Clear Sky Science · pl
3D Magic Mirror: rekonstrukcja ubrań z pojedynczego obrazu z perspektywy przyczynowej
Przymierzanie bez przymierzalni
Wyobraź sobie zrobienie jednym telefonem pełnowymiarowego zdjęcia i natychmiastowe zobaczenie siebie w 3D, możliwość obracania obrazu, zmiany perspektyw czy nawet zamiany strojów z przyjacielem. Artykuł rozwiązuje podstawowy problem techniczny stojący za tym „3D Magic Mirror”: przekształcenie zwykłego, dwuwymiarowego zdjęcia osoby w szczegółowy model 3D jej ubrań, bez polegania na kosztownych skanach 3D czy kontrolowanych zdjęciach studyjnych.
Dlaczego przejście z 2D do 3D jest takie trudne
Przekształcenie płaskiego obrazu w obiekt 3D to klasyczna zagadka. Istniejące systemy często zaczynają od stałego cyfrowego szablonu ciała i dopasowują go do zdjęcia. To działa dość dobrze dla sztywnych części ciała, jak ramiona czy nogi, ale zawodzi w przypadku zwiewnych sukienek, narzuconych płaszczy, włosów czy torebek, które nie podążają za prostym, standardowym kształtem. Kolejną przeszkodą są dane: w sieci jest miliony zdjęć mody, ale niemal brak dużych zbiorów precyzyjnie zmierzonych ubrań 3D do treningu. Wreszcie, pojedyncze zdjęcie ukrywa ważne informacje. Krótki płaszcz blisko aparatu może wyglądać identycznie jak większy dalszy płaszcz, a oświetlenie i wzory tkanin również mogą zmylić algorytm uczący się. Te niejednoznaczności utrudniają sieci neuronowej „zgadnięcie” poprawnej struktury 3D.
Nauka AI rozróżniania przyczyny od skutku
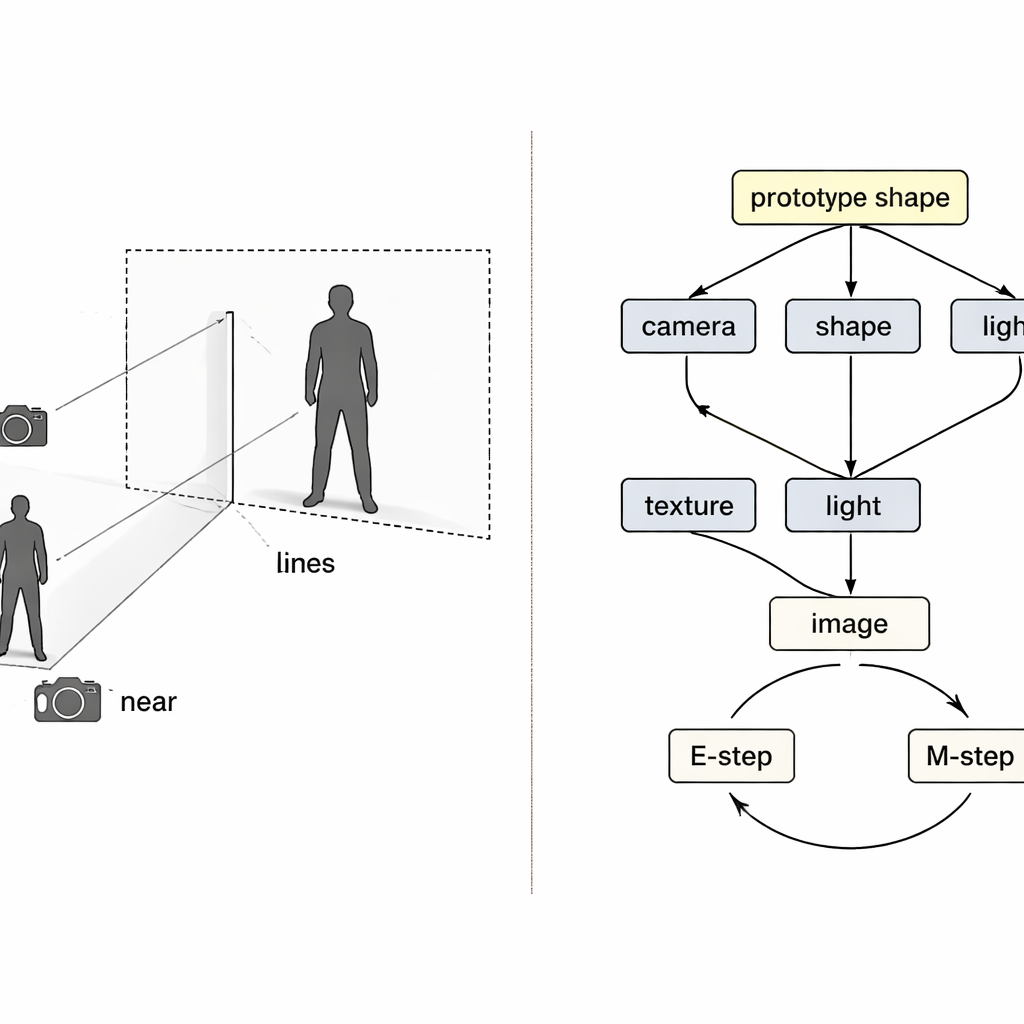
Zamiast traktować problem jako czarną skrzynkę mapującą piksele na 3D, autorzy zaczerpnęli pomysły z rozumowania przyczynowego — matematyki przyczyny i skutku. Postrzegają finalny obraz jako wynik czterech ukrytych przyczyn: pozycji kamery, kształtu ubrania, jego tekstury (kolorów i wzorów) oraz oświetlenia. Specjalna „strukturalna mapa przyczynowa” pokazuje, jak te czynniki łączą się, by wytworzyć obserwowany obraz. Kierowani tą mapą, system używa czterech oddzielnych enkoderów neuronowych, z których każdy odpowiada za jeden czynnik. Wraz z fizycznie inspirowanym rendererem 3D tworzą pętlę: wejściem jest obraz i maska pierwszego planu, wyjściem kolorowa siatka 3D, która następnie jest rzutowana z powrotem do obrazu i porównywana z oryginałem.
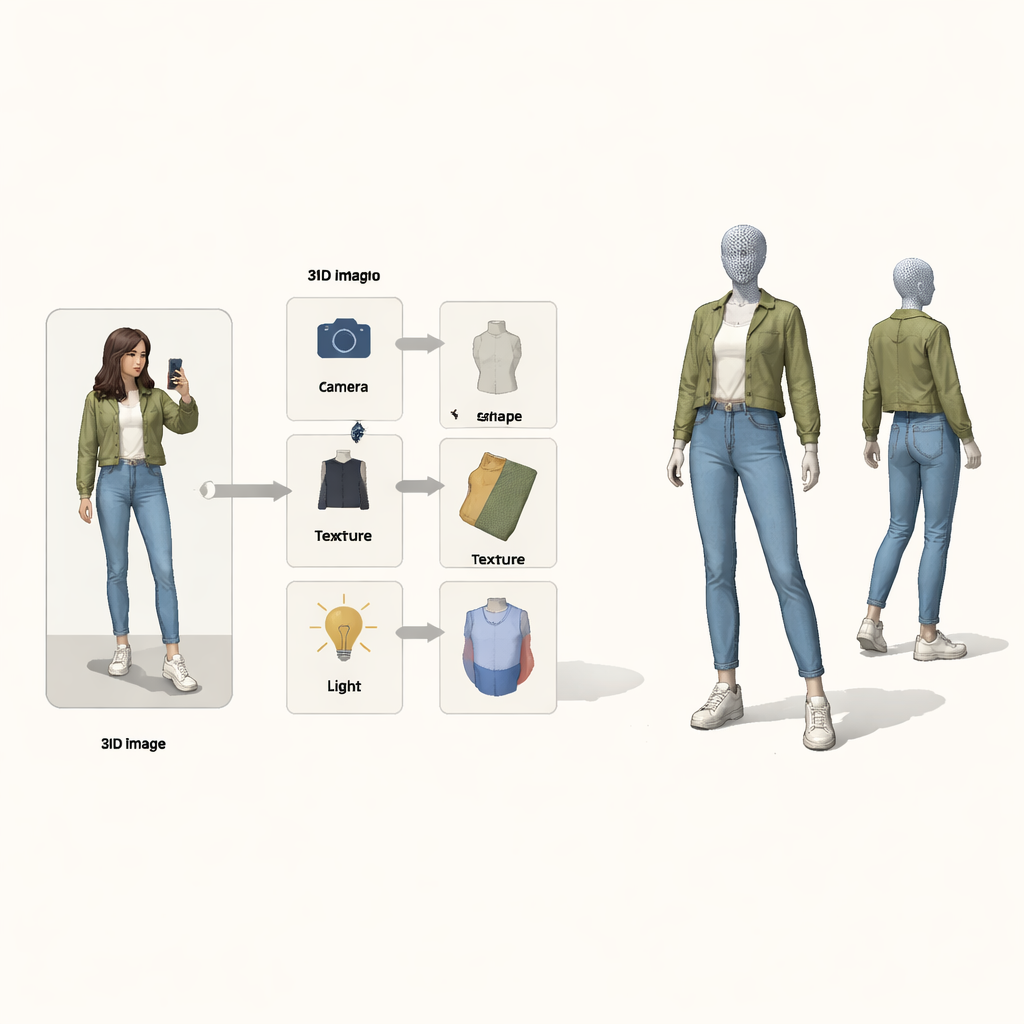
Pętla uczenia, która naprawia jedną rzecz na raz
Nawet przy oddzielnych enkoderach trening może się nie udawać. Jeśli rekonstrukcja jest niedoskonała, trudno określić, który enkoder zawinił, a zwykłe uczenie ma tendencję do jednoczesnej korekty wszystkich. Autorzy traktują to jak klasyczny problem „kolizora” w przyczynowości, gdzie różne przyczyny mogą błędnie kompensować się nawzajem. Ich rozwiązaniem jest wplecenie dwóch pętli oczekiwania–maksymalizacji w proces treningowy. W pierwszej pętli trzy enkodery są tymczasowo zamrożone, podczas gdy aktualizowany jest tylko czwarty, tak by błędy były jasno przypisywane i dany komponent nauczył się czystszej roli. W drugiej pętli wspólny „prototypowy” kształt 3D — zaczynający jako prosta kula — jest stopniowo aktualizowany, by stać się średnim kształtem człowieka lub ptaka w danych. Pojedyncze przykłady uczą się jedynie niewielkich odchyleń od tego prototypu, podczas gdy moduł kamery bierze pełną odpowiedzialność za to, jak duży lub bliski wydaje się obiekt, bezpośrednio zwalczając konfuzję rozmiaru z odległością.
Od zdjęć mody po ptaki i dalej
Aby przetestować swoje podejście, badacze trenują na dwóch dużych zbiorach zdjęć mody zawierających zwykłe uliczne fotki oraz na standardowym zbiorze zdjęć ptaków. Co ważne, używają tylko 2D masek pierwszego planu, a nie 3D siatek referencyjnych. W przypadku ubrań system przewyższa popularne metody oparte na szablonie ciała w dopasowywaniu rzeczywistego konturu garderoby i wierniej obsługuje elementy nienadające się do modelu sztywnego, jak włosy czy torebki. W przypadku ptaków osiąga lub przewyższa jakość czołowych metod rekonstrukcji 3D z pojedynczego obrazu, jednocześnie generując bardziej realistyczne nowe punkty widzenia. Modele 3D są na tyle elastyczne, by wspierać zabawne zastosowania, takie jak wymiana tekstur ubrań między ludźmi czy generowanie syntetycznych danych treningowych do poprawy systemów re-identyfikacji osób używanych w badaniach nad monitoringiem.
Co to oznacza dla codziennych cyfrowych światów
Dla niespecjalistów kluczowy przekaz jest taki, że przekonujące awatary 3D i narzędzia do wirtualnego przymierzania nie wymagają już kosztownych skanerów 3D ani sztywnych szablonów. Poprzez jawne modelowanie przyczyny i skutku — rozdzielenie kamery, kształtu, tekstury i światła oraz oparcie ich na wspólnym prototypie — autorzy pokazują, jak system może „wytłumaczyć” pojedyncze zdjęcie jako scenę 3D. Choć metoda wciąż ma trudności z widokami, których nigdy nie widziała, na przykład z tyłu osoby fotografowanej tylko z przodu, stanowi istotny krok w kierunku praktycznych 3D Magic Mirrors działających na chaotycznych, naturalnych zdjęciach, które rzeczywiście robimy.
Cytowanie: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Słowa kluczowe: wirtualne przymierzanie, rekonstrukcja 3D, uczenie przyczynowe, widzenie komputerowe, AI w modzie