Clear Sky Science · pl
Kiedy duże modele językowe są wiarygodne przy ocenie komunikacji empatycznej
Dlaczego empatia maszyn ma znaczenie dla Ciebie
Coraz częściej ludzie zwracają się do chatbotów i asystentów cyfrowych, gdy są zestresowani, samotni lub muszą podjąć trudne decyzje. Systemy te mogą brzmieć troskliwie i rozumiejąco — ale czy potrafią też ocenić, czy wiadomość rzeczywiście była wspierająca i życzliwa? W tym artykule badamy, kiedy duże modele językowe (LLM), technologia stojąca za wieloma chatbotami, potrafią wiarygodnie ocenić, jak empatyczna wydaje się pisemna odpowiedź, i co to oznacza dla codziennych narzędzi, takich jak aplikacje wellness, wirtualni terapeuci czy boty obsługi klienta. 
Badanie wspierających rozmów
Naukowcy przeanalizowali 200 rzeczywistych rozmów tekstowych, w których jedna osoba opisywała problem osobisty — na przykład stres związany z pracą, konflikty rodzinne, kłopoty finansowe lub trudności ze zdrowiem psychicznym — a druga osoba próbowała odpowiedzieć w sposób wspierający. Rozmowy pochodziły z czterech istniejących zbiorów danych, z których każdy związany był z innym zestawem pytań do oceny empatii. Niektóre skupiały się na tym, czy osoba odpowiadająca okazała zrozumienie lub zapewniła pocieszenie emocjonalne; inne pytały, czy udzieliła praktycznej porady, zachęciła rozmówcę do dalszego mówienia, czy zamiast tego skoncentrowała rozmowę na sobie. Razem te ramy rozkładają „bycie empatycznym” na 21 konkretnych zachowań, które można oceniać na skalach, podobnie jak w ankiecie satysfakcji klienta.
Eksperci, tłum i maszyny
Aby sprawdzić, jak dobrze LLM mogą oceniać empatię, zespół porównał trzy rodzaje sędziów: ekspertów komunikacji, internetowych pracowników tłumu oraz nowoczesne modele językowe. Trzech doświadczonych badaczy w dziedzinie komunikacji empatycznej niezależnie oceniło każdą rozmowę pod kątem wszystkich 21 zachowań. Pracownicy tłumu — zwykli użytkownicy internetu — już wcześniej dostarczyli oceny tych samych wiadomości w wcześniejszych badaniach. Wreszcie, trzy wiodące modele językowe zostały starannie sformułowane przy użyciu wytycznych w prostym języku i przykładowych ocen od ekspertów, a następnie poproszone o ocenę każdej rozmowy według tych samych skal. Taka konfiguracja pozwoliła autorom zmierzyć, jak blisko siebie znajdowały się oceny każdej grupy, nie tylko względem „prawidłowej” odpowiedzi, ale także względem siebie nawzajem. 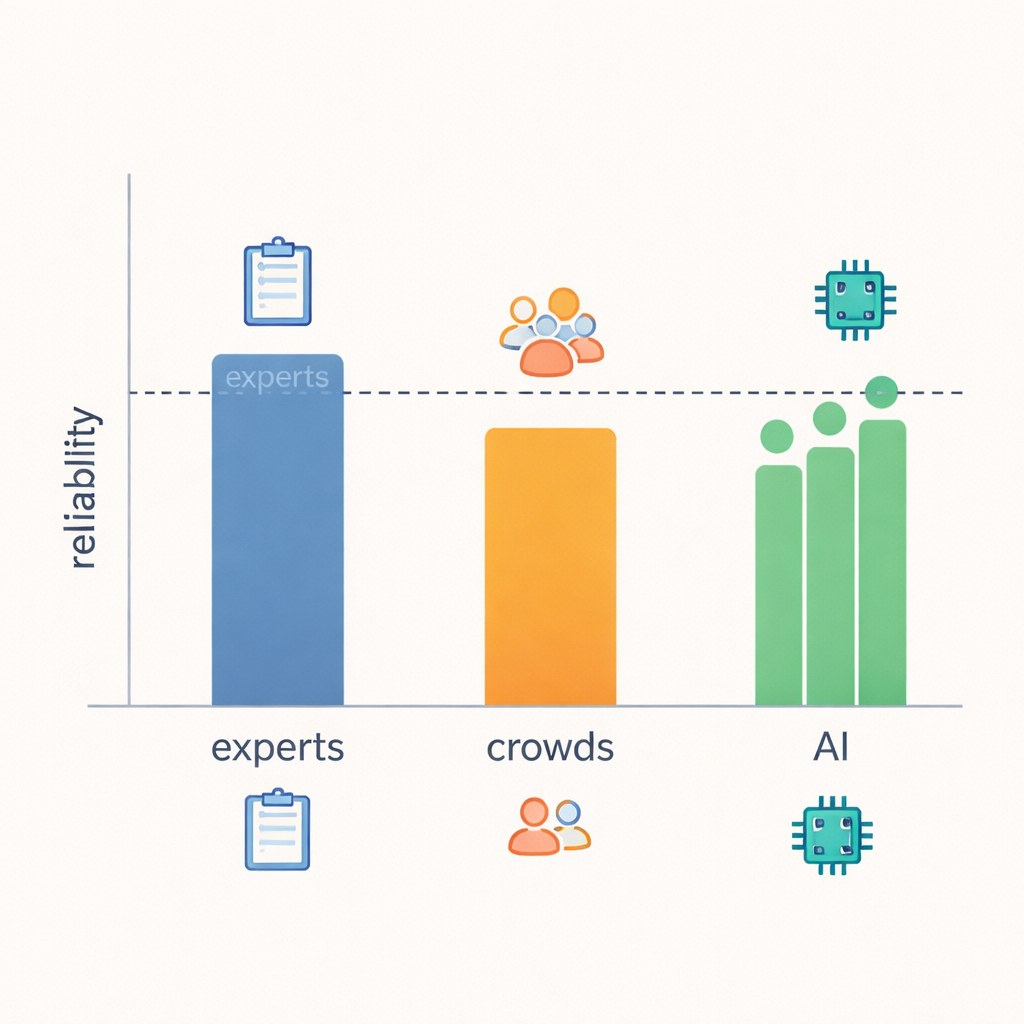
Jak bardzo się zgadzają?
Główne odkrycie jest takie, że LLM-y zaskakująco zbliżyły się do poziomu niezawodności ekspertów. Gdy badacze mierzyli, jak często oceny pokrywały się i jak duże były rozbieżności, modele dorównywały lub prawie dorównywały ekspertom w większości z 21 zachowań i wyraźnie przewyższały pracowników tłumu. W obszarach z wyraźnymi, obserwowalnymi sygnałami — takich jak to, czy odpowiedź udzielała praktycznej porady, zadawała pytania uzupełniające lub kierowała uwagę z powrotem na rozmówcę — eksperci, LLM-y, a nawet tłum zwykle zgadzali się częściej. Jednak przy ocenianiu bardziej nieostrych pojęć, takich jak to, czy odpowiedź rzeczywiście „okazała zrozumienie” lub jakie były intencje odpowiadającego, nawet eksperci częściej się rozbieżali, a wiarygodność LLM-ów spadała wraz z nimi. Sugeruje to, że niektóre aspekty empatii są po prostu trudniejsze do określenia na podstawie samego tekstu, bez względu na to, kto dokonuje oceny.
Dlaczego proste wyniki mogą wprowadzać w błąd
Wiele badań nad AI informuje o sukcesie, używając znanych metryk klasyfikacyjnych — traktując każdą ekspercką ocenę jako bezdyskusyjną prawdę i mierząc, jak często model się z nią zgadza. Autorzy pokazują, że takie podejście może stworzyć zniekształcony obraz przy subtelnych ludzkich ocenach. Na przykład system może osiągać dobre wyniki, zwykle zgadując większościową ocenę na niezrównoważonej skali, nawet jeśli ma problemy w rzadszych, lecz ważnych przypadkach. Podobnie metoda, która najczęściej daje „prawie poprawne” wyniki — różniące się tylko o jeden punkt — może wyglądać słabo przy surowej miarze zgodności, mimo że zachowuje się podobnie do eksperta. Koncentrując się na wiarygodności między oceniającymi — jak spójnie różni sędziowie oceniają to samo — badanie oferuje uczciwszy obraz tego, co zarówno ludzie, jak i maszyny mogą wiarygodnie ocenić.
Co to oznacza dla codziennego AI
Dla laika wniosek jest jednocześnie obiecujący i ostrzegawczy. Dobrze skonfigurowane LLM-y mogą dziś pomagać sprawdzać, czy pisemne odpowiedzi — od ludzkich pomocników lub innych botów — spełniają eksperckie standardy komunikacji empatycznej, i często robią to bardziej konsekwentnie niż nieprzeszkoleni oceniający. To może ułatwić monitorowanie i poprawę chatbotów używanych w opiece zdrowotnej, edukacji i obsłudze klienta. Jednocześnie badanie przestrzega, że nie wszystkie „testy empatii” są jednakowe: niejasne lub nakładające się pytania prowadzą do słabej zgody ludzkiej, a w konsekwencji do niepewnych ocen maszynowych. Zanim zaufamy AI do oceniania czegoś tak delikatnego jak wsparcie emocjonalne, powinniśmy najpierw upewnić się, że sami eksperci potrafią się zgodzić, jak wygląda „dobre” — i użyć tego punktu odniesienia, by zdecydować, gdzie maszyny mogą bezpiecznie pomagać, a gdzie nadal niezbędny jest ludzki osąd.
Cytowanie: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Słowa kluczowe: komunikacja empatyczna, duże modele językowe, towarzysze AI, wsparcie zdrowia psychicznego, interakcja człowiek–AI