Clear Sky Science · pl
Model bazowy do inteligentnej chirurgii oparty na szeroko zakrojonym samouczeniu się wideo
Mądrzejsza pomoc na sali operacyjnej
Współcześni chirurdzy coraz częściej polegają na kamerach i komputerach, ale dzisiejsza sztuczna inteligencja nadal ma trudności ze zrozumieniem całego przebiegu operacji. W artykule przedstawiono nowy sposób trenowania AI na tysiącach materiałów wideo z zabiegów, dzięki któremu potrafi lepiej śledzić etapy procedury, rozpoznawać narzędzia i tkanki oraz oceniać, jak bezpiecznie i sprawnie przebiega operacja. W dłuższej perspektywie tego rodzaju technologia mogłaby wspierać chirurgów w czasie rzeczywistym, poprawiać szkolenie i zwiększać bezpieczeństwo pacjentów.
Dlaczego uczenie maszyn o chirurgii jest trudne
Nauczanie komputerów rozumienia chirurgii nie sprowadza się do pokazania kilku oznaczonych zdjęć. Każdy zabieg wiąże się z poruszającymi się kamerami, zmieniającymi się punktami widzenia, dymem, krwią oraz rękami i narzędziami, które stale się zasłaniają. Do tego dochodzi ogromna różnorodność procedur — tysiące rodzajów operacji, z których wiele występuje rzadko. Dokładne oznaczanie wideo klatka po klatce wymaga cennego czasu ekspertów i szybko staje się zbyt kosztowne. Wcześniejsze systemy AI próbowały zmniejszyć ten problem, ucząc się z nieoznakowanych obrazów, ale skupiały się głównie na nieruchomych klatkach i dopiero później dodawały aspekt czasu. W efekcie często nie rozpoznawały rozwijającej się narracji zabiegu: tego, co było wcześniej, co dzieje się teraz i co prawdopodobnie nastąpi.
Uczenie bezpośrednio z chirurgicznych nagrań
Autorzy twierdzą, że AI przeznaczona do wsparcia chirurgii powinna być trenowana na wideo, a nie na izolowanych obrazach. W tym celu zgromadzili jedno z największych dotychczas zbiorów nagrań endoskopowych: 3 650 nagrań zawierających 3,55 miliona klatek, pochodzących z publicznych zestawów badawczych oraz szerokiego przeglądu materiałów chirurgicznych dostępnych online. Materiały obejmują ponad 20 rodzajów procedur i ponad 10 regionów anatomicznych — od usuwania pęcherzyka żółciowego po operacje wątroby i ginekologiczne. Ta różnorodność pozwala AI zobaczyć wiele wariantów rzeczywistego przebiegu zabiegów, w różnych szpitalach, z różnymi narzędziami i stylami kamer.
Nowy plan nauki skoncentrowany na wideo
Wykorzystując ten zasób danych, zespół zaprojektował SurgVISTA — „model bazowy” dostrojony specjalnie do materiałów wideo z operacji. Zamiast próbować oznaczać każdą klatkę, SurgVISTA uczy się przez odtwarzanie brakujących fragmentów. Podczas treningu części klipu wideo są ukrywane, a model musi odtworzyć brakujące obszary. Zmusza go to, by zwracał uwagę na to, jak tkanki, narzędzia i ruchy zmieniają się w czasie. Równocześnie druga część systemu uczy się dopasowywać szczegółowe sygnały wizualne dostarczane przez silny, obrazowy model‑ekspert, który już dużo wie o scenach chirurgicznych. Ta kombinacja pomaga SurgVISTA uchwycić zarówno drobne detale w każdej klatce, jak i szerszy przepływ całej operacji — wszystko w ramach jednej, zunifikowanej sieci.
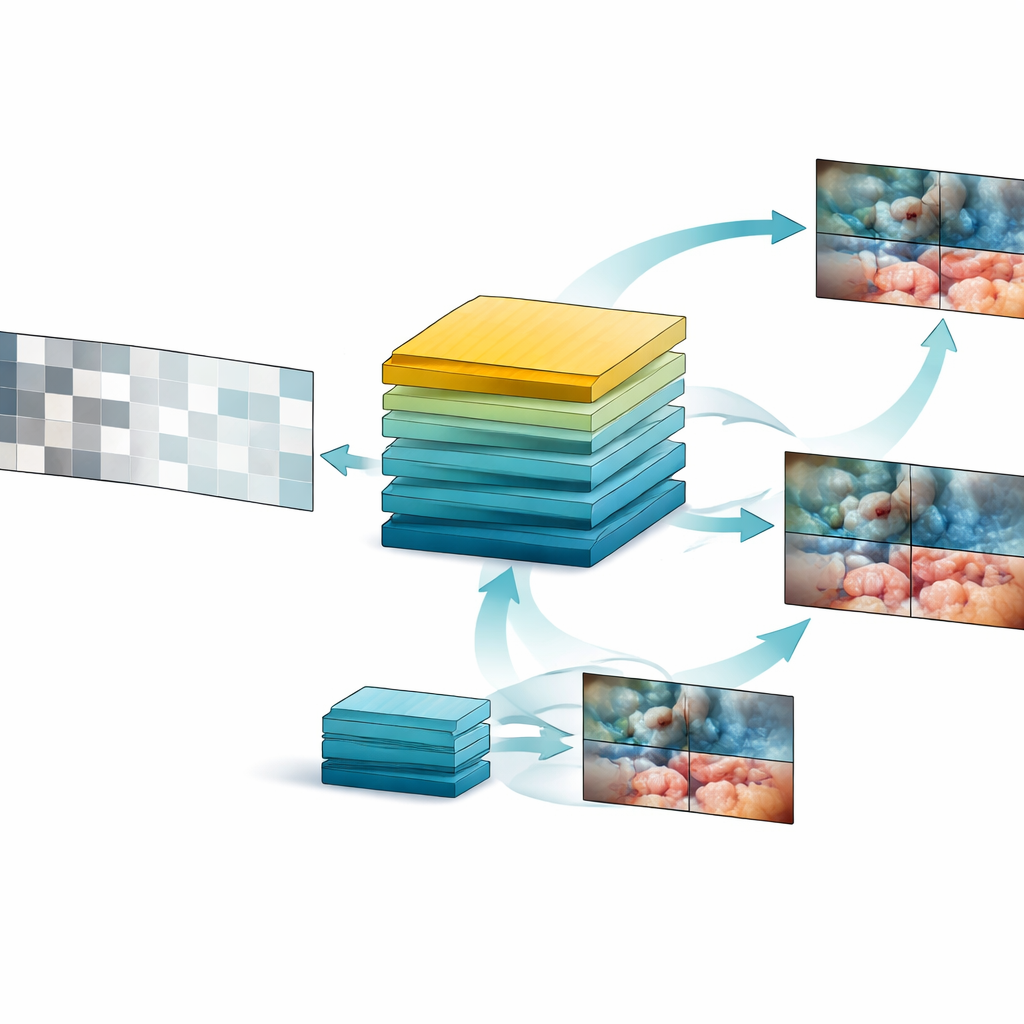
Testy modelu
Aby sprawdzić, czy podejście rzeczywiście przynosi korzyści, autorzy przetestowali SurgVISTA na 13 różnych zbiorach danych obejmujących sześć typów zabiegów i cztery praktyczne zadania. Do zadań należało rozpoznawanie fazy operacji, identyfikacja konkretnych działań chirurgicznych, uchwycenie trójstronnej relacji między narzędziem, akcją i tkanką docelową oraz ocena, jak bezpiecznie wykonano kluczowe kroki. W większości przypadków SurgVISTA przewyższał czołowe modele trenowane na powszednich materiałach wideo, jak również najlepsze istniejące systemy skupione na chirurgii, oparte głównie na nieruchomych obrazach. Dobrze radził sobie nawet w przypadku procedur, których nie widział podczas treningu, pokazując, że wyuczone wzorce nie są uzależnione od jednego organu, zestawu narzędzi czy konkretnego szpitala.
Dlaczego więcej i bogatsze dane wideo mają znaczenie
Badanie analizowało również, jak zmienia się wydajność w miarę dodawania większej ilości danych treningowych. Wraz z stopniowym zwiększaniem rozmiaru i różnorodności puli wideo wyniki SurgVISTA poprawiały się niemal we wszystkich przypadkach, także w procedurach, które w ogóle nie występowały w zbiorze treningowym. Co ciekawe, model zyskiwał nie tylko dzięki większej liczbie przykładów tej samej operacji, lecz także dzięki ekspozycji na różne rodzaje zabiegów: kontakt z odmiennemi „narracjami” chirurgicznymi pomógł mu wyłapać ogólne wzorce wizualne i ruchowe przenoszące się między specjalizacjami. Dodatkowe eksperymenty wykazały, że wsparcie ze strony obrazowego modelu‑eksperta dodatkowo wyostrzało zdolność modelu do zachowania dokładnych detali anatomicznych, co jest kluczowe, by odróżnić np. strukturę życiowo ważną od otaczającej tkanki.
Co to oznacza dla przyszłej chirurgii
Mówiąc wprost, praca pokazuje, że AI trenowana na dużych ilościach rzeczywistych nagrań operacyjnych, z uwzględnieniem przestrzeni i czasu, może zbudować znacznie głębsze rozumienie tego, co dzieje się na sali operacyjnej. SurgVISTA nie jest jeszcze narzędziem podejmującym decyzje samodzielnie, ale dostarcza potężne zaplecze, do którego mogą podłączać się inne aplikacje — czy to do śledzenia postępu zabiegu, sygnalizowania ryzykownych momentów, wspierania szkoleń, czy porównywania technik między szpitalami. Autorzy zauważają, że potrzebne są dalsze, szersze zbiory danych i testy kliniczne, jednak ich wyniki sugerują, że modele bazowe oparte na wideo mogą stać się kluczowym elementem przyszłych inteligentnych systemów chirurgicznych, mających na celu zwiększenie bezpieczeństwa, spójności i dopasowania zabiegów do pacjenta.
Cytowanie: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
Słowa kluczowe: AI do analizy wideo chirurgicznego, uczenie samonadzorowane, przebieg operacji, chirurgia wspomagana komputerowo, modelowanie przestrzenno‑czasowe