Clear Sky Science · pl
LIMO: Niskomocowy in-memory-annealer i prymityw mnożenia macierzy dla edge computing
Mądrzejsze trasy i bardziej oszczędne układy
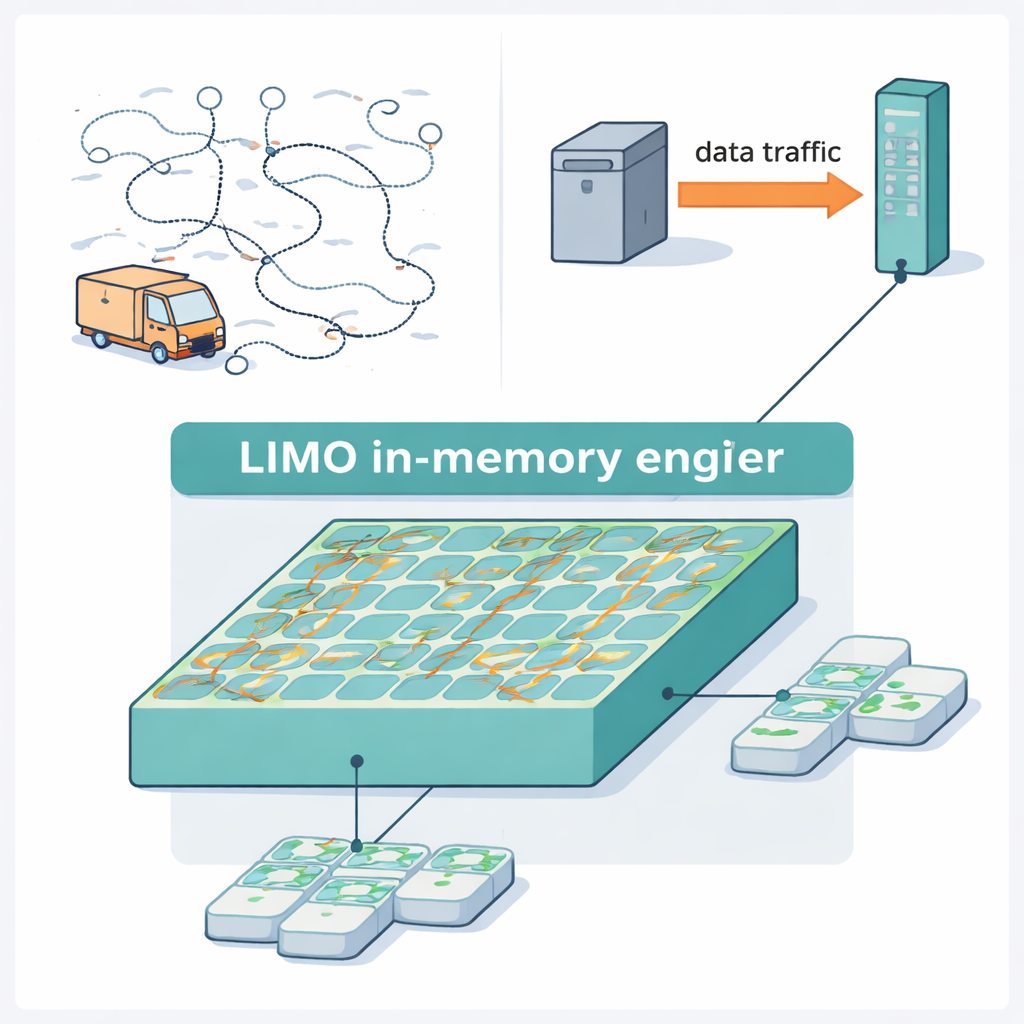
Każdego dnia firmy mierzą się z zadaniami takimi jak znalezienie najkrótszej trasy dla ciężarówki dostawczej odwiedzającej tysiące punktów albo szybkie skanowanie obrazów w celu wykrycia twarzy przy użyciu zasilanej baterią kamery. Problemy te obciążają współczesne komputery, które przesyłają ogromne ilości danych między pamięcią a procesorami. W artykule tym przedstawiono LIMO — nowy blok obliczeniowy niskiego poboru mocy, który trzyma dane na miejscu podczas rozwiązywania trudnych zadań planowania tras i uruchamiania modeli sztucznej inteligencji (AI), dzięki czemu przyszłe urządzenia brzegowe będą szybsze i bardziej energooszczędne.
Dlaczego znajdowanie dobrych tras jest takie trudne
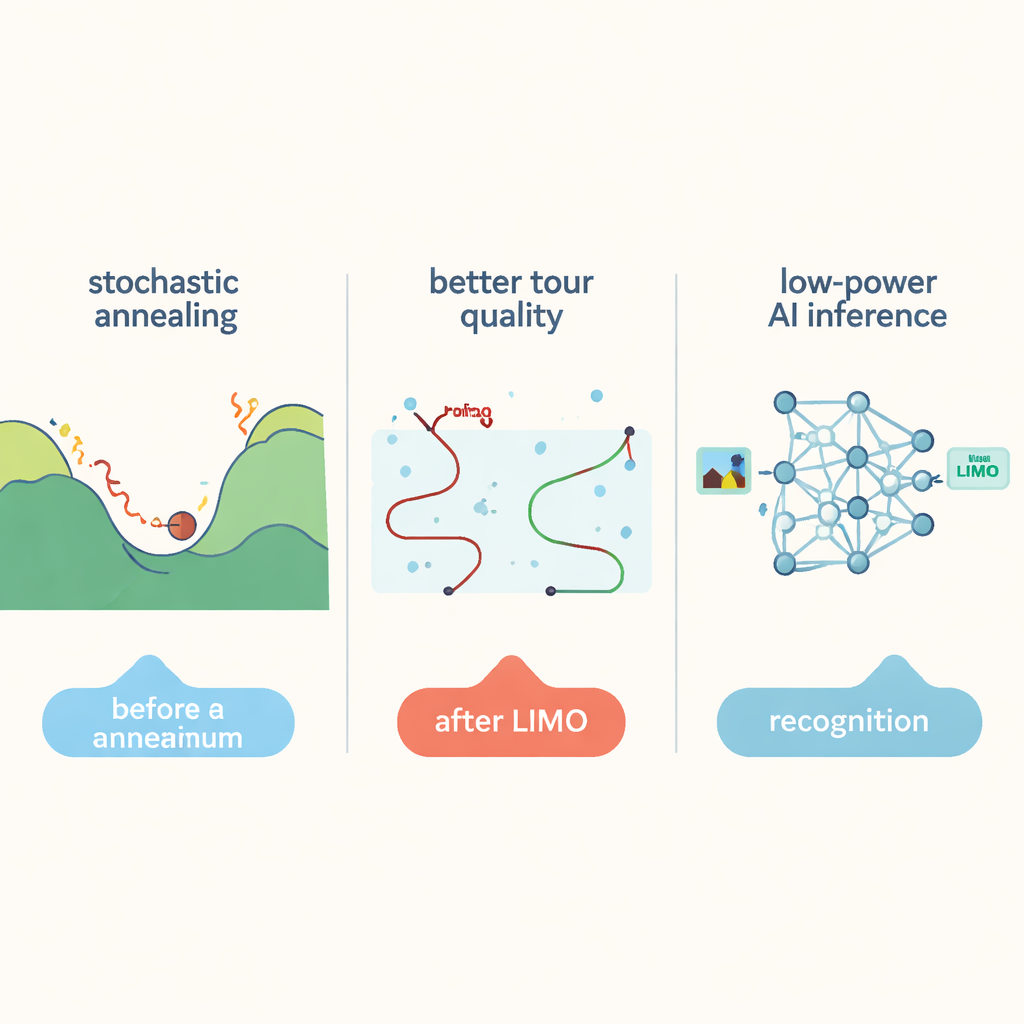
W centrum tej pracy znajduje się znany Problem Komiwojażera: mając wiele miast, znaleźć najkrótszą trasę odwiedzającą każde miasto raz i wracającą do punktu startowego. Dla małych map dokładne metody matematyczne potrafią znaleźć optymalne rozwiązanie. Jednak gdy liczba miast rośnie do dziesiątek tysięcy, liczba możliwych tras eksploduje i nawet potężne komputery zaczynają mieć problemy. Heurystyki, takie jak symulowane wyżarzanie, mogą przeszukiwać tę ogromną przestrzeń, znajdując dobre, choć niekoniecznie optymalne trasy, czasem akceptując gorsze rozwiązania pośrednie, aby uniknąć utknięcia w lokalnym optimum. Standardowe podejścia nadal jednak niewydajnie eksplorują przestrzeń poszukiwań dla bardzo dużych problemów i marnują czas na przemieszczanie danych między pamięcią a CPU, trafiając na tzw. „ścianę pamięci”.
Nowy sposób przeszukiwania możliwości
Autorzy proponują nowy algorytm o nazwie Significance Weighted Annealed Insertion (SWAI), który przekształca sposób eksploracji kandydackich tras. Zamiast ciągłego zamieniania par miast, co źle skaluje się wraz ze wzrostem liczby miast, SWAI buduje trasę krok po kroku, wstawiając jedno nowe miasto na raz. Przy każdym kroku algorytm czasem wybiera najbliższe miasto (podejście zachłanne), a czasem opiera się na kontrolowanym losowym wyborze, który faworyzuje krótsze krawędzie kandydackie, ale nie wyklucza całkowicie dłuższych. To uprzedzenie jest stopniowo regulowane w czasie — zaczyna się bardziej śmiale, a wraz z postępem poszukiwań staje się bardziej konserwatywne. Ponieważ każdy krok rozważa opcje w sposób rosnący jedynie liniowo względem liczby miast, algorytm efektywniej bada dalekozasięgowe ulepszenia niż tradycyjne symulowane wyżarzanie.
Obliczenia wewnątrz pamięci z wbudowaną losowością
LIMO zamienia ten algorytm w sprzęt poprzez ścisłe współprojektowanie układów i metody poszukiwań. W jego centrum znajduje się zmodyfikowana macierz pamięci przechowująca zarówno bieżącą trasę, jak i odległości między miastami, która wykonuje kluczowe kroki aktualizacji bez ciągłej komunikacji z odrębnym procesorem. Losowe wybory potrzebne w algorytmie pochodzą z małych urządzeń magnetycznych zwanych spin-transfer-torque magnetic tunnel junctions, które naturalnie zmieniają stan w sposób nieprzewidywalny pod odpowiednim prądem. Projektanci konwertują tę fizyczną losowość na bity cyfrowe i używają prostych porównań do realizacji probabilistycznych decyzji w algorytmie. Ponieważ większość operacji pozostaje cyfrowa i odbywa się bezpośrednio w pamięci, system unika dużych przetworników i delikatnych obwodów analogowych, oszczędzając zarówno energię, jak i powierzchnię układu.
Dzielenie dużych problemów na kawałki
Aby rozwiązać naprawdę duże zadania planowania tras, obejmujące do 85 900 miast, system stosuje strategię dziel i zwyciężaj. Lekka metoda geometryczna grupuje pobliskie miasta w klastry, aż każdy klaster będzie na tyle mały, by zmieścić się w jednym bloku LIMO. Sprzęt rozwiązuje wiele takich podtras równolegle, a następnie łączy je z powrotem w pełną trasę. Dodatkowe kroki polepszające dopracowują trasę globalnie: fragmenty trasy są reoptymalizowane przez sprzęt, a klasyczne oczyszczanie „2-opt” wykonywane na zwykłym procesorze usuwa pozostałe skrzyżowania. W testach na standardowych benchmarkach to połączenie przyniosło trasy wyższej jakości niż poprzednie wyspecjalizowane maszyny wyżarzające, osiągając przy tym odpowiedzi nawet do około pięciokrotnie szybciej w największych problemach.
Od trudnych tras do wydajnej AI
LIMO nie ogranicza się do planowania tras. Ta sama macierz pamięci może też służyć jako blok budulcowy dla sieci neuronowych, wykonując mnożenia wektor–macierz — podstawową operację stojącą za rozpoznawaniem obrazów i wzorców. Zamiast używać energochłonnych, precyzyjnych przetworników do odczytu sygnałów analogowych, LIMO polega na bardzo prostych układach detekcji, które rejestrują jedynie znak skumulowanego sygnału, i rekompensuje tę surowość poprzez trenowanie sieci w sposób świadomy wobec sprzętu. W zadaniach klasyfikacji obrazów i wykrywania twarzy te sieci osiągały dokładność zbliżoną do standardowych modeli programowych, jednocześnie zmniejszając zużycie energii i czas reakcji w porównaniu z konwencjonalnymi układami compute-in-memory. Dla codziennych użytkowników oznacza to, że kamery, drony i inne urządzenia brzegowe mogłyby w przyszłości rozwiązywać złożone zadania planistyczne i uruchamiać modele AI dłużej na baterii — wszystko dzięki inteligentniejszemu przeszukiwaniu i przetwarzaniu bezpośrednio tam, gdzie znajdują się dane.
Cytowanie: Holla, A., Chatterjee, S., Sen, S. et al. LIMO: Low-power in-memory-annealer and matrix-multiplication primitive for edge computing. npj Unconv. Comput. 3, 10 (2026). https://doi.org/10.1038/s44335-026-00054-8
Słowa kluczowe: obliczenia w pamięci, problem komiwojażera, sprzętowe wyżarzanie, niskomocowa sztuczna inteligencja, edge computing