Clear Sky Science · pl
Modele uczenia maszynowego do przewidywania interakcji między lekami: od odkryć obliczeniowych do zastosowań klinicznych
Dlaczego łączenie leków może być ryzykowne
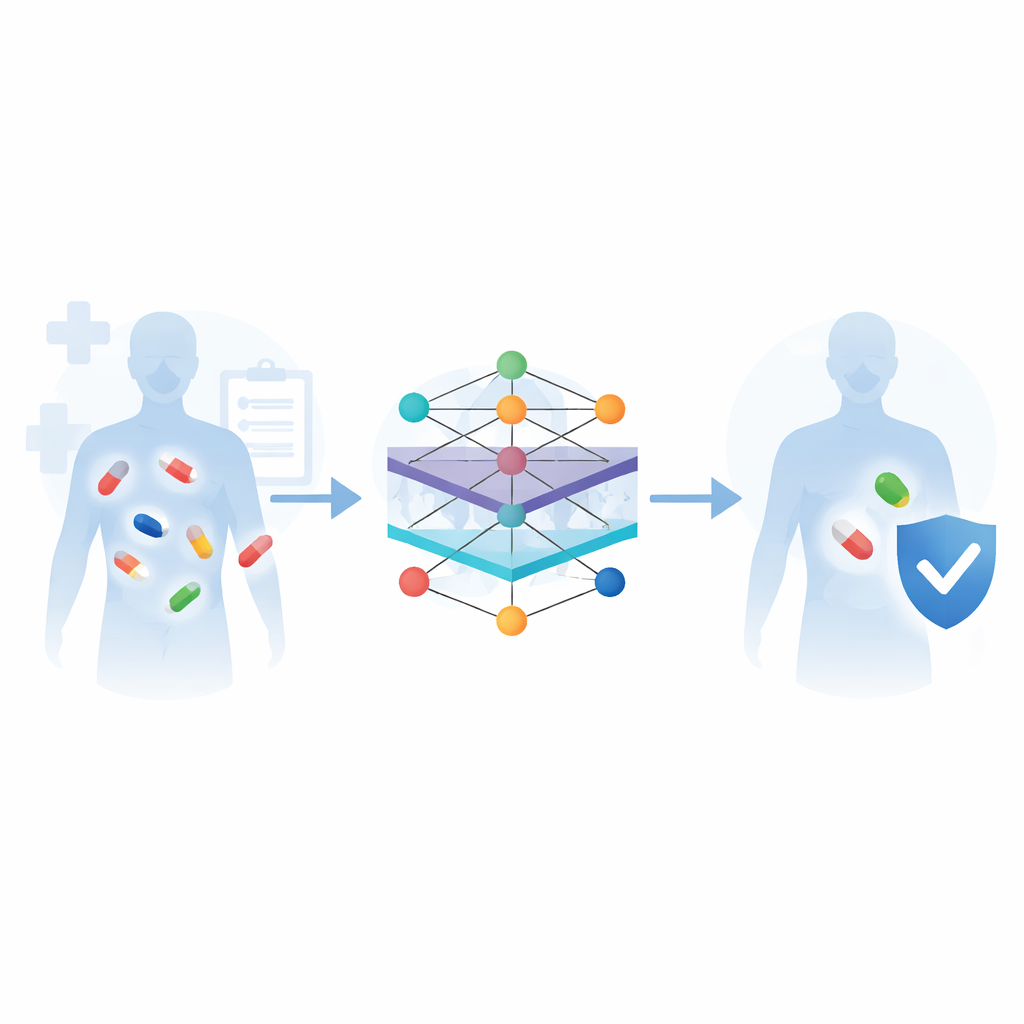
Współczesna medycyna często polega na przyjmowaniu kilku leków jednocześnie — w onkologii, chorobach serca, infekcjach lub po prostu w leczeniu wielu schorzeń związanych z wiekiem. Gdy leki spotykają się w organizmie, mogą wzajemnie zmieniać swoje działanie, czasem osłabiając terapię, a innym razem czyniąc ją niebezpieczną. Ten przegląd opisuje, jak sztuczna inteligencja, a szczególnie nowoczesne metody uczenia maszynowego, służy do przewidywania tych interakcji z wyprzedzeniem, aby lekarze mogli wybierać bezpieczniejsze kombinacje i dopasowywać leczenie do indywidualnych pacjentów.
Od prób i błędów do bezpieczeństwa opartego na danych
Tradycyjnie niebezpieczne kombinacje leków odkrywano w trudny sposób — podczas późnych etapów badań klinicznych lub dopiero po wprowadzeniu leku na rynek, gdy pacjenci doznawali szkód. Badania laboratoryjne na komórkach, zwierzętach i ochotnikach pozostają złotym standardem, ale są powolne, kosztowne i niemożliwe do zastosowania dla ogromnej liczby potencjalnych par leków. Autorzy argumentują, że przewidywania obliczeniowe oferują wyjście z tego wąskiego gardła. Ucząc się na ogromnych cyfrowych zbiorach informacji o lekach — takich jak struktury chemiczne, cele w organizmie, znane działania niepożądane i raporty o niepożądanych reakcjach z rzeczywistej praktyki — systemy uczące się mogą wykrywać ryzykowne pary na długo przed tym, jak dotrą do dużej liczby pacjentów.
Jak maszyny uczą się na różnych rodzajach danych o lekach
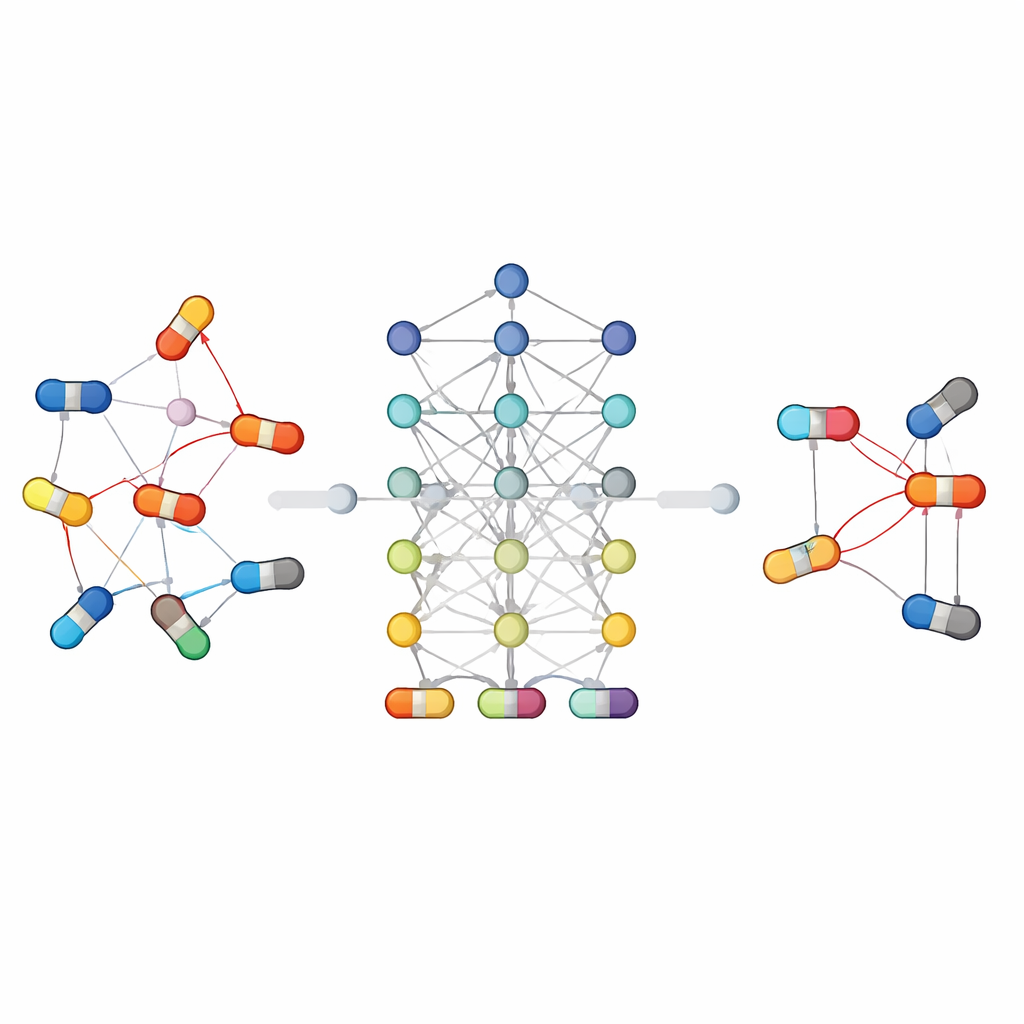
Przegląd wyjaśnia typowy przepływ pracy tych systemów predykcyjnych. Najpierw zbierane są informacje z głównych baz biomedycznych: biblioteki chemiczne opisujące wygląd cząsteczek, mapy szlaków metabolicznych pokazujące, jak leki są przetwarzane w organizmie, oraz kwerendowane listy znanych interakcji i działań niepożądanych. Następnie algorytmy przekształcają te surowe dane w postać liczbową zrozumiałą dla komputerów — na przykład mierząc podobieństwo dwóch leków albo reprezentując każdy lek jako węzeł w sieci połączony z jego celami, szlakami i wcześniejszymi reakcjami. Różne modele uczenia maszynowego są potem trenowane, by rozpoznawać, które pary leków mają tendencję do wywoływania problemów, a ich wydajność jest oceniana na zestawach benchmarkowych przy użyciu standardowych miar dokładności.
Różne rodziny algorytmów rozwiązują problem na własny sposób
Ponieważ interakcje leków są złożone, żaden pojedynczy typ modelu nie jest najlepszy we wszystkich sytuacjach. Niektóre podejścia opierają się na tradycyjnych klasyfikatorach korzystających z cech zaprojektowanych ręcznie, inne uczą się bezpośrednio ze struktury cząsteczek lub sieci powiązań między lekami a elementami biologicznymi. Metody oparte na grafach i głębokim uczeniu odniosły szczególne sukcesy: traktują leki i ich relacje jako sieć, pozwalając algorytmowi „wnioskować” na podstawie łańcuchów powiązań, które mogą być niewidoczne dla prostszych modeli. Inne strategie dzielą informacje między powiązane zadania, na przykład przewidywanie zarówno czy dwie substancje wchodzą w interakcję, jak i jaki rodzaj efektu wywołują, co pomaga, gdy danych jest mało. Artykuł wskazuje także nowe kierunki, takie jak duże modele językowe czytające teksty naukowe i notatki kliniczne, oraz modele generatywne eksplorujące możliwe wzorce interakcji w bardzo dużych, rozrzedzonych zbiorach danych.
Łączenie komputerowych prognoz z rzeczywistymi pacjentami
Poza metodami artykuł podkreśla, jak te narzędzia mogą wspierać opiekę w świecie rzeczywistym. Autorzy omawiają, jak modele trenowane na skuratowanych bazach danych i zapisach klinicznych mogą ostrzegać klinicystów o niebezpiecznych kombinacjach przy łóżku pacjenta, pomagać projektować bezpieczniejsze schematy wielolekowe w onkologii, kardiologii i chorobach zakaźnych oraz priorytetyzować, które przewidywane interakcje wymagają badań laboratoryjnych. Przegląd obejmuje też klasyczne przykłady kliniczne — takie jak antybiotyki zmieniające poziomy leków obniżających cholesterol, środki przeciwbólowe znoszące nawzajem swoje działanie czy soki owocowe niespodziewanie zwiększające stężenia leków — aby pokazać liczne drogi, przez które powstają interakcje. Systemy uczące się, które wychwytują te wzorce, mogą więc działać jako wczesne systemy ostrzegawcze, zwłaszcza u starszych pacjentów przyjmujących wiele leków.
Wyzwania na drodze do zaufanej sztucznej inteligencji w medycynie
Pomimo imponującej dokładności na zestawach testowych, autorzy podkreślają, że obecne modele nadal stoją przed istotnymi przeszkodami, zanim będzie można ufać im w powszechnej praktyce klinicznej. Wiele z nich to „czarne skrzynki”, które niewiele wyjaśniają na temat przyczyny ocenienia danej pary jako ryzykownej, co utrudnia lekarzom ocenę lub wytłumaczenie rekomendacji. Modele mogą zawodzić, gdy dane są hałaśliwe lub niezrównoważone — na przykład gdy szkodliwe interakcje są rzadkie w porównaniu z bezpiecznymi parami. Integracja informacji z chemii, genetyki, elektronicznych kart zdrowia i literatury naukowej jest technicznie trudna, a ramy regulacyjne wymagają mocnych dowodów, zanim takie narzędzia będą mogły wpływać na przepisywanie leków. Według autorów przyszłe prace powinny skupić się na bardziej interpretowalnych modelach, lepszym radzeniu sobie ze zniekształconymi i niekompletnymi danymi oraz systemach, które mogą nieustannie uczyć się na podstawie nowych doświadczeń klinicznych z poszanowaniem prywatności i zasad bezpieczeństwa.
Co to oznacza dla codziennego leczenia
Mówiąc wprost, przegląd pokazuje, że sztuczna inteligencja staje się potężnym sojusznikiem w utrzymaniu bezpieczeństwa łączeń leków. Przesiewając góry danych cyfrowych znacznie wykraczających poza możliwości pojedynczego eksperta, modele uczenia maszynowego mogą wskazywać niebezpieczne pary, sugerować bezpieczniejsze alternatywy i wspierać bardziej spersonalizowane przepisywanie. Te narzędzia nie zastąpią osądu klinicznego ani starannych badań laboratoryjnych, ale mogą pomóc upewnić się, że rosnąca złożoność współczesnej terapii nie odbywa się kosztem bezpieczeństwa pacjentów.
Cytowanie: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Słowa kluczowe: interakcje między lekami, uczenie maszynowe w medycynie, grafowe sieci neuronowe, farmakologia kliniczna, bezpieczeństwo sztucznej inteligencji