Clear Sky Science · pl
Rozplątywanie molekularnych mechanizmów prowadzących do cukrzycy typu 2 w populacjach światowych i w tkankach istotnych dla choroby
Dlaczego warto rozumieć źródła cukrzycy
Cukrzyca typu 2 dotyka setek milionów ludzi na całym świecie, a mimo to wciąż wiemy zaskakująco niewiele o tym, które molekularne przełączniki w organizmie naprawdę powodują chorobę, a które jedynie jej towarzyszą. To badanie zagląda głęboko w nasze DNA i do kilku narządów, by wskazać, które geny i białka faktycznie popychają poziom cukru we krwi w kierunku cukrzycy, a które działają ochronnie. Uwzględniając osoby o zróżnicowanym pochodzeniu oraz analizując kilka kluczowych tkanek, badacze przybliżają nas do precyzyjniejszych strategii prewencji i terapii, które mogą działać dla wielu populacji, a nie tylko dla osób pochodzenia europejskiego.
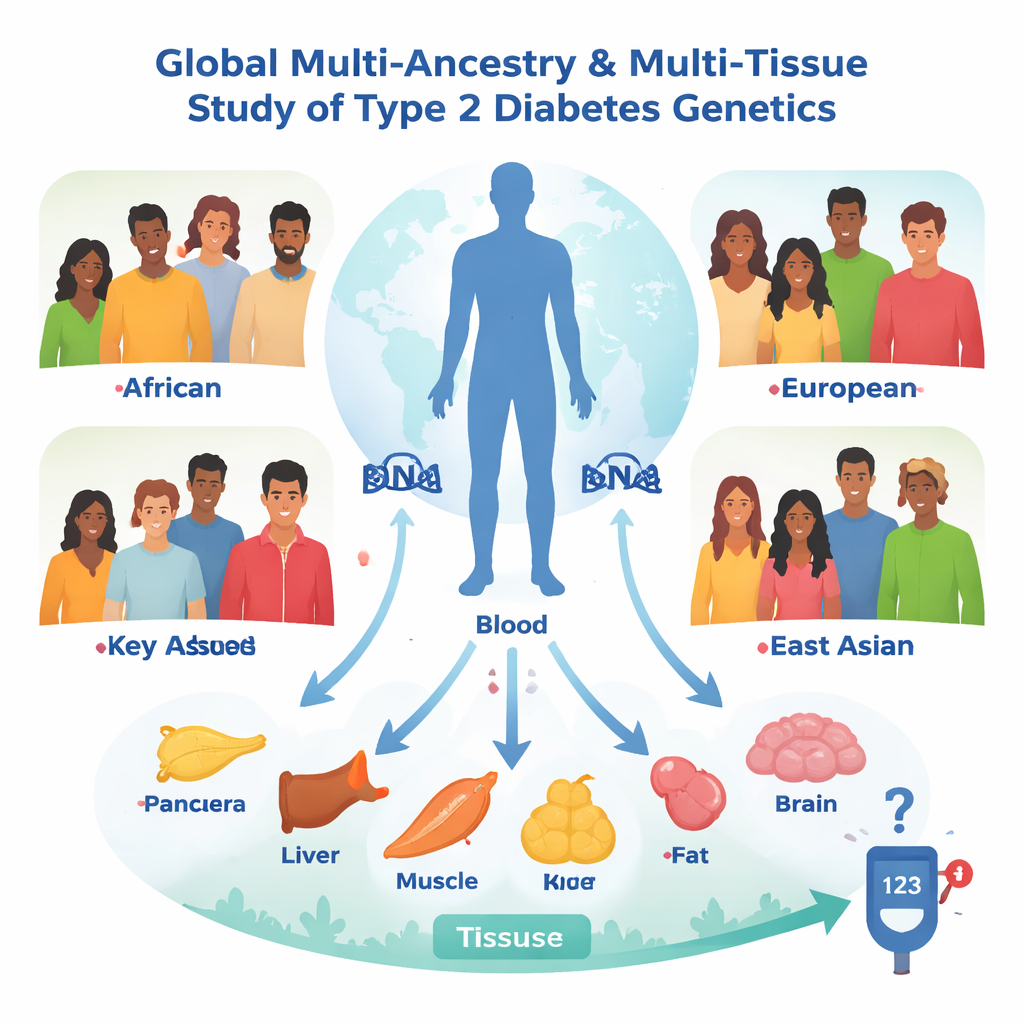
Patrząc przez pryzmat świata i wnętrza ciała
Zespół rozpoczął od danych genetycznych ponad 2,5 miliona osób zgromadzonych przez Type 2 Diabetes Global Genomics Initiative. Zamiast pytać wyłącznie, które warianty DNA są powiązane z cukrzycą, zadali silniejsze pytanie: które warianty zmieniają aktywność konkretnych genów lub białek w organizmie, i czy te zmiany z kolei modyfikują ryzyko cukrzycy? W tym celu zastosowali statystyczne podejście zwane randomizacją Mendla, które traktuje naturalnie występujące różnice genetyczne jak swego rodzaju wbudowane losowane badanie. Przeanalizowali ponad 20 000 miar aktywności genów i więcej niż 1 600 białek krwi u osób z czterech grup pochodzeniowych — europejskiej, afrykańskiej, admiksowanej amerykańskiej i wschodnioazjatyckiej — a następnie powtórzyli analizy w siedmiu tkankach kluczowych dla kontroli poziomu cukru, w tym w trzustce, wyspach produkujących insulinę, wątrobie, mięśniach i różnych depozytach tłuszczu.
Odnajdywanie molekularnych dźwigni zwiększających lub zmniejszających ryzyko
Śledząc te genetyczne ścieżki, badacze zidentyfikowali 335 genów i 46 białek krwi, których genetycznie przewidywane poziomy mają przyczynowy wpływ na ryzyko cukrzycy typu 2, i potwierdzili wiele z tych odkryć w niezależnych kohortach. Niektóre z odnalezionych dźwigni molekularnych były już znanymi podejrzanymi, takimi jak MTNR1B — gen zaangażowany w wydzielanie insuliny z komórek wysp trzustkowych — oraz BAK1, który wpływa na śmierć komórek w trzustce i tkance tłuszczowej. Inne okazały się nowymi lub mniej docenionymi graczami, w tym CPXM1, białko związane z rozwojem tkanki tłuszczowej i opornością na insulinę, oraz HIBCH, gen związany z funkcją mitochondriów. Ogólnie sklasyfikowali 923 geny i 46 białek z dowodami, że zmiana ich aktywności w co najmniej jednej tkance może zmieniać prawdopodobieństwo rozwoju cukrzycy.
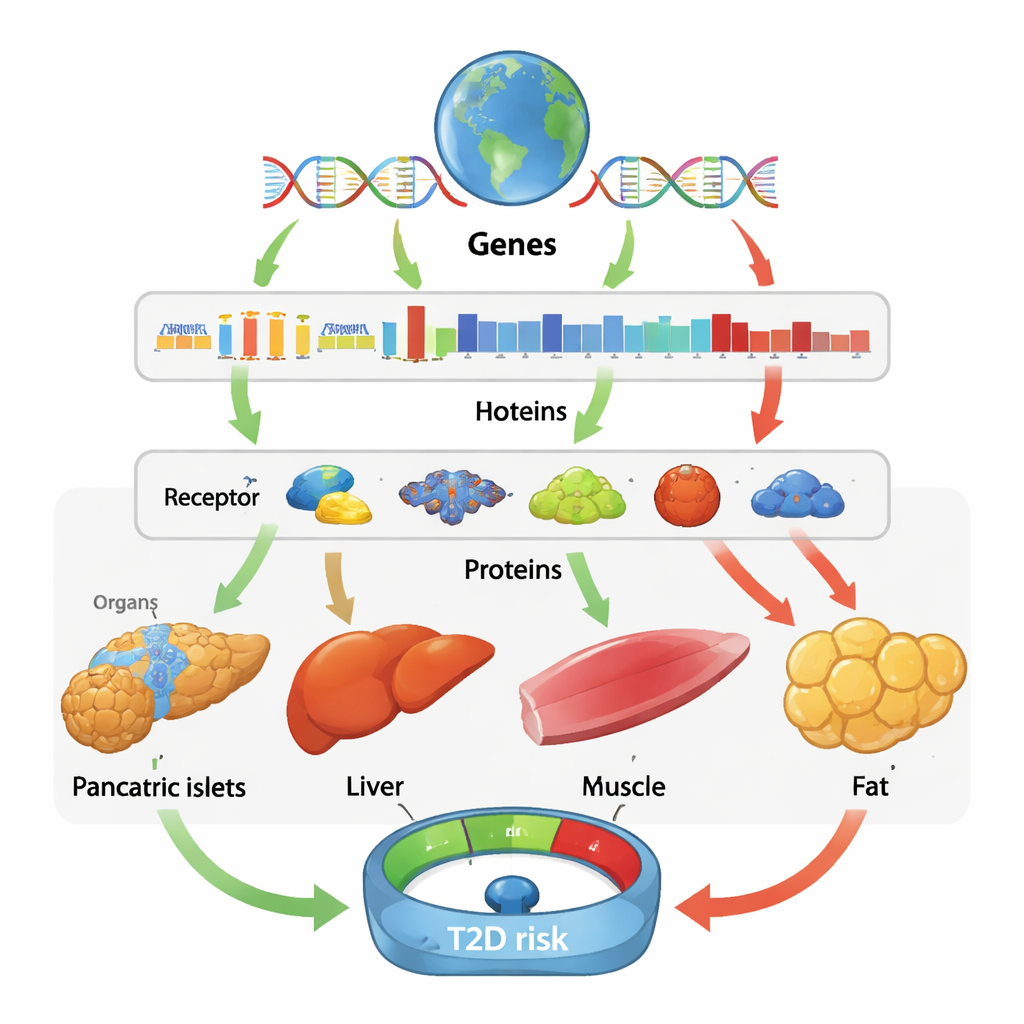
Te same geny, różne historie w różnych tkankach i populacjach
Jedną z uderzających lekcji jest to, że efekt genu często jest silnie specyficzny dla danej tkanki. Na przykład wyższa aktywność BAK1 w trzustce i wyspach wydaje się zwiększać ryzyko cukrzycy, prawdopodobnie przyczyniając się do utraty komórek produkujących insulinę, podczas gdy wyższa aktywność BAK1 w tłuszczu i mięśniach wydaje się być ochronna. HIBCH wykazał podobnie mieszany wzorzec: w niektórych tkankach większa aktywność obniżała ryzyko, a w innych je podnosiła. Te odkrycia pokazują, że badanie wyłącznie krwi może pominąć istotną biologię zachodzącą w narządach, i że ta sama cząsteczka może być korzystna w jednej tkance, a szkodliwa w innej. W przeciwieństwie do tego, porównanie wyników między grupami pochodzeniowymi wykazało stosunkowo niewielkie różnice w wielkości efektów, co sugeruje, że wiele leżących u podstaw mechanizmów przyczynowych jest wspólnych globalnie, chociaż pewne sygnały — takie jak specyficzne białka ochronne lub ryzyka w grupach wschodnioazjatyckich czy afrykańskich — były wykrywalne tylko dzięki danym spoza Europy.
Łączenie nowych odkryć z poznaną biologią cukrzycy
Aby sprawdzić, czy ich podejście ma sens biologiczny, autorzy zestawili swoje geny przyczynowe z kuratorowanymi listami genów związanych z cukrzycą pochodzącymi z badań na ludziach i eksperymentów na myszach. Geny z najsilniejszymi wcześniejszymi dowodami zaangażowania w cukrzycę były znacznie bardziej skłonne wykazywać efekty przyczynowe w ich analizach niż geny wybrane losowo. Co więcej, tkanki, w których pojawiały się te efekty przyczynowe, odpowiadały znanym mechanizmom choroby: geny powiązane z niewydolnością komórek beta miały największe znaczenie w wyspach trzustkowych, podczas gdy geny związane z zespołem metabolicznym ujawniały najsilniejsze efekty w tłuszczu trzewnym (głębokim brzusznym). To dopasowanie wspiera tezę, że zastosowany pipeline statystyczny skutecznie lokalizuje mechanizmy, a nie tylko korelacje.
Co to oznacza dla przyszłego leczenia i prewencji
Dla osób niebędących specjalistami kluczowy wniosek jest taki, że ta praca przekształca długie, bezosobowe listy wariantów DNA w czytelniejszą mapę konkretnych genów, białek i narządów, które rzeczywiście napędzają cukrzycę typu 2. Rozróżniając przyczynę od efektu i ujawniając, kiedy ta sama cząsteczka pełni przeciwne role w różnych tkankach, daje ona twórcom leków bardziej precyzyjne cele i ostrzega, gdzie terapia uniwersalna może zaszkodzić. Co ważne, poprzez świadome włączenie zróżnicowanych populacji, badanie pomaga zapewnić, że przyszłe leki czy wskaźniki ryzyka oparte na tych wynikach będą miały większe szanse działać szeroko, a nie tylko u osób pochodzenia europejskiego.
Cytowanie: Bocher, O., Arruda, A.L., Yoshiji, S. et al. Unravelling the molecular mechanisms causal to type 2 diabetes across global populations and disease-relevant tissues. Nat Metab 8, 506–520 (2026). https://doi.org/10.1038/s42255-025-01444-1
Słowa kluczowe: cukrzyca typu 2, mechanizmy genetyczne, genomika wielonasienna, specyficzna ekspresja genów w tkankach, wnioskowanie przyczynowe