Clear Sky Science · pl
Poprawa rozpoznawania nazwanych jednostek w trybie few-shot dla dużych modeli językowych przy użyciu ustrukturyzowanego dynamicznego promptowania z generowaniem wspomaganym wyszukiwaniem
Dlaczego inteligentniejsze czytanie tekstów medycznych ma znaczenie
Współczesna medycyna generuje ogromne ilości tekstu — od notatek z oddziałów intensywnej terapii po internetowe dyskusje o stosowaniu leków. W tych słowach kryją się istotne wskazówki dotyczące chorób, terapii i skutków ubocznych. Automatyczne wykrywanie i oznaczanie takich fragmentów informacji, zadanie zwane „rozpoznawaniem nazwanych jednostek”, może pomóc badaczom śledzić ogniska chorób, szybciej wychwytywać problemy z lekami i wspierać lekarzy w czasie rzeczywistym. Tradycyjne systemy jednak wymagają dużych, ręcznie oznaczonych zbiorów danych, których stworzenie jest kosztowne i często niemożliwe dla rzadkich lub nowych zagadnień zdrowotnych. W pracy tej badacze badają, jak duże modele językowe, podobne do tych napędzających dzisiejsze chatboty, można ukierunkować dzięki starannie zaprojektowanym promptom i inteligentnemu wyszukiwaniu przykładów, aby dobrze wykonywały to zadanie oznaczania nawet mając do dyspozycji tylko kilka oznaczonych próbek.
Nauczanie maszyn rozpoznawania ważnych słów
Autorzy koncentrują się na biomedycznym rozpoznawaniu nazwanych jednostek — wyszukiwaniu w tekście wzmiankowań chorób, leków, objawów i społecznych konsekwencji. Zadanie to jest trudne, ponieważ język medyczny jest wysoce specjalistyczny, różni się między szpitalami czy dziedzinami i często obejmuje rzadkie stany pojawiające się tylko kilka razy w dowolnym zbiorze danych. Istniejące modele uczenia maszynowego potrafią osiągnąć wydajność zbliżoną do ludzkiej, lecz zwykle wymagają dużych, dobrze oznaczonych korpusów, których tworzenie i udostępnianie jest kosztowne, zwłaszcza przy surowych zasadach prywatności. Uczenie few-shot, w którym modele uczą się na podstawie zaledwie garści oznaczonych przykładów, oferuje obejście tego wąskiego gardła. Duże modele językowe są tu szczególnie obiecujące, ponieważ potrafią wyciągać wzorce bezpośrednio z instrukcji i przykładów zawartych w prompcie, bez ponownego trenowania swoich wag wewnętrznych.
Budowanie lepszych instrukcji dla modeli językowych
Pierwsza część pracy projektuje silnie ustrukturyzowany „statyczny” prompt — wielokrotnego użytku blok instrukcji i przykładów przedstawiany modelowi dla każdego zdania, które ma oznaczyć. Zamiast jedynie polecać modelowi oznaczanie jednostek, prompt został rozbity na sześć elementów: jasny opis zadania i definicje typów jednostek; krótki opis źródła i tematyki zbioru danych; często występujące przykładowe słowa typowe dla każdej jednostki; opcjonalna wiedza medyczna w tle; podsumowane informacje zwrotne z wcześniejszych błędów modelu; oraz kilka w pełni oznaczonych przykładowych zdań. Zespół przetestował tę ramę z trzema dużymi modelami językowymi — GPT-3.5, GPT-4 i LLaMA 3-70B — na pięciu zbiorach biomedycznych obejmujących zapisy kliniczne, streszczenia naukowe i posty z Reddit na temat używania opioidów. Starannie zestawione komponenty podniosły wartości F1 (równowaga precyzji i czułości) o około 11–12 punktów procentowych w porównaniu z podstawowym promptem, przy czym GPT-4 osiągnął najlepsze wyniki ogólne.
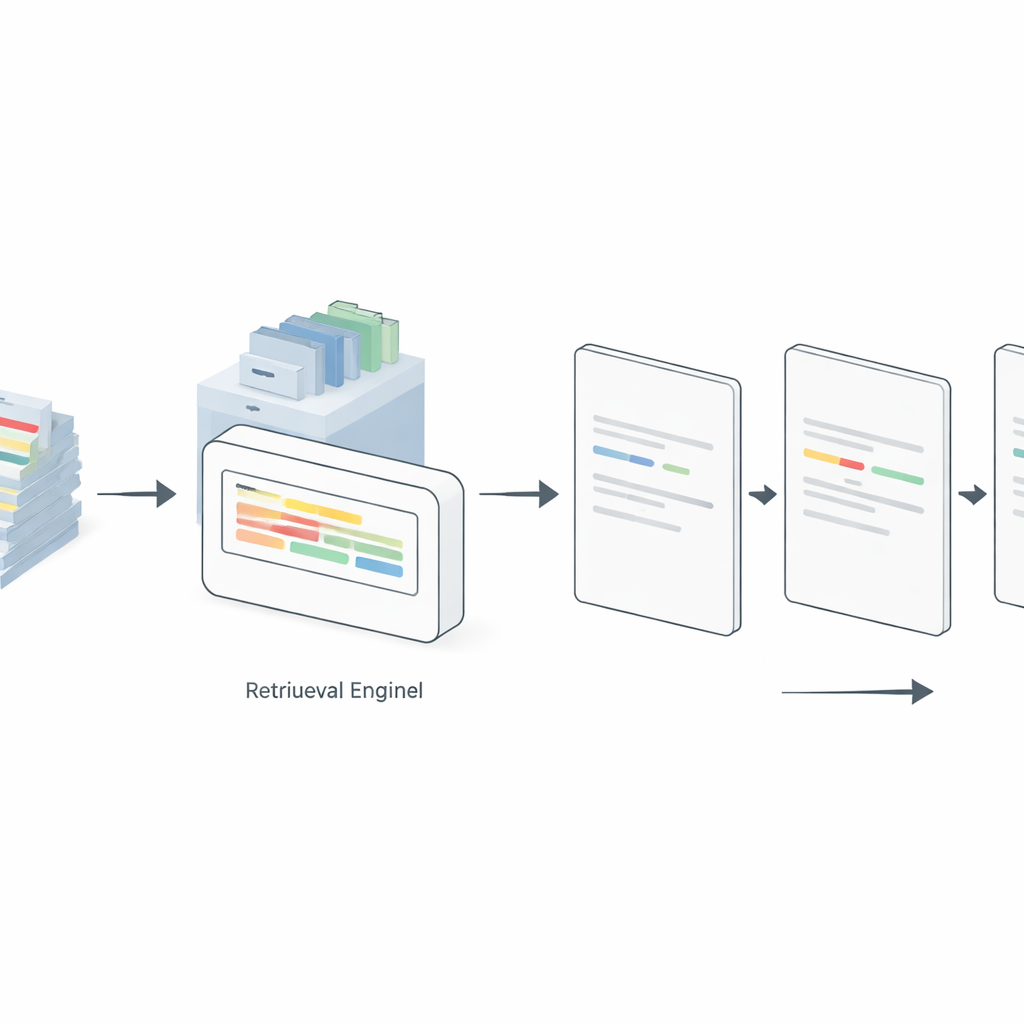
Pozwolenie modelowi na wybieranie lepszych przykładów w locie
Statyczne prompty zawsze pokazują te same przykłady, nawet gdy nie pasują dobrze do nowego zdania, które ma zostać oznaczone. Aby to rozwiązać, autorzy wprowadzają strategię „dynamicznego” promptowania wspieraną generowaniem z wyszukiwaniem (retrieval-augmented generation). Tutaj oddzielny silnik wyszukiwania indeksuje wszystkie dostępne oznaczone przykłady. Dla każdego nowego zdania system przeszukuje tę pulę, aby znaleźć najbardziej podobne oznaczone zdania i wstawia jedynie te do promptu. W badaniu porównano kilka metod wyszukiwania, od prostego schematu częstości terminów (TF–IDF) po sieciowe modele osadzania, takie jak Sentence-BERT (SBERT), ColBERT i Dense Passage Retrieval. W przypadku GPT-4, LLaMA 3 i otwartego modelu o nazwie GPT-OSS-120B dynamiczny wybór istotnych przykładów konsekwentnie przewyższał promptowanie statyczne w ustawieniach 5-, 10- i 20-shot. Co zaskakujące, prosty TF–IDF często dorównywał lub przewyższał bardziej złożone podejścia, zwłaszcza na czystszych, bardziej ustandaryzowanych zbiorach, podczas gdy SBERT błyszczał na bardziej hałaśliwych tekstach z mediów społecznościowych.
Wyciąganie więcej z mniejszej liczby oznaczonych przykładów
Ponieważ oznaczanie tekstów medycznych jest kosztowne, autorzy zbadali też, ile oznaczonych przykładów silnik wyszukiwarki musi zindeksować, aby być użytecznym. Korzystając z LLaMA 3-70B, zmieniali pulę wyszukiwania od 50 przykładów do całego zbioru treningowego. Wydajność generalnie poprawiała się wraz ze wzrostem puli, ale przyrosty szybko się spłaszczały: pule rzędu 100–200 przykładów osiągały niemal taką samą dokładność jak indeksowanie wszystkich dostępnych danych, często mieszcząc się w statystycznym marginesie błędu. W niektórych przypadkach bardzo duże pule nieznacznie pogarszały wydajność, prawdopodobnie dlatego, że wprowadzały więcej nieistotnych lub mylących przykładów i wydłużały prompt. Wyniki te sugerują, że w połączeniu z mocnym modelem językowym i dobrze zaprojektowanymi promptami nawet umiarkowane wysiłki anotacyjne mogą przynieść solidne rozpoznawanie jednostek biomedycznych, co czyni podejście wykonalnym dla rzadkich chorób, nowych koncepcji klinicznych lub instytucji o ograniczonych zasobach.
Co to oznacza dla praktycznej medycyny
Podsumowując, badanie pokazuje, że duże modele językowe mogą wiarygodnie wyodrębniać ważne koncepcje medyczne z tekstu, używając zaledwie garści oznaczonych przykładów, pod warunkiem że są prowadzone przez ustrukturyzowane prompty i system wyszukiwania, który uwidacznia najbardziej trafne wcześniejsze przypadki. GPT-4 oferuje najsilniejszą ogólną wydajność, podczas gdy modele otwarte i mniejsze również odnoszą znaczne korzyści z tego samego przepisu na promptowanie i wyszukiwanie. Dla praktyków oznacza to, że nie muszą tworzyć ogromnych zbiorów danych za każdym razem, gdy pojawia się nowy typ jednostki lub problem zdrowotny; kompaktowy, starannie dobrany zestaw przykładów plus inteligentne promptowanie może wystarczyć. W miarę jak systemy opieki zdrowotnej nadal cyfryzują notatki, a pacjenci opisują swoje doświadczenia online, takie wydajne, adaptowalne narzędzia mogą znacznie ułatwić wydobycie klinicznie użytecznej wiedzy z ogromnego, chaotycznego świata tekstów medycznych.
Cytowanie: Ge, Y., Guo, Y., Das, S. et al. Improving few-shot named entity recognition for large language models using structured dynamic prompting with retrieval augmented generation. npj Artif. Intell. 2, 39 (2026). https://doi.org/10.1038/s44387-025-00062-2
Słowa kluczowe: biomedyczne rozpoznawanie nazwanych jednostek, uczenie few-shot, duże modele językowe, generowanie wspomagane wyszukiwaniem, wydobywanie informacji z tekstów klinicznych