Clear Sky Science · pl
Ocena niepewności szacunkowej w dużych modelach językowych
Dlaczego rozmyte słowa o ryzyku mają naprawdę znaczenie
Kiedy lekarz mówi, że leczenie jest „prawdopodobnie” skuteczne, albo prognoza pogody ostrzega, że istnieje „małe szanse” na huragan, polegamy na tych rozmytych sformułowaniach, by podejmować rzeczywiste decyzje. Dziś duże modele językowe (LLM), takie jak internetowe chatboty, zaczynają używać tego samego słownictwa. Badanie stawia proste, lecz kluczowe pytanie: gdy SI mówi „prawdopodobnie”, czy ma na myśli to samo co my — i czy potrafi niezawodnie zamieniać surowe liczby na codzienne słowa wyrażające niepewność?
Przyglądając się codziennej niepewności pod mikroskopem
Autorzy koncentrują się na „słowach szacunkowego prawdopodobieństwa” (WEP) — terminach takich jak „prawie pewne”, „prawdopodobne” czy „małe szanse”, których ludzie używają zamiast dokładnych procentów. Wcześniejsze prace, sięgające analityków wywiadu z lat 60. XX wieku, próbowały powiązać te słowa z prawdopodobieństwami liczbowymi poprzez badania ankietowe. To badanie porównuje te ludzkie oceny z wynikami pięciu nowoczesnych LLM, w tym GPT-3.5, GPT-4, modeli Llama firmy Meta oraz chińskiego systemu ERNIE-4.0. Dla 17 powszechnych wyrazów niepewności każdy model otrzymywał krótkie, przypominające opowiadania polecenia w języku angielskim lub chińskim i proszono go o podanie liczbowego prawdopodobieństwa w przedziale 0–100 procent. Powtarzając to w wielu kontekstach, autorzy zbudowali pełne rozkłady prawdopodobieństwa dla każdego słowa i każdego modelu, a następnie porównali je z danymi z badań ludzkich.
Gdzie ludzie i SI mówią tym samym językiem
Dla najbardziej ekstremalnych wyrażeń — takich jak „prawie pewne” na wysokim końcu i „prawie brak szans” na niskim — LLM i ludzie zaskakująco dobrze się pokrywają. Zarówno ludzie, jak i modele mają tendencję do grupowania tych fraz w wąskich zakresach wysokiego lub niskiego prawdopodobieństwa, co sugeruje, że te silne określenia mają względnie stabilne znaczenia w różnych kontekstach. Podobnie jest z „około pół na pół”, które większość ludzi i modeli traktuje jako mniej więcej 50–50. Testy statystyczne nie wykazują istotnych różnic między rozkładami ludzkimi i modeli dla tych konkretnych słów, co sugeruje, że LLM potrafią uchwycić wyraźne przypadki niemal pewności lub niemal niemożliwości z ludzką precyzją.
Gdzie znaczenia delikatnie się rozchodzą
Niejasne, pośrednie słowa pokazują inną historię. Dla wyrażeń takich jak „prawdopodobne”, „możliwe”, „wątpimy” czy „małe szanse” numeryczne interpretacje modeli różnią się znacząco od ocen ludzkich. GPT-4, mimo ogólnie większych możliwości niż GPT-3.5, często wykazuje większe rozbieżności. Autorzy sugerują, że może to wynikać z faktu, iż takie słowa łączą dwie rzeczy: poczucie prawdopodobieństwa i postawę mówiącego. W rzeczywistych rozmowach „prawdopodobne” może brzmieć ostrożnie lub pewnie w zależności od tonu i kontekstu, a „wątpimy” może wyrażać sceptycyzm zamiast precyzyjnego prawdopodobieństwa. Szkolone na ogromnym, mieszanym korpusie tekstów z internetu, LLM mogą uśredniać sprzeczne użycia, zacierając te subtelności. Efekt to ukryte niedopasowanie: ludzie i SI mogą widzieć to samo zdanie, a cicho przypisywać tej samej frazie różne liczby.
Płeć, język i kulturowe echo
Badacze sprawdzili również, jak sformułowania z uwzględnieniem płci i różne języki kształtują te słowa prawdopodobieństwa. Gdy polecenia odnosiły się do „on” lub „ona” zamiast neutralnych podmiotów, GPT-3.5 i GPT-4 często generowały mniej zróżnicowane, bardziej „zamrożone” estymaty prawdopodobieństwa, czasem sprowadzające się do pojedynczego punktu. Sugeruje to, że modele mogły przyswoić sztywne wzorce wynikające ze stereotypów w danych treningowych, choć ogólne średnie dla poleceń odnoszących się do mężczyzn i kobiet były podobne. Porównując polecenia angielskie i chińskie, modele GPT wykazywały zauważalne przesunięcia w interpretacji tych samych słów niepewności. ERNIE-4.0, szkolony głównie na tekstach chińskich, był bliższy chińskojęzycznym ludziom w wielu terminach, ale nadal przeszacowywał lub niedoszacowywał pewnych wyrażeń. Te wyniki podkreślają, że sposób, w jaki SI mówi o niepewności, zależy nie tylko od wybranego słowa, lecz także od językowych i kulturowych wzorców zawartych w danych treningowych.
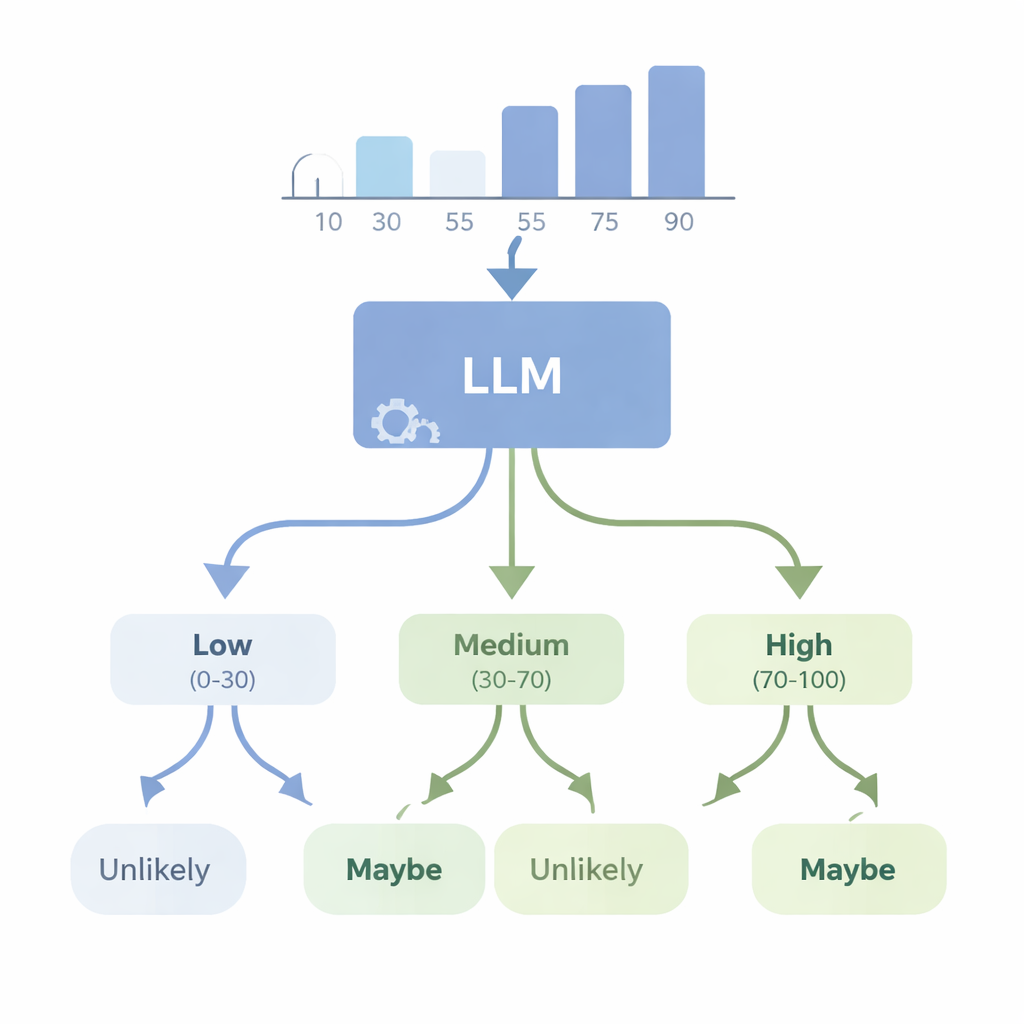
Czy SI potrafią zamienić liczby na zwykły językowy niepewność?
W drugim zestawie eksperymentów autorzy rozważyli odwrotny problem: czy zaawansowany model, taki jak GPT-4, potrafi zacząć od danych liczbowych i wybrać odpowiednie słowo wyrażające niepewność? Podali modelowi proste zbiory danych — na przykład listy wzrostów czy wyników testów — i poprosili go o wybór najlepiej pasującego WEP (na przykład „prawie na pewno”, „prawdopodobne”, „może”, „mało prawdopodobne” lub „prawie na pewno nie”) dla stwierdzeń dotyczących przyszłych wyników. Następnie ocenili GPT-4 przy użyciu czterech nowych wskaźników „spójności”, które sprawdzają, czy wybór słów ma logiczny sens, gdy prawdopodobieństwa rosną lub maleją, gdy opisywane są zdarzenia dopełniające się oraz gdy podstawowe liczby zmieniają się w kontrolowany sposób. GPT-4 radził sobie znacznie lepiej niż przypadkowe zgadywanie i często potrafił śledzić przybliżone zmiany prawdopodobieństwa, ale był daleki od doskonałej spójności. W niektórych testach odpowiadał niemal tak samo dla różnych poziomów pewności, co sugeruje, że czasem traktuje te słowa jako szerokie etykiety, a nie jako drobiazgowo zróżnicowaną skalę powiązaną z rzeczywistymi danymi.
Co to oznacza dla decyzji w świecie rzeczywistym
Dla czytelników przekaz jest ostrożny, lecz nie alarmistyczny. LLM już teraz potrafią naśladować nasze najsilniejsze wyrażenia pewności i niemożliwości, i często potrafią streszczać dane w rozsądne stwierdzenia „prawdopodobne” lub „mało prawdopodobne”. Jednak badanie pokazuje, że dla wielu codziennych słów niepewności ich wewnętrzna kalibracja nie w pełni odpowiada ludzkiej intuicji, a mapowanie liczb na język może być niespójne. W obszarach takich jak medycyna, polityka czy komunikacja naukowa — gdzie niewielkie przesunięcia w sposobie formułowania ryzyka lub pewności mogą mieć znaczenie — „prawdopodobnie” użyte przez model może nie znaczyć tego samego, co dla ciebie. Autorzy argumentują, że aby bezpiecznie używać tych systemów, musimy traktować słowa niepewności jako wspólny słownik, który nadal wymaga starannego dopasowania, testowania i być może jednoznacznego poparcia liczbowego, zamiast zakładać, że człowiek i maszyna domyślnie rozumieją je tak samo.
Cytowanie: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Słowa kluczowe: niepewność język, duże modele językowe, słowa prawdopodobieństwa, komunikacja człowiek-AI, interpretacja ryzyka