Clear Sky Science · pl
Rola dużych modeli językowych w opiece w nagłych wypadkach: kompleksowe badanie porównawcze
Dlaczego to ma znaczenie dla każdego, kto może trafić na SOR
Szatnie ratunkowe są dziś bardziej zatłoczone niż kiedykolwiek: dłuższe oczekiwania i mniej personelu do opieki nad rosnącą liczbą krytycznie chorych pacjentów. W tym badaniu zadano pytanie dotyczące niemal wszystkich: czy nowoczesne systemy sztucznej inteligencji, znane jako duże modele językowe, mogą bezpiecznie pomóc lekarzom i pielęgniarkom pracować szybciej i mądrzej na oddziale ratunkowym? Przeprowadzając kilka czołowych systemów AI przez serię testów medycznych i symulowanych przypadków SOR, badacze sprawdzają, jak blisko te narzędzia są do zostania zaufanymi "współpilotami" w opiece nagłej.
Szatnie ratunkowe pod silną presją
Artykuł zaczyna się od zarysowania narastającego kryzysu w opiece ratunkowej, zwłaszcza w Stanach Zjednoczonych. Starzejące się społeczeństwo i wzrost chorób przewlekłych generują rekordową liczbę wizyt na SOR, sięgającą około 155 milionów tylko w 2022 roku. Jednocześnie szpitale borykają się z poważnymi brakami pielęgniarek i lekarzy, a liczba łóżek na osobę spadła w ciągu ostatnich dekad. Zfragmentaryzowany system opieki utrudnia koordynację, zwiększając ryzyko opóźnień i błędów. Na tym tle autorzy argumentują, że pilnie potrzebne są nowe narzędzia, które pomogą klinicystom w triażu pacjentów, podejmowaniu szybkich decyzji i dokumentowaniu opieki bez zwiększania obciążenia pracy.
Jak badacze testowali medyczne systemy AI
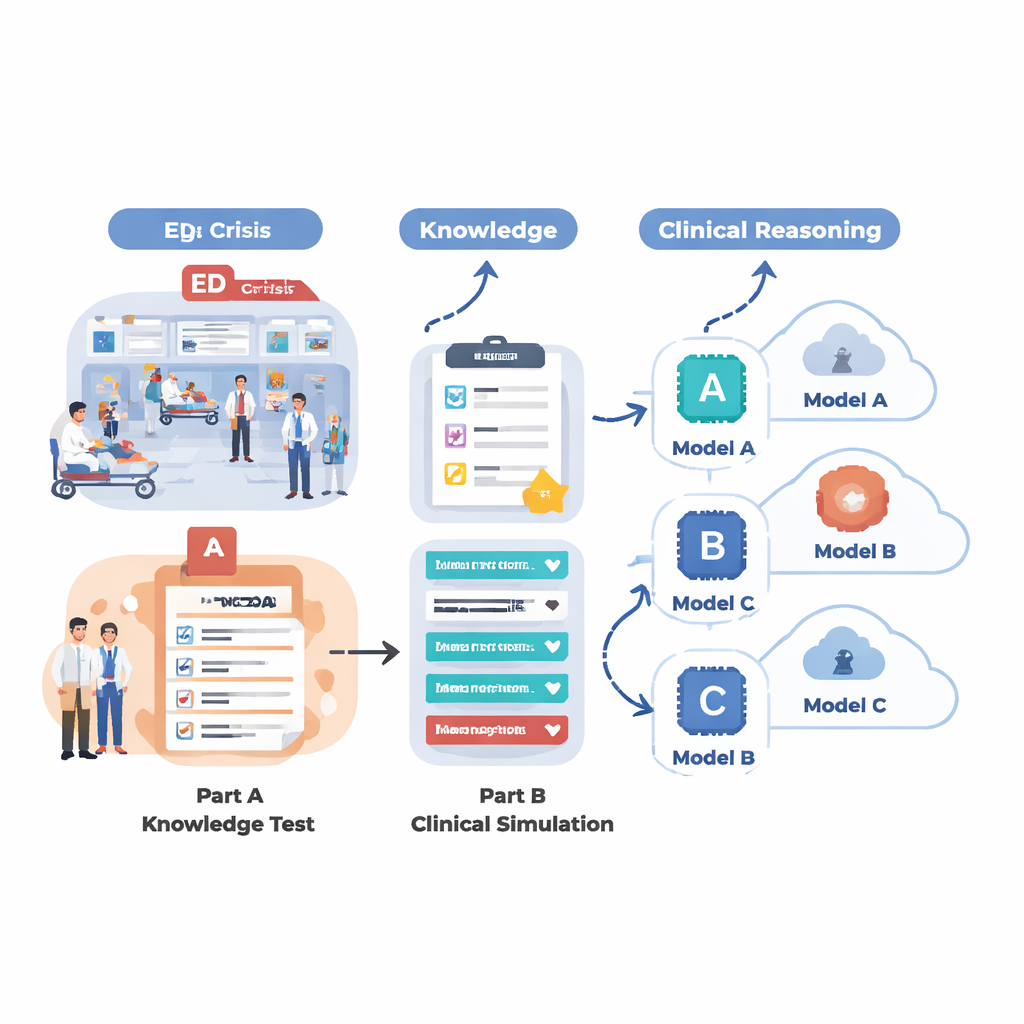
Aby sprawdzić, co obecne systemy AI rzeczywiście potrafią w warunkach przypominających SOR, zespół zaprojektował dwuczęściową ocenę. Najpierw przetestowali 18 różnych modeli językowych na dużym zestawie pytań wielokrotnego wyboru pochodzących z MedMCQA, zbioru danych w stylu egzaminu medycznego obejmującego 12 typowych zgłoszeń SOR, takich jak ból w klatce piersiowej, duszność, ból głowy i ból brzucha. Ta faza mierzyła podstawową wiedzę medyczną: czy AI potrafi wybrać prawidłową odpowiedź spośród czterech opcji w tysiącach pytań? Następnie z pięciu najsilniejszych modeli z tej rundy poproszono o przepracowanie 12 realistycznych przypadków ratunkowych krok po kroku, tak jak zrobiłby to lekarz. W każdym przypadku AI musiało streścić pacjenta, przypisać poziom pilności w triage, zasugerować kluczowe pytania uzupełniające, zaproponować kroki postępowania oraz wypisać prawdopodobne rozpoznania w miarę stopniowego ujawniania nowych informacji (parametry życiowe, wywiad, wyniki badania, badania laboratoryjne i obrazowe).
Które modele AI znały fakty — a które potrafiły wnioskować
W zakresie czystego odtwarzania faktów kilka modeli radziło sobie imponująco. Specjalistyczny system o nazwie LLaMA 4 Maverick osiągnął około 91 procent trafności ogólnej w pytaniach medycznych, tuż za nim uplasowały się LLaMA 3.1, GPT-4.5, GPT-5 i Claude 4. Te czołowe modele konsekwentnie wypadały mocno w różnych zgłoszeniach, co sugeruje, że nowoczesne AI mogą zbliżać się do pułapu wiedzy podręcznikowej. Systemy średniej klasy wyraźnie odstawały, niektóre z nich osiągały około 60 procent i miały problemy w kluczowych obszarach, takich jak opieka nad ranami czy problemy z oddychaniem. Jednak gdy zadanie przesunęło się od odpowiadania na izolowane pytania do rozumowania nad bogatymi, ewoluującymi historiami pacjentów, różnice stały się bardziej wyraźne. W tych symulacjach klinicznych GPT-5 wyraźnie się wyróżniał: generował najdokładniejsze i najpełniejsze streszczenia, zadawał najbardziej pomocne pytania uzupełniające, rekomendował sensowne i bezpieczne dalsze kroki oraz proponował najbardziej szczegółowe i uporządkowane listy możliwych rozpoznań.
Mocne strony, słabości i obawy dotyczące bezpieczeństwa
Klinicyści starannie oceniali każdą odpowiedź AI pod kątem dokładności, trafności i bezpieczeństwa. GPT-5 nie tylko uzyskał najwyższe oceny ogólne; był też jedynym modelem, którego wydajność pozostawała stabilna lub poprawiała się w miarę wzrostu złożoności przypadków, przy jednoczesnym utrzymaniu halucynacji i poważnych błędów poniżej około 2 procent. Inne modele ujawniły wyraźne wzorce słabości. Niektóre miały tendencję do pomijania rozpoznań drugorzędnych lub stawiania drobnych problemów przed tymi niebezpiecznymi. Inne stawały się nadmiernie ostrożne lub niejasne, albo zbyt szybko skupiały się na jednym rozpoznaniu. W całym zestawie większość systemów zaniżała ocenę ciężkości stanu pacjentów przy przydzielaniu poziomów triage, co jest konserwatywnym uprzedzeniem mogącym opóźnić pilną opiekę, jeśli nie zostanie skorygowane. Wyniki podkreślają kluczową tezę: znajomość faktów medycznych to nie to samo co wiarygodne łączenie tych faktów w bezpieczne, krok po kroku decyzje, gdy informacje są niepełne, nieuporządkowane i zmienne.

Co to może oznaczać dla przyszłych wizyt na SOR
Autorzy konkludują, że chociaż kilka nowoczesnych systemów AI zbliża się do siebie pod względem wiedzy medycznej, GPT-5 w szczególności wykazuje nowy poziom zdolności rozumowania, który mógłby uczynić go użytecznym narzędziem wspierającym decyzje na oddziałach ratunkowych. Podkreślają, że te systemy nie są gotowe, by zastąpić klinicystów ani działać samodzielnie. Zamiast tego najbardziej obiecującą rolą w krótkim terminie widzą asystenta pod nadzorem — pomagającego pielęgniarkom triażującym ocenić pilność, sporządzać streszczenia pacjentów, sugerować pytania lub badania oraz sprawdzać, czy rozważono poważne rozpoznania. Badanie podkreśla również potrzebę dalszych badań w rzeczywistych warunkach klinicznych, z silnymi zabezpieczeniami i jasnymi zasadami użytkowania. Dla pacjentów przekaz jest ostrożnym optymizmem: AI coraz lepiej rozwiązuje problemy medyczne, ale jego bezpieczne stosowanie na SOR będzie zależeć od starannego projektowania, nadzoru i ciągłego wspierania — a nie zastępowania — ludzkiego osądu lekarzy i pielęgniarek.
Cytowanie: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Słowa kluczowe: medycyna ratunkowa, duże modele językowe, wsparcie decyzji klinicznych, triaż, porównywanie systemów AI w medycynie