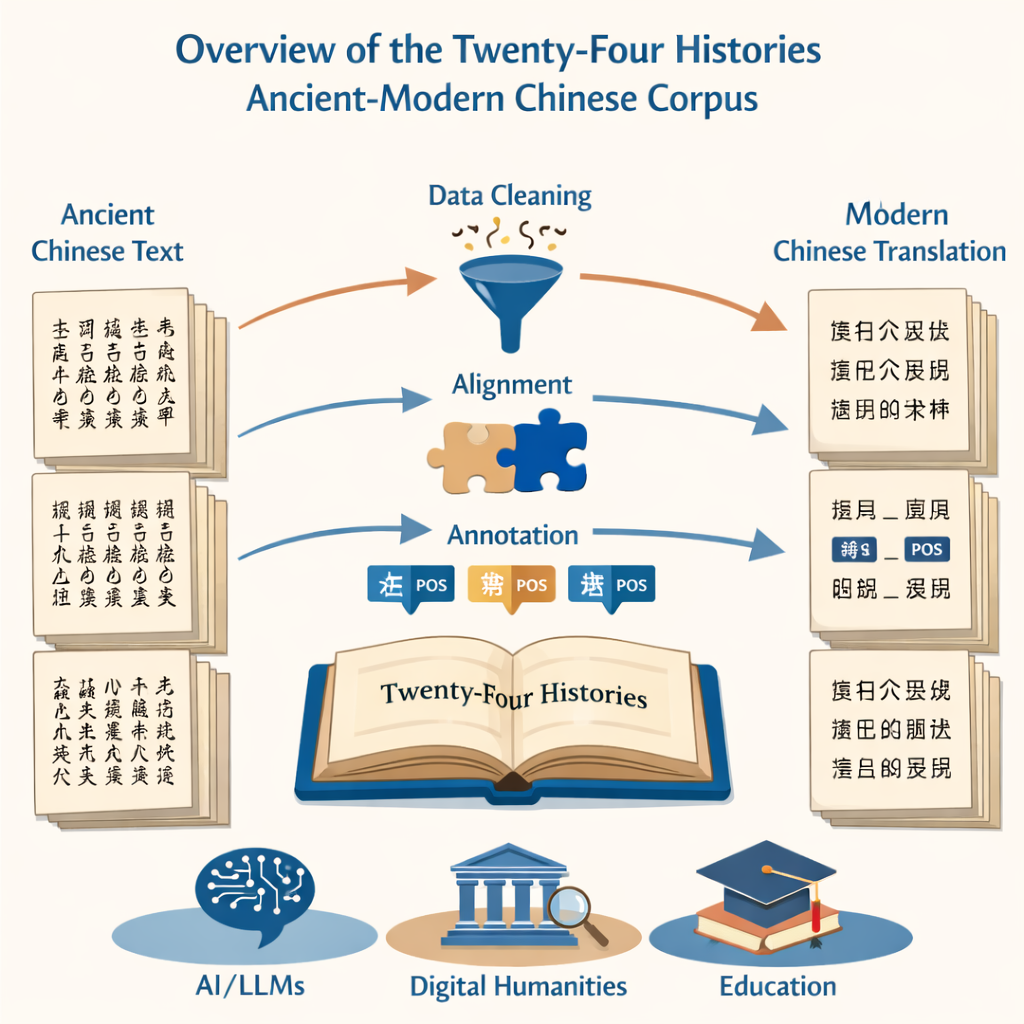
Emparelhando sentenças antigas com modernas
Como o objetivo era comparar como a língua mudou ao longo do tempo, era essencial alinhar as versões antiga e moderna sentença por sentença. Os pesquisadores usaram software especializado de alinhamento para primeiro casar parágrafos e depois dividi-los em sentenças correspondentes. Ferramentas automatizadas fizeram o trabalho pesado, mas especialistas humanos tiveram de revisar cada par sugerido, já que a gramática do chinês antigo pode ser muito diferente do chinês moderno. Onde o software tropeçava — separando um pensamento no lugar errado ou lendo mal um caractere — os anotadores consultavam as páginas escaneadas originais e corrigiam o texto digital para que cada sentença antiga se alinhassse claramente com sua contraparte moderna.
Ensinando computadores a perceberem a gramática
Além da simples transcrição, o núcleo do projeto é a rotulação gramatical. Cada palavra, tanto nos textos antigos quanto nos modernos, foi marcada com uma etiqueta de classe gramatical, indicando se é, por exemplo, um substantivo, verbo ou palavra temporal. Como não existe um padrão único para o chinês antigo, a equipe ancorou seu sistema nas diretrizes nacionais modernas e então as adaptou ao uso mais antigo. Eles criaram um esquema de 22 etiquetas que inclui uma marca especial para usos verbais tipicamente antigos, como “fazer viver” ou “morrer pelo país”. Uma rede neural customizada — construída sobre um modelo de linguagem para textos antigos e camadas de rotulação de sequência — produziu etiquetas iniciais, que foram revisadas e corrigidas por uma grande equipe de estudantes de pós-graduação bem treinados. Testes rigorosos de concordância entre anotadores mostraram consistência muito alta, confirmando que o corpus anotado final é ao mesmo tempo extenso e confiável.
O que a nova lente revela
Com o corpus anotado em mãos, os autores examinaram alguns dos padrões que ele torna visíveis. No chinês antigo, predominam palavras de um único caractere, refletindo um estilo de escrita notoriamente conciso, enquanto o chinês moderno favorece palavras de dois caracteres. Os itens antigos mais comuns são pequenas partículas gramaticais como “之” e “以”, enquanto verbos e substantivos comuns juntos constituem cerca da metade de todas as palavras em ambos os períodos. Os dados também mostram quais palavras tendem a aparecer juntas — por exemplo, estruturas que descrevem oficiais, exércitos ou missões diplomáticas. Comparando etiquetas entre os pares antigo–moderno, a equipe traçou como funções mudaram ao longo do tempo: algumas antigas preposições e advérbios agora correspondem a verbos modernos plenos, e certos verbos se solidificaram em títulos fixos ou termos legais. Um estudo de caso isolou todos os nomes de lugares e mapeou onde eles se concentram em diferentes dinastias, revelando como centros políticos e econômicos se moveram do noroeste para a região do baixo Yangtzé e além. 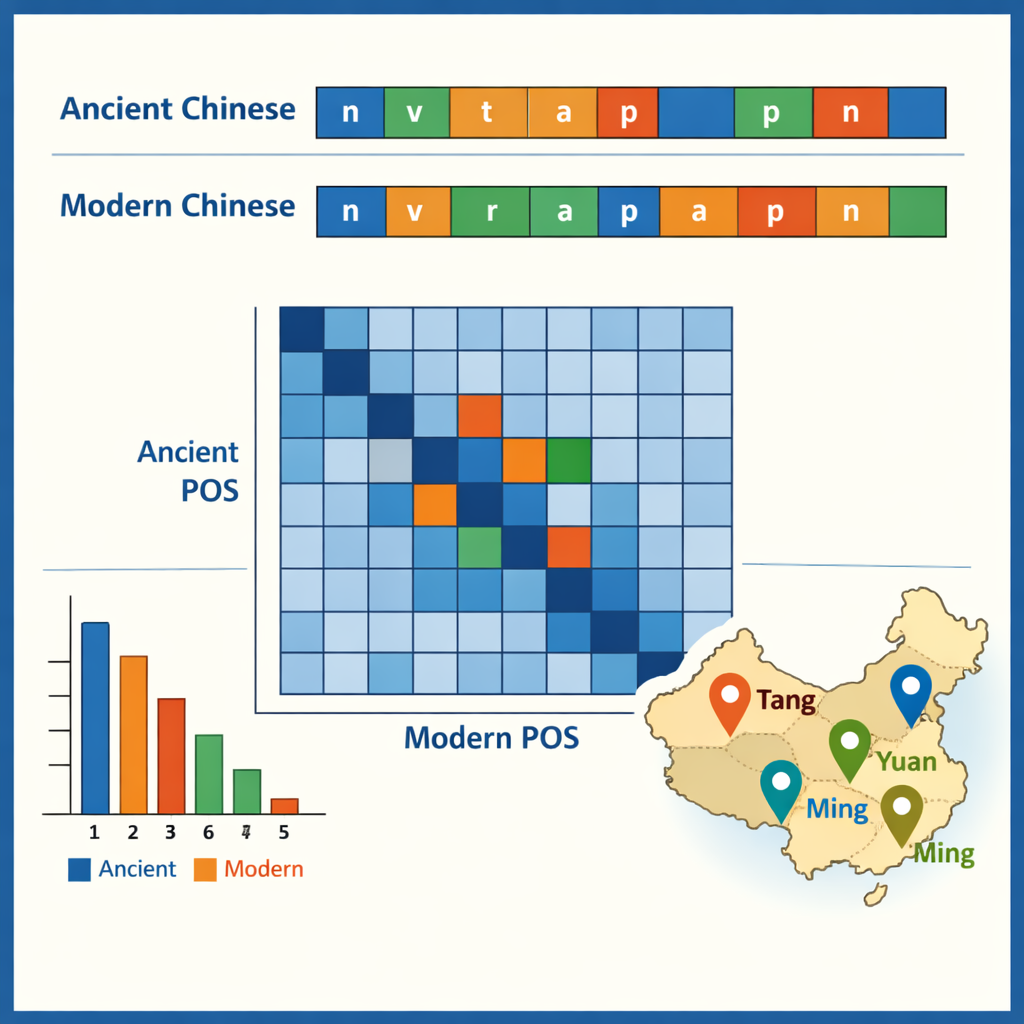
Levando o passado ao futuro digital
Em termos simples, este projeto transforma um imenso muro de prosa clássica em dados estruturados que tanto humanos quanto máquinas podem navegar. Para historiadores e linguistas, fornece uma ferramenta poderosa para rastrear como palavras, gramática e até fronteiras estatais evoluíram ao longo dos séculos. Para desenvolvedores de IA, oferece material de treinamento de alta qualidade para construir modelos de linguagem que realmente lidem com o chinês clássico em vez de tratá‑lo como um amontoado de caracteres. E para estudantes e leitores em geral, o emparelhamento frase a frase do texto antigo e moderno reduz a barreira para ler os clássicos. Ao rotular e alinhar cuidadosamente as Vinte e Quatro Histórias, os autores criaram uma ponte dos rolos manuscritos do passado para os sistemas inteligentes do presente e do futuro.
Citação: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Palavras-chave: corpus do chinês antigo, anotação de classes gramaticais, humanidades digitais, textos paralelos, mudança histórica da linguagem