Clear Sky Science · pl
Ulepszanie predykcji kcat dzięki mechanizmowi uwagi świadomej reszt i reprezentacjom wstępnie wytrenowanym
Dlaczego szybsze przewidywanie enzymów ma znaczenie
Enzymy są drobnymi siłami napędowymi, które utrzymują komórki – a także całe gałęzie przemysłu – w działaniu. Przyspieszają reakcje chemiczne napędzające nasz metabolizm, produkują leki i umożliwiają bardziej ekologiczne procesy wytwórcze. Kluczową wartością opisującą szybkość działania enzymu jest liczba obrotów, czyli kcat. Pomiar kcat w laboratorium jest czasochłonny i kosztowny, dlatego naukowcy sięgają po sztuczną inteligencję, by przewidywać go na podstawie sekwencji i informacji o reakcji. W artykule przedstawiono PMAK, nowy model AI, który nie tylko przewiduje kcat dokładniej niż wcześniejsze narzędzia, lecz także pomaga wskazać, które części enzymu są najważniejsze dla jego aktywności.
Od ciężkiej pracy w laboratorium do inteligentnych przewidywań
Tradycyjnie określanie kcat wymaga starannych pomiarów szybkości, z jaką enzym przekształca substrat w produkt w ściśle kontrolowanych warunkach, takich jak ustalona temperatura i pH. Przeprowadzenie takich badań dla tysięcy enzymów jest niepraktyczne, co ogranicza nasze możliwości modelowania całych sieci metabolicznych czy projektowania nowych biokatalizatorów. Wcześniejsze metody komputerowe próbowały wypełnić tę lukę, ale wiele z nich opierało się na ręcznie opracowanych cechach lub uproszczonym obrazie enzymu i pojedynczego substratu. Często działały dobrze tylko wtedy, gdy nowe enzymy były bardzo podobne do tych widzianych w danych treningowych, i miały trudności z prawdziwie nowymi enzymami, nowymi reakcjami czy zmodyfikowanymi mutantami.
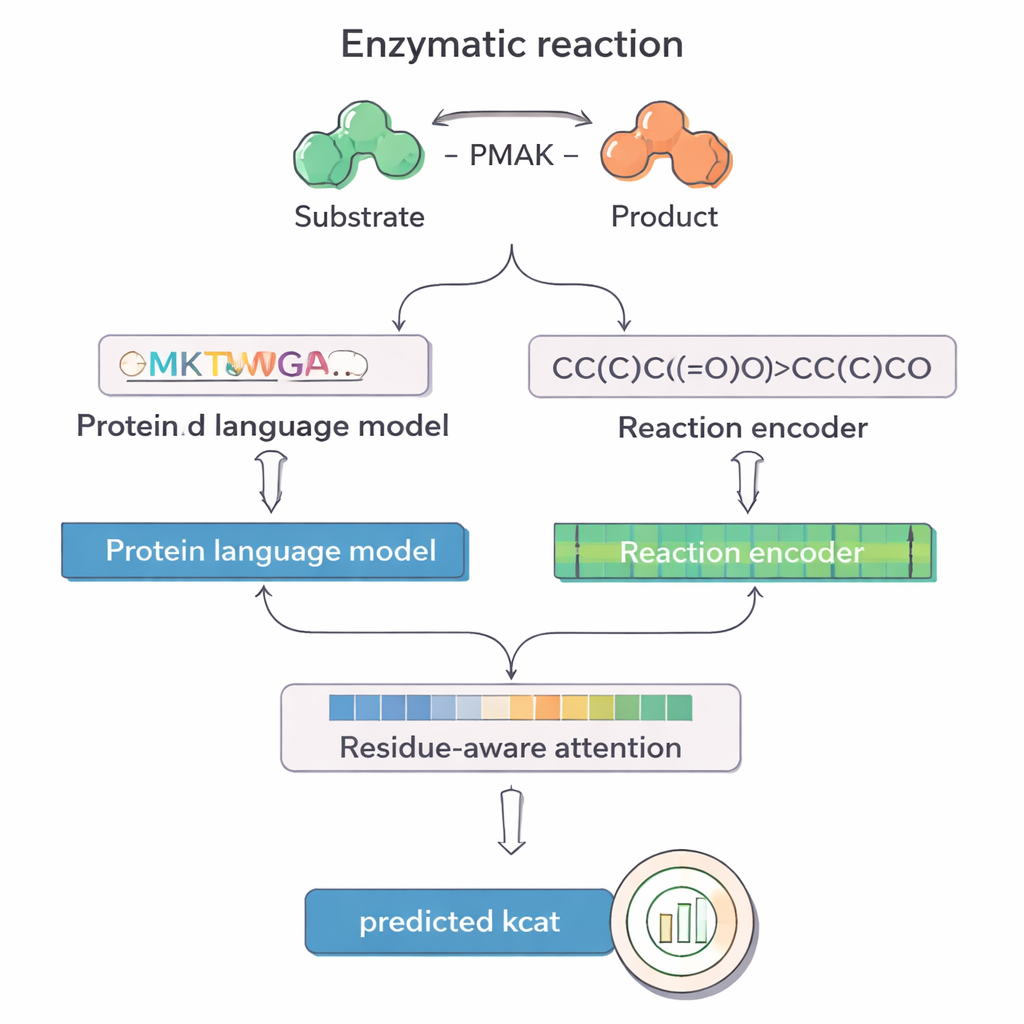
Nauczanie komputerów „języka” enzymów i reakcji
PMAK korzysta z najnowszych osiągnięć w modelach językowych pierwotnie rozwiniętych dla tekstu, lecz dostrojonych na ogromnych zbiorach sekwencji białkowych i reakcji chemicznych. Jeden z modeli, nazwany ProT5, zamienia sekwencję aminokwasową enzymu w bogatą reprezentację numeryczną, która uchwyciła wzorce wyuczone na milionach białek. Inny model, RXNFP, robi to samo dla całych reakcji zapisanych jako łańcuchy SMILES, kodujących wszystkie substraty i produkty. PMAK wprowadza te dwie wyuczone reprezentacje do sieci neuronowej, która wyrównuje ich wymiary i pozwala modelowi rozważać zarówno enzym, jak i pełny kontekst reakcji razem, zamiast traktować je oddzielnie.
Wyróżnianie najważniejszych cegiełek
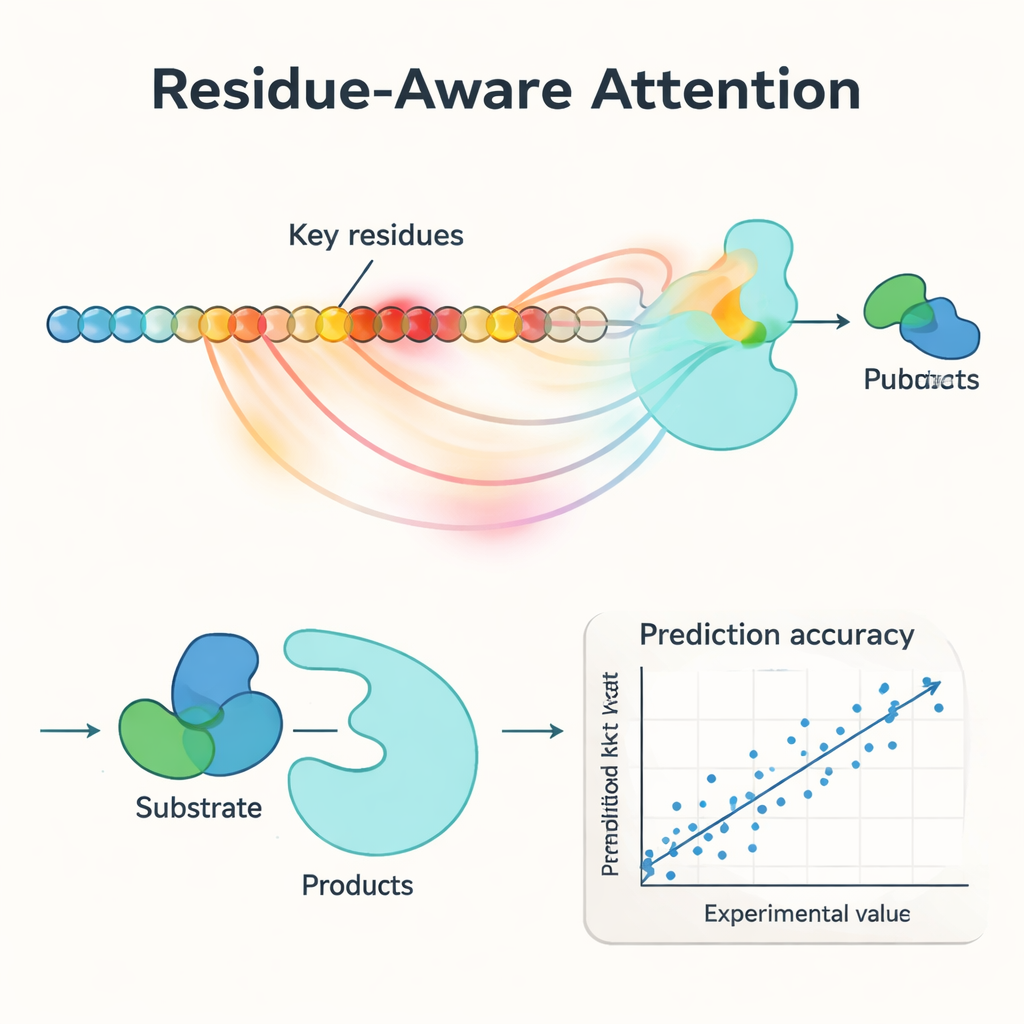
Centralną innowacją w PMAK jest mechanizm „uwagi świadomej reszt”. Zamiast traktować każdy aminokwas w enzymie jako równie istotny, model uczy się przypisywać wyższe wagi konkretnym resztom, które mają największe znaczenie dla danej reakcji. Te wartości uwagi działają jak reflektor na sekwencję: gdy badacze porównali je z znanymi miejscami aktywnymi i wiążącymi z struktur białek, stwierdzili, że PMAK konsekwentnie wyróżniał reszty funkcyjne znacznie częściej niż przy losowym zaznaczaniu. Model dobrze radził sobie również wtedy, gdy miejsca aktywne definiowano szerzej, obejmując sąsiednie reszty w przestrzeni 3D, co sugeruje, że łapie subtelne wskazówki strukturalne i chemiczne istotne dla katalizy.
Dobre wyniki na nowych enzymach, nowych reakcjach i mutantach
Autorzy rygorystycznie przetestowali PMAK na skuratorowanym zbiorze danych zawierającym ponad 4000 wartości kcat obejmujących prawie 3000 enzymów i 2800 reakcji. W warunkach „warm-start” – gdy podobne enzymy i reakcje pojawiają się zarówno w zbiorach treningowych, jak i testowych – PMAK dorównywał lub przewyższał najlepsze istniejące modele. Co ważniejsze, w testach „cold-start”, gdzie enzym lub reakcja w zbiorze testowym nigdy wcześniej się nie pojawiły, PMAK przewyższał szereg wiodących metod. Pozostał użyteczny nawet dla enzymów o bardzo niskim podobieństwie sekwencyjnym do danych treningowych i dla reakcji znacząco różniących się od tych, na których się uczył. PMAK poprawił też przewidywania w realistycznych zastosowaniach, takich jak szacowanie, jak komórki przydzielają ograniczone zasoby białkowe, oraz prognozowanie efektów mutacji w zbiorach danych z inżynierii enzymów.
Co to oznacza dla biologii i biotechnologii
Dla osób spoza specjalności PMAK można postrzegać jako inteligentnego asystenta, który uczy się z ogromnych „bibliotek” białek i reakcji, aby oszacować, jak szybko dany enzym zadziała w określonej reakcji – i wyjaśnić, które aminokwasy napędzają to zachowanie. Dzięki połączeniu lepszej dokładności z wglądem na poziomie reszt, podejście to może pomóc badaczom projektować lepsze enzymy, budować bardziej wiarygodne modele metaboliczne i badać, jak mutacje wpływają na funkcję bez przeprowadzania wszystkich eksperymentów w laboratorium. W miarę jak podobne modele będą rozszerzane na inne cechy kinetyczne, mogą stać się kluczowymi narzędziami do projektowania czystszych procesów przemysłowych, optymalizacji mikroorganizmów dla produkcji zrównoważonej oraz pogłębiania naszego zrozumienia, jak molekularne maszyny życia osiągają swoją niezwykłą szybkość.
Cytowanie: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Słowa kluczowe: kinetyka enzymatyczna, uczenie głębokie, predykcja kcat, inżynieria białek, modelowanie metaboliczne