Clear Sky Science · pl
Wstępnie uwarunkowany niedokładny stochastyczny ADMM dla modeli głębokich
Sprytniejsze trenowanie dla sprytniejszej sztucznej inteligencji
Nowoczesne systemy sztucznej inteligencji, od chatbotów po generatory obrazów, opierają się na ogromnych sieciach neuronowych, które są znane z tego, że trudne i kosztowne w trenowaniu. W miarę jak firmy i badacze rozpraszają dane po wielu urządzeniach i serwerach, standardowe metody treningowe często zwalniają, stają się niestabilne lub po prostu nie radzą sobie z chaosem danych z rzeczywistego świata. Artykuł przedstawia nową rodzinę algorytmów trenowania, skupioną wokół metody zwanej PISA, która obiecuje szybsze i bardziej niezawodne uczenie dla szerokiej gamy modeli głębokich przy mniejszych założeniach matematycznych o danych.
Dlaczego obecne metody treningowe zawodzą
Większość modeli głębokiego uczenia trenuje się przy użyciu wariantów stochastycznego spadku gradientu, podejścia, które wielokrotnie koryguje parametry modelu w kierunku zmniejszającym błąd. Na przestrzeni lat wprowadzono wiele udoskonaleń — takich jak Adam, RMSProp i inne — które starają się czynić te korekty bardziej inteligentnymi poprzez adaptację kroków lub dodanie momentu. Jednakże te metody zazwyczaj zakładają, że dane treningowe są odpowiednio przetasowane i statystycznie podobne między maszynami oraz że pewne wielkości matematyczne pozostają ograniczone. W praktyce, szczególnie w scenariuszach takich jak uczenie zogniskowane, gdzie telefony czy urządzenia brzegowe przechowują bardzo różne dane, założenia te są często łamane, co prowadzi do wolnej zbieżności lub słabych wyników.
Nowy sposób koordynacji wielu uczących się węzłów
Autorzy opierają się na innym ramach optymalizacyjnych znanym jako metoda przemiennych kierunków mnożników (ADMM), która dobrze dzieli duży problem na wiele mniejszych, możliwych do rozwiązania równolegle. Ich główny wkład, PISA (preconditioned inexact stochastic ADMM), zachowuje zalety ADMM, unikając przy tym jego typowych wad — takich jak konieczność obliczania pełnych gradientów po wszystkich danych czy wykonywania kosztownych inwersji macierzy. Zamiast tego PISA pozwala każdemu klientowi lub węzłowi roboczemu aktualizować własną kopię modelu używając jedynie mini-partii danych, a następnie koordynuje te aktualizacje za pomocą zmiennej centralnej. Starannie zaprojektowane macierze „wstępnego uwarunkowania” przekształcają kierunki aktualizacji tak, by uczenie postępowało płynniej i wydajniej. 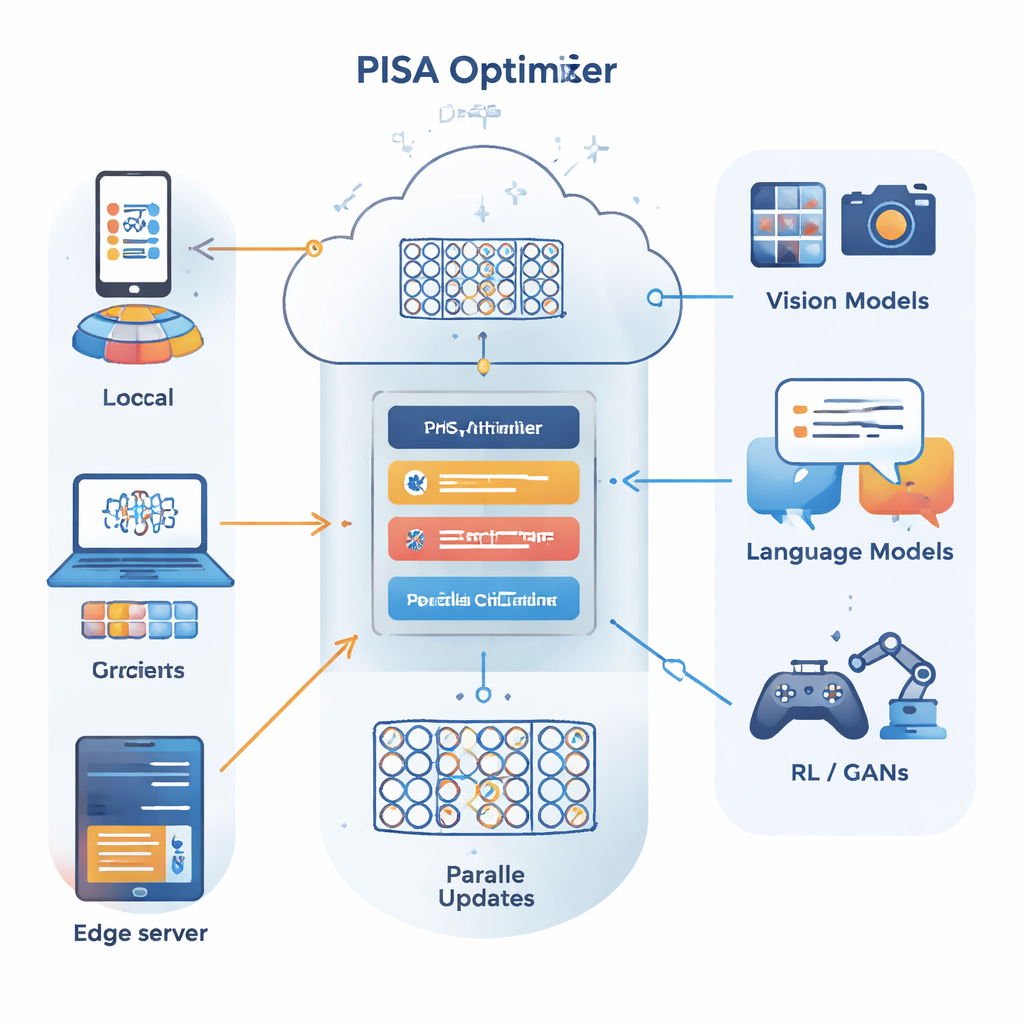
Mocniejsze gwarancje przy łagodniejszych założeniach
Charakterystyczną cechą PISA jest jej teoretyczne uzasadnienie. Autorzy dowodzą, że ich algorytm zbiega się przy jednym, stosunkowo łagodnym założeniu: że gradient funkcji straty jest ciągły Lipschitza w ograniczonym obszarze, co spełniają liczne standardowe funkcje strat dla sieci neuronowych. W przeciwieństwie do większości metod stochastycznych, PISA nie wymaga, aby gradienty były nieobciążone, miały ograniczoną wariancję ani pochodziły z idealnie wymieszanych danych. Pomimo tego zrelaksowanego zestawu założeń, metoda osiąga liniową szybkość zbieżności w sensie stabilizacji wartości funkcji i aktualizacji parametrów, co plasuje ją wśród najlepiej działających algorytmów w porównaniach. Czyni to PISA szczególnie atrakcyjną dla heterogenicznych, niejeduniformowych rozkładów danych, powszechnych w rzeczywistych wdrożeniach.
Praktyczne warianty dla rzeczywistych sieci głębokich
Aby uczynić ramy praktycznymi dla dużych sieci neuronowych, autorzy wprowadzają dwa wydajne warianty: SISA i NSISA. SISA wykorzystuje informacje o drugim momencie — zasadniczo śledząc, jak duże były przeszłe aktualizacje w każdym kierunku parametrów — do tworzenia prostych diagonalnych prekondycjonerów, podobnych do pomysłów stojących za Adamem i RMSProp, lecz osadzonych wewnątrz struktury ADMM. NSISA idzie krok dalej, włączając technikę znaną jako ortogonalizacja Newton–Schulza, inspirowaną optymalizatorem Muon, aby lepiej wyrównywać impet z użytecznymi kierunkami w przestrzeni parametrów. Oba warianty zachowują gwarancje zbieżności PISA, jednocześnie utrzymując obciążenie obliczeniowe na tyle lekkie, by nadawać się na współczesne GPU i duże modele.
Wyniki dla zadań wizji, języka i modeli generatywnych
Autorzy testują SISA i NSISA w szerokim zestawie zadań uczenia głębokiego. W eksperymentach z uczeniem zogniskowanym z celowo przesuniętymi rozkładami etykiet — trudnym scenariuszu, w którym każdy klient widzi tylko podzbiór klas — SISA znacząco przewyższa popularne metody takie jak FedAvg, FedProx, FedNova i Scaffold, osiągając znacznie wyższą dokładność testową na zestawach benchmarkowych takich jak MNIST i CIFAR-10. Dla standardowej klasyfikacji obrazów z modelami takimi jak ResNet i DenseNet na CIFAR-10 i ImageNet, SISA dorównuje lub przewyższa silne optymalizatory, w tym SGD z momentum, AdaBelief i AdamW. Przy dopasowywaniu modeli językowych GPT-2 o rosnących rozmiarach, NSISA osiąga niższe straty walidacyjne w krótszym czasie zegarowym niż wyspecjalizowane optymalizatory takie jak Shampoo, SOAP, Adam-mini i Muon, a przewaga ta staje się bardziej wyraźna dla największych modeli. Stabilizuje także trening sieci generatywnych przeciwników, osiągając niższe wartości miary Fréchet Inception Distance, które oceniają jakość wizualną i różnorodność generowanych obrazów. 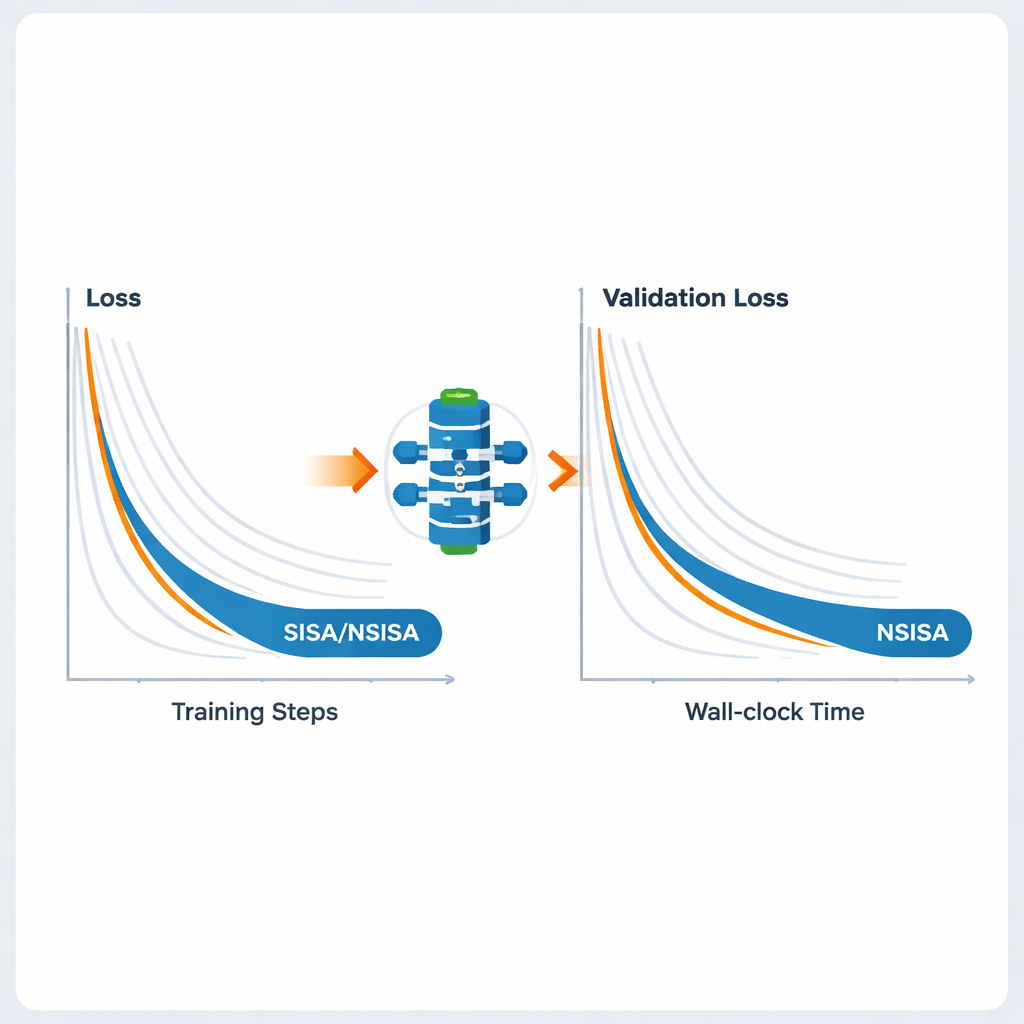
Co to oznacza dla codziennej sztucznej inteligencji
Mówiąc prosto, praca ta pokazuje, że możliwe jest trenowanie potężnych modeli AI szybciej i bardziej niezawodnie, nawet gdy dane są chaotyczne, niezbilansowane lub rozproszone po wielu urządzeniach. Przez przeprojektowanie podstawowego procesu optymalizacji zamiast jedynie dostrajania współczynników uczenia, PISA i jej warianty dostarczają zunifikowane narzędzie działające dobrze w zadaniach wizji, języka, uczenia ze wzmocnieniem i generatywnych. Dla użytkowników końcowych korzyści mogą obejmować inteligentniejszą personalizację na telefonach, bardziej zdolne modele językowe i obrazowe oraz bardziej efektywne wykorzystanie zasobów obliczeniowych w dużych centrach danych — wszystko to dzięki algorytmowi treningowemu lepiej odpowiadającemu realiom współczesnych systemów AI.
Cytowanie: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Słowa kluczowe: optymalizacja uczenia głębokiego, uczenie zogniskowane (federated learning), stochastyczny ADMM, duże modele językowe, heterogeniczne dane