Clear Sky Science · pl
Korygowanie błędów mnożenia i sumowania w przetwarzaniu w pamięci za pomocą kodów LDPC
Dlaczego naprawianie błędów obliczeń w pamięci ma znaczenie
Nowoczesne układy sztucznej inteligencji uzyskują większą szybkość i efektywność, wykonując obliczenia bezpośrednio w pamięci zamiast nieustannie przesyłać dane między pamięcią a oddzielnymi procesorami. Podejście „processing-in-memory” oszczędza energię, lecz wprowadza poważny problem: drobne efekty elektryczne mogą zmieniać przechowywane bity lub zniekształcać sygnały analogowe, cicho pogarszając dokładność zadań takich jak rozpoznawanie obrazów. Artykuł opisuje nowy sposób automatycznego wykrywania i korygowania tych błędów w locie, pomagając przyszłemu sprzętowi AI pozostać zarówno szybkim, jak i godnym zaufania.
Obliczenia tam, gdzie są dane
Tradycyjne komputery zwalniają z powodu potrzeby przesyłania danych między pamięcią a procesorem. Projekty processing-in-memory unikają tej wąskiej gardy, wykonując operacje mnożenia i sumowania — rdzeń sieci neuronowych — wewnątrz gęstych matryc komórek pamięci. Nowe urządzenia, takie jak pamięci rezystywne i inne elementy memrystorowe, są szczególnie atrakcyjne, bo mogą przechowywać wiele wartości i wykonywać arytmetykę w stylu analogowym bardzo wydajnie. Jednak ta analogowa natura i zmienność urządzeń, które dają im moc, czynią je też hałaśliwymi: fluktuacje termiczne, niedopasowania elementów i spadki napięcia mogą odchylać przechowywane wartości lub wyniki obliczeń od oczekiwanych.
Kiedy drobne usterki się kumulują
W tych matrycach pamięci wiele wierszy jest aktywowanych jednocześnie, a ich wkłady sumowane są wzdłuż wspólnych przewodów. W miarę udziału większej liczby wierszy ich indywidualne niedoskonałości sumują się, tworząc często występujące i skomplikowane wzory błędów. Zamiast pojedynczego złego bitu projektanci często obserwują wiele błędów skupionych w tej samej kolumnie macierzy lub rozrzuconych po kilku kolumnach w sposób neutralizujący tradycyjne metody korekcji. Standardowe kody zwykle zakładają proste wzory błędów i krótkie słowa; mogą przeoczyć wielobitowe usterki lub nie mieć wpisów w tabelach wyszukiwania dla rzadkich, lecz szkodliwych kombinacji. W efekcie dokładność modeli głębokich sieci neuronowych może gwałtownie spaść, gdy sprzęt staje się nawet umiarkowanie zawodny.
Nowy rodzaj cyfrowej siatki bezpieczeństwa
Autorzy wprowadzają niebinarne kody niskiej gęstości parzystości (NB-LDPC) dostosowane specjalnie do sprzętu processing-in-memory. Zamiast operować wyłącznie zerami i jedynkami, ich schemat działa na małych grupach bitów traktowanych jako symbole w strukturze matematycznej zwanej ciałem skończonym zbudowanym na bazie liczby pierwszej (tu: trójki). Pozwala to tej samej kodowej ochronie obejmować zarówno zwykłe binarne przechowywanie, jak i wielopoziomowe czy różnicowe kodowania powszechne w akceleratorach analogowych. System dopisuje niewielką liczbę dodatkowych symboli — symboli kontrolnych — do każdego bloku danych. Zarówno podczas zwykłych odczytów pamięci, jak i podczas wykonywania w pamięci operacji mnożenia i sumowania, sprzęt oblicza wyniki dla danych i symboli kontrolnych razem, więc wykrywanie błędów jest naturalnie wplecione w sam proces obliczeniowy.
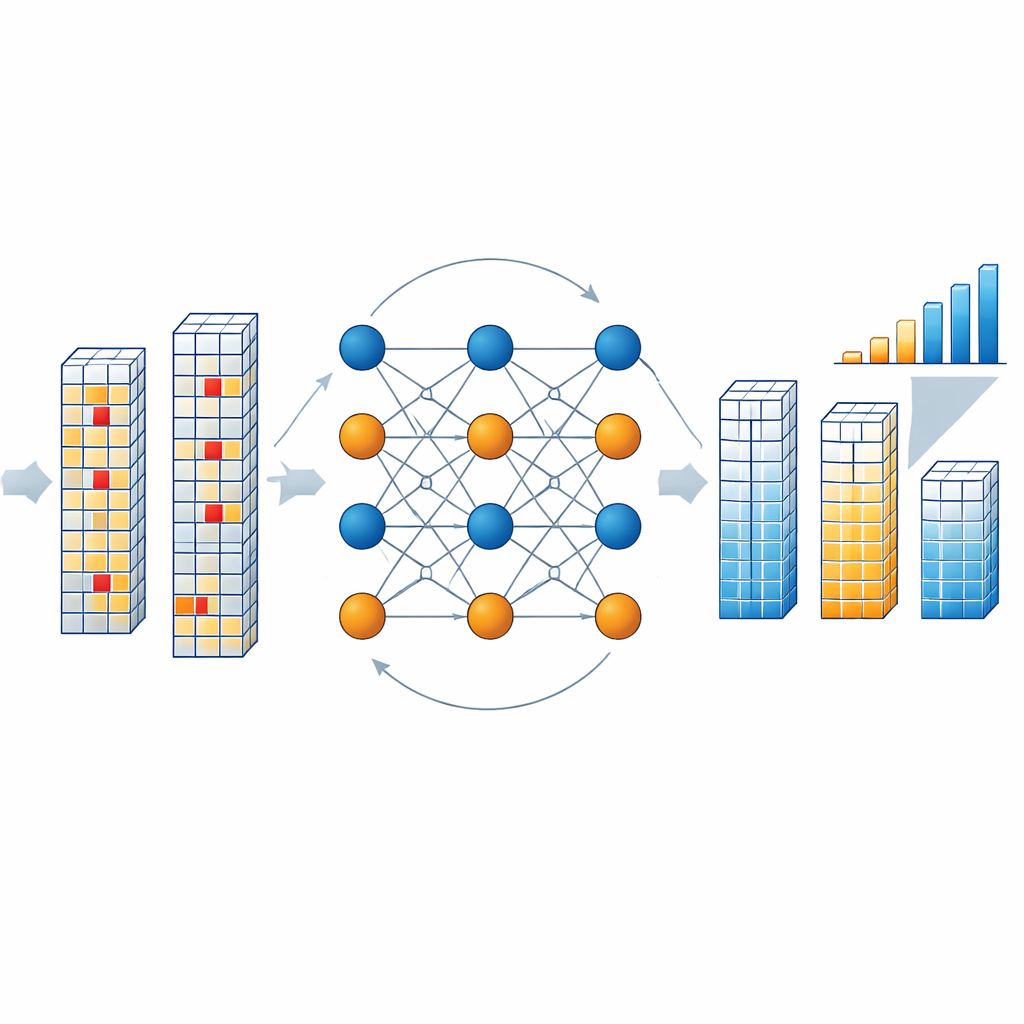
Jak działa silnik korekcyjny wewnątrz układu
Gdy układ odczytuje blok wyników, dedykowany dekoder sprawdza, czy połączone dane i symbole kontrolne spełniają relacje parzystości zdefiniowane przez kod. Jeśli tak, blok uznaje się za czysty. Jeśli nie, dekoder uruchamia iteracyjny proces, w którym abstrakcyjne „węzły zmiennych” reprezentujące każdy symbol i „węzły kontrolne” reprezentujące warunki parzystości wymieniają komunikaty prawdopodobieństwa. Te komunikaty szacują, jak prawdopodobne jest przypisanie każdemu symbolowi poszczególnych dozwolonych wartości, na podstawie zaobserwowanych wyników i oczekiwanego wskaźnika przewrotów bitów w pamięci. Autorzy upraszczają tę matematycznie wymagającą analizę, stosując przybliżenia odległości Manhattan, co znacznie obniża koszty sprzętowe przy zachowaniu wysokiej wydajności. Po kilku rundach — zwykle trzech — dekoder zbiega się do najbardziej prawdopodobnej skorygowanej wersji wektora wyników, bez potrzeby ponownego odczytu pamięci czy zatrzymywania strumienia obliczeń.
Dowód na krzemie i wpływ na dokładność AI
Aby przetestować pomysł w praktyce, zespół zbudował prototypowy układ w technologii 40 nanometrów, łączący matrycę pamięci rezystywnej, lekkie przetworniki analogowo-cyfrowe i nowy dekoder NB-LDPC. Przy konfiguracji chroniącej 256 symboli informacyjnych za pomocą 32 symboli kontrolnych dekoder osiąga wysoki współczynnik kodu (około 0,8), najlepszą zmierzoną energochłonność rzędu ok. 88 terabitów skorygowanych danych na sekundę na wat oraz jedynie umiarkowany narzut powierzchniowy, który można dodatkowo zmniejszyć poprzez udostępnianie jednego dekodera kilku makrom pamięci. Symulacje dla wielu rozmiarów kodów wykazują, że przy ochronie 1024 symboli danych za pomocą 128 symboli kontrolnych schemat może poprawić współczynnik błędów bitów niemal 60-krotnie. W zastosowaniu do modelu klasyfikacji obrazów ResNet-34 działającego na sprzęcie processing-in-memory korekcja przywraca ponad 20 punktów procentowych utraconej dokładności w trudnych warunkach błędów.
Co to oznacza dla przyszłych układów AI
Mówiąc wprost, praca dostarcza sprzętowi processing-in-memory solidnego „korektora” dla jego obliczeń, który rozumie bogatsze zbiory symboli i złożone wzory błędów bez spowalniania przepływu danych. Poprzez ujednolicenie ochrony zarówno dla przechowywanych danych, jak i obliczeń wykonywanych w locie oraz wykazanie efektywnej implementacji w krzemie, badanie pokazuje, że gęste, energooszczędne akceleratory w pamięci nie muszą rezygnować z niezawodności. Tego rodzaju dopasowana korekcja błędów może stać się kluczowym składnikiem sprawiającym, że przyszłe akceleratory neuromorficzne i AI będą zarówno energooszczędne, jak i wystarczająco niezawodne do zastosowań w świecie rzeczywistym — od urządzeń mobilnych po centra danych na dużą skalę.
Cytowanie: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
Słowa kluczowe: processing-in-memory, korekcja błędów, kody LDPC, pamięć rezystywna, sprzęt sieci neuronowych