Clear Sky Science · pl
Systematyczna ocena i wytyczne dla modelu Segment Anything w analizie materiału wideo chirurgicznego
Dlaczego inteligentne narzędzia wideo są ważne na sali operacyjnej
Współczesna chirurgia coraz częściej opiera się na obrazie wideo: małe kamery zaglądają do wnętrza ciała, podczas gdy chirurdzy operują delikatnymi narzędziami, obserwując ekran. Przekształcenie tych bogatych, lecz chaotycznych nagrań w czytelne, oznakowane mapy narzędzi i tkanek może zwiększyć bezpieczeństwo operacji, poprawić szkolenie oraz uczynić przyszłą pomoc robotyczną bardziej niezawodną. W tym badaniu przyjrzano się potężnemu, uniwersalnemu systemowi wizyjnemu, pierwotnie trenowanemu na codziennych wideo, z pytaniem prostym, lecz kluczowym: czy potrafi on „widzieć” wystarczająco dobrze wewnątrz ludzkiego ciała, by być użytecznym w prawdziwej chirurgii — bez konieczności pełnego retrenowania na kosztownych medycznych danych? 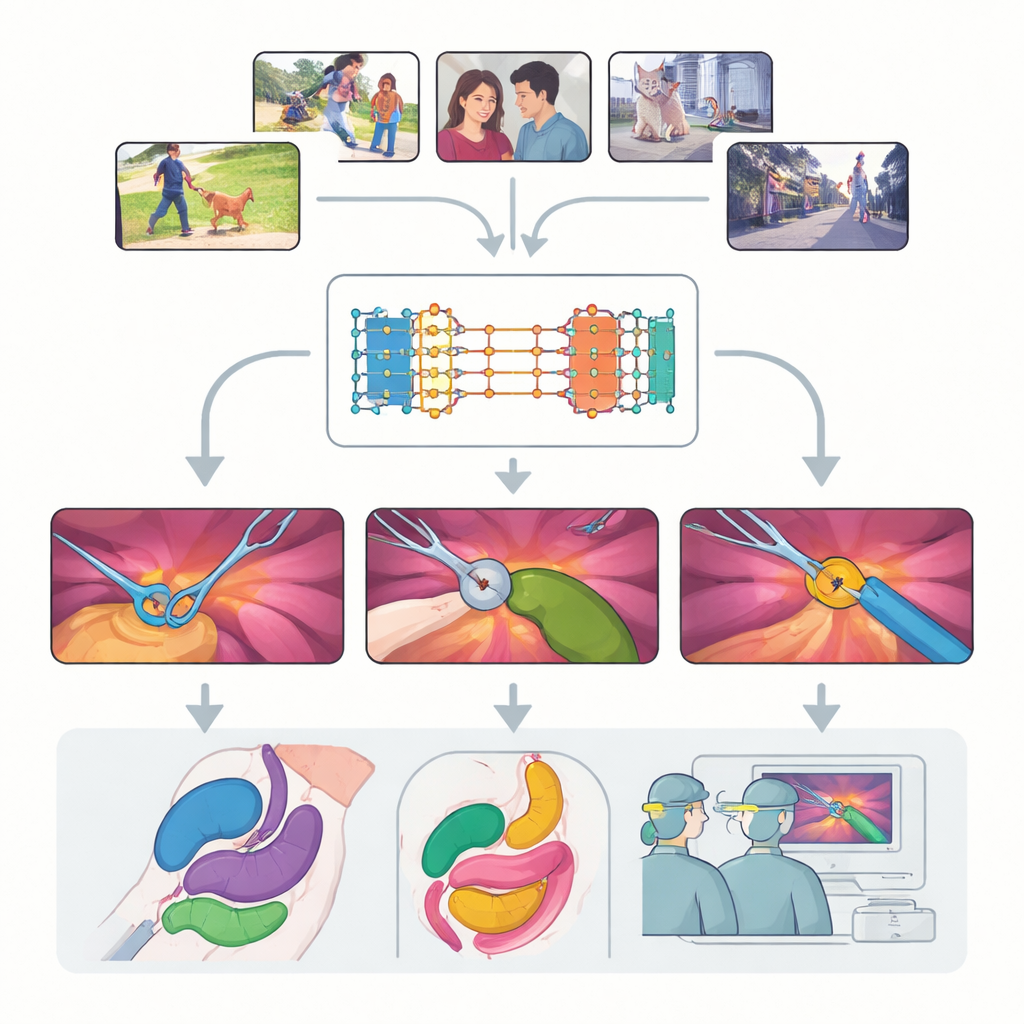
Elastyczne narzędzie wizyjne zaprojektowane dla dowolnej sceny
Praca skupia się na modelu Segment Anything Model 2 (SAM2), dużym systemie AI zaprojektowanym do wyodrębniania obiektów w wideo, gdy tylko otrzyma wskazówkę, czyli „prompt” o tym, czego szukać. W przeciwieństwie do tradycyjnych modeli uczących się określonych kategorii, SAM2 jest niezależny od klas: nie rozróżnia, czy obiekt to pies, samochód czy szczypce chirurgiczne — ważne, aby użytkownik wskazał go kropką, ramką lub przykładową maską. Kluczowym udoskonaleniem w SAM2 jest bank pamięci, który zapamiętuje, jak obiekt wyglądał w wcześniejszych klatkach i wykorzystuje tę pamięć do śledzenia go w czasie. To czyni SAM2 szczególnie obiecującym dla wideo chirurgicznego, gdzie narzędzia chowają się i pojawiają, a tkanki ciągle się odkształcają.
Testowanie modelu na wielu operacjach
Autorzy przeprowadzili szeroko zakrojoną, systematyczną ocenę SAM2 na dziewięciu zróżnicowanych zbiorach danych obejmujących siedemnaście rodzajów procedur, od laparoskopowego usuwania pęcherzyka żółciowego po robotyczną prostatektomię i endoskopię. Badali trzy główne wyzwania: śledzenie narzędzi, segmentację wielu narządów oraz analizę scen łączących narzędzia i tkanki. Dla każdego z nich testowali różne sposoby podpowiadania modelowi — pojedyncze punkty, wiele punktów, ramki ograniczające i pełne maski — oraz badali, jak często trzeba odświeżać podpowiedzi w trakcie odtwarzania wideo. Porównali też model „prosto z pudełka” z kilkoma sposobami lekkiego dopasowania go do obrazów chirurgicznych, aby sprawdzić, jak daleko można zwiększyć wydajność bez potrzeby ogromnych nowych zbiorów danych.
Co działa najlepiej we wnętrzu ciała
Ogólnie SAM2 okazuje się zaskakująco skuteczny w tym nietypowym środowisku. Bez chirurgicznego dopasowywania już potrafi segmentować narzędzia i wiele narządów na poziomie konkurencyjnym wobec specjalistycznych modeli medycznych, zwłaszcza gdy otrzymuje bogate podpowiedzi, takie jak ramki czy maski. Okresowe „reinicjowanie” podpowiedzi co 30 klatek — w praktyce przypomnienie systemowi, co i gdzie się znajduje — znacznie poprawia śledzenie w długich, złożonych nagraniach. Gdy badacze dostrajają tylko wybrane części SAM2, na przykład moduł przekształcający podpowiedzi w maski, dokładność w scenach wielonarządowych rośnie, przy jednoczesnym utrzymaniu umiarkowanych wymagań treningowych. W przeciwieństwie do tego próby dostosowania całego enkodera obrazu przy ograniczonych danych chirurgicznych mogą wręcz pogorszyć wyniki, co sugeruje, że większość ogólnej wiedzy wizualnej SAM2 warto pozostawić nietkniętą. 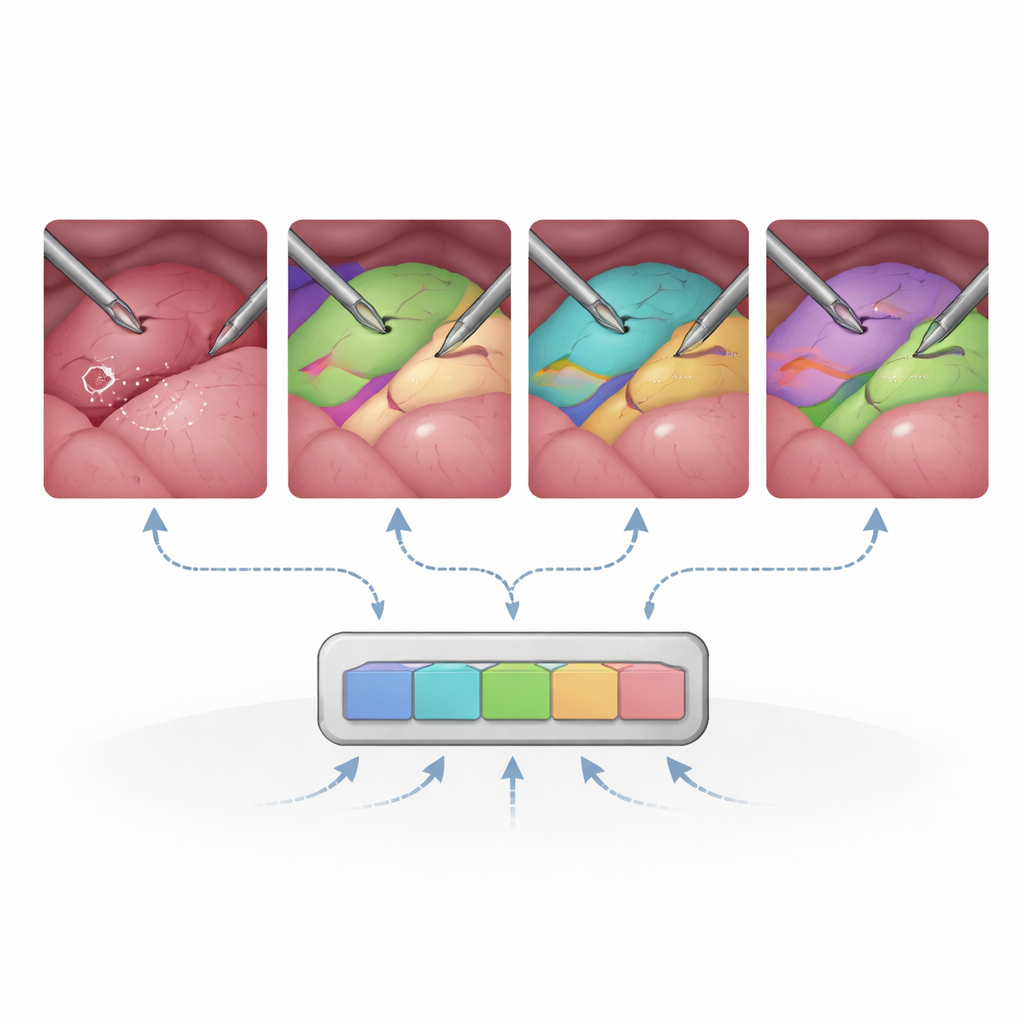
Ograniczenia w chaotycznych, szybko zmieniających się scenach
Badanie ujawnia także wyraźne słabe punkty. SAM2 ma trudności, gdy pole widzenia jest wąskie, obraz jest zaszumiony lub słabo oświetlony, albo gdy tkanki nie mają wyraźnych granic — jak w niektórych procedurach endoskopowych. Cienkie, rozgałęzione struktury, takie jak naczynia krwionośne i przewody, trudno rozdzielić, gdy nakładają się lub mają podobny zarys. Wykorzystanie pamięci wideo nie zawsze pomaga: w bardzo dynamicznych scenach z szybkim ruchem kamery wskazówki czasowe mogą wprowadzać model w błąd zamiast go stabilizować. Te obserwacje podkreślają, że choć model bazowy ogólnego przeznaczenia ma duży potencjał, niektóre realia chirurgiczne wciąż wymagają dopracowania specyficznego dla dziedziny oraz lepszej obsługi zmian ruchu i wyglądu.
Wytyczne dla przyszłych inteligentnych systemów chirurgicznych
Z tej obszernej oceny autorzy wyodrębnili praktyczne wskazówki dla badaczy i klinicystów chcących wykorzystywać SAM2 w projektach chirurgicznych. Zalecają rozpoczęcie od podpowiedzi w postaci masek lub ramek oraz prostego, opartego na obrazach dostrajania koncentrującego się na dekoderze masek, dodanie okresowego odświeżania podpowiedzi w długich nagraniach oraz sięganie po bardziej złożone treningi wideo tylko wtedy, gdy sceny są stosunkowo stabilne. Pokazują też, że nawet rzadko oznakowane klipy — tylko niektóre klatki opisane — mogą wystarczyć do skutecznego dostosowania modelu. Mówiąc wprost: wniosek jest zachęcający — jeden, szeroko wytrenowany model wizyjny może poradzić sobie z wieloma różnymi zadaniami segmentacji chirurgicznej, znacząco zmniejszając potrzebę tworzenia oddzielnych narzędzi dla każdej procedury. Przy przemyślanym promptowaniu i lekkiej personalizacji systemy takie jak SAM2 mogą stać się potężnymi elementami budulcowymi dla następnej generacji nawigacji chirurgicznej, automatyzacji i narzędzi szkoleniowych.
Cytowanie: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
Słowa kluczowe: analiza wideo chirurgicznego, segmentacja obrazu, modele bazowe, chirurgia wspomagana komputerowo, sztuczna inteligencja w medycynie