Clear Sky Science · pl
Duże modele językowe poprawiają przenaszalność prognoz opartych na elektronicznej dokumentacji medycznej między krajami i systemami kodowania
Dlaczego inteligentniejsze udostępnianie danych medycznych ma znaczenie
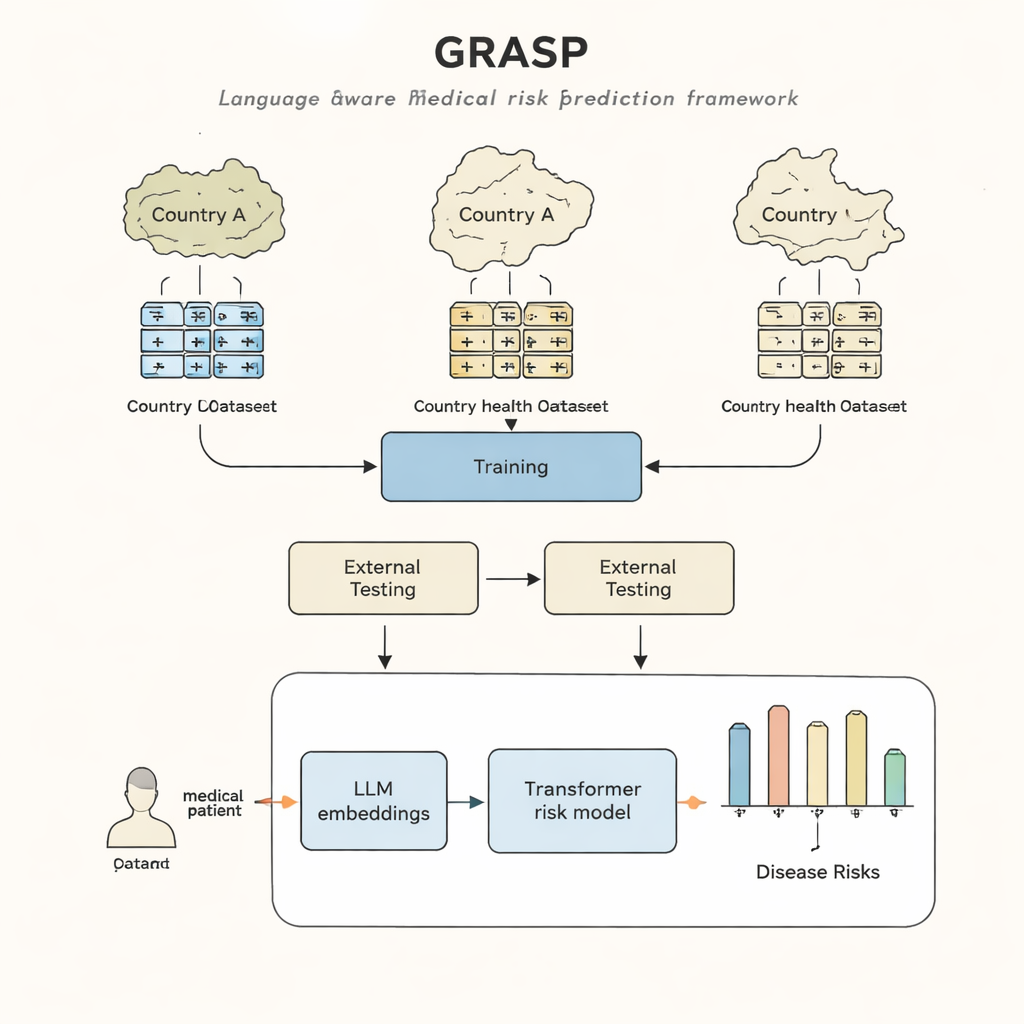
Szpitale i przychodnie na całym świecie dysponują kopalnią informacji: elektroniczną dokumentacją medyczną, która rejestruje diagnozy, leczenie i wyniki pacjentów przez wiele lat. Teoretycznie te dane mogłyby pomóc lekarzom wcześnie zidentyfikować osoby o wysokim ryzyku poważnych chorób, na długo przed pojawieniem się oczywistych objawów. W praktyce jednak współczesne modele komputerowe mają trudności z „przemieszczaniem się” między krajami czy systemami szpitalnymi, ponieważ każde miejsce zapisuje dane zdrowotne inaczej. W tym badaniu przedstawiono nowe podejście, nazwane GRASP, które wykorzystuje postępy w sztucznej inteligencji do pokonania tych różnic, aby model wytrenowany w jednym systemie opieki zdrowotnej mógł działać wiarygodnie w innych.
Różne szpitale, różne „języki”
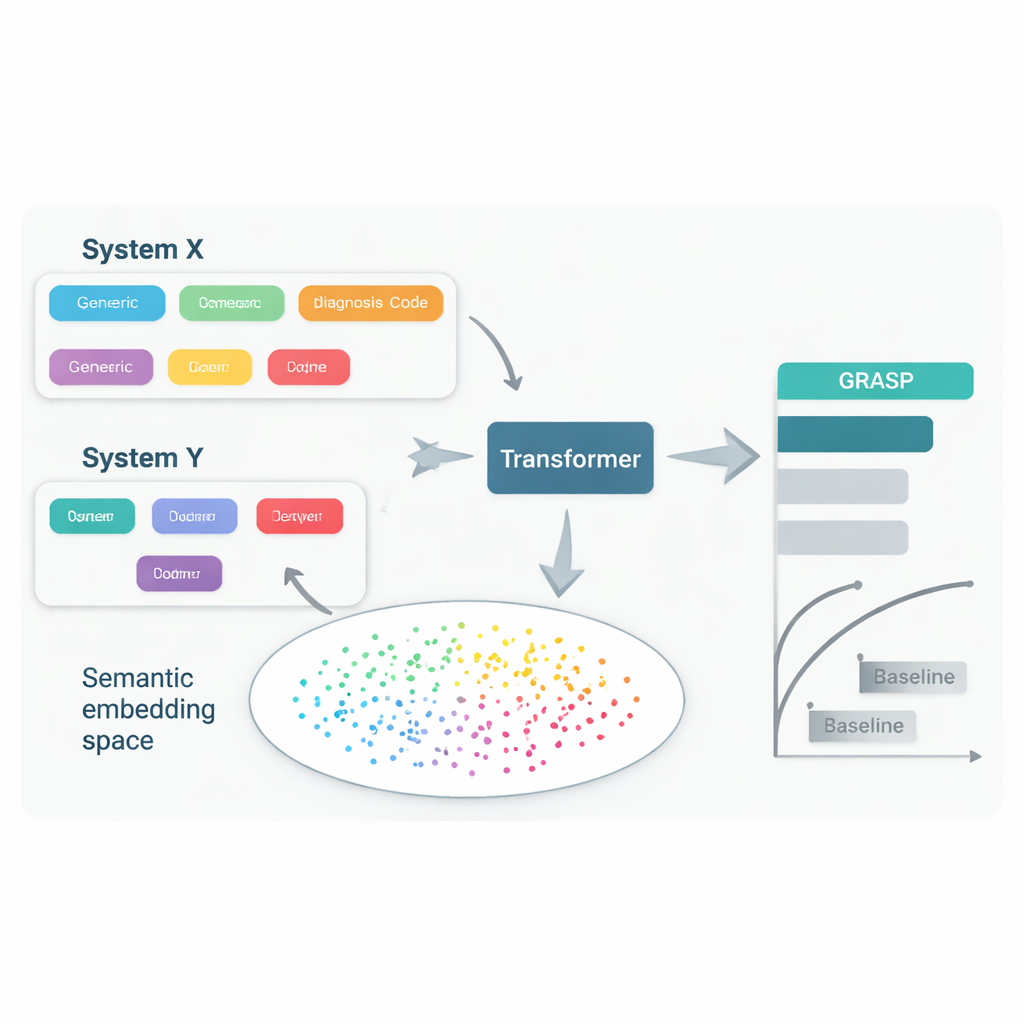
Nawet gdy lekarze leczą tę samą chorobę, często używają różnych systemów kodowania i lokalnych zwyczajów przy jej zapisie w dokumentacji. Jeden szpital może przechowywać „wysoki poziom cukru we krwi” pod jednym kodem, inny użyje innego kodu dla „hiperglikemii”, a trzeci korzysta z zupełnie innego systemu. Próby zmuszenia wszystkich do jednego wspólnego standardu — na przykład dużych międzynarodowych schematów kodowania — są przydatne, ale powolne, kosztowne i nadal pozostawiają istotne różnice. W efekcie model komputerowy przewidujący choroby na podstawie zapisów z jednego kraju może tracić na dokładności po zastosowaniu gdzie indziej, co ogranicza korzyści płynące z tych narzędzi.
Pozwolić AI czytać znaczenie, a nie tylko kod
Podejście GRASP wychodzi od prostej idei: zamiast traktować każdy kod medyczny jako pozbawiony znaczenia numer identyfikacyjny, pozwól dużemu modelowi językowemu odczytać jego ludzkie opisanie, takie jak „ostra infekcja górnych dróg oddechowych”, i przekształcić to znaczenie w numeryczne „osadzenie” (embedding). Takie osadzenia umieszczają powiązane pojęcia blisko siebie w wspólnej przestrzeni, nawet jeśli pochodzą z różnych systemów kodowania czy krajów. GRASP uprzednio oblicza takie osadzenia dla milionów standardowych terminów medycznych i przechowuje je w tabeli wyszukiwania. Historia medyczna pacjenta jest następnie reprezentowana jako seria tych bogatych wektorów, które trafiają do sieci typu transformer — rodzaju sieci neuronowej dobrze nadającej się do przetwarzania zbiorów zróżnicowanych wejść — aby oszacować ryzyko danej osoby dla 21 głównych chorób oraz ogólne ryzyko śmierci.
Testowanie między krajami i systemami zapisów
Naukowcy wytrenowali GRASP na danych z blisko 400 000 uczestników z UK Biobank, a następnie przetestowali go bez ponownego trenowania w dwóch bardzo różnych środowiskach: projekcie FinnGen w Finlandii oraz w dużej sieci szpitali w Nowym Jorku. GRASP dorównał lub przewyższył silne alternatywy, w tym popularną metodę XGBoost i podobny transformer, który nie korzystał z osadzeń opartych na języku. W Finlandii GRASP wypadł szczególnie dobrze, wykazując wyraźne korzyści dla schorzeń takich jak astma, przewlekła choroba nerek i niewydolność serca. Co zaskakujące, nawet gdy amerykańskie dane szpitalne pozostały w innym systemie kodowania zamiast być konwertowane do wspólnego standardu, GRASP wciąż dostarczał lepsze prognozy niż same dane demograficzne, ponieważ potrafił dopasować kody wyłącznie na podstawie zrozumienia treści ich opisów.
Więcej z mniejszej ilości danych
Inną zaletą GRASP jest efektywność. Ponieważ model językowy już nauczył się, że wiele pojęć medycznych jest powiązanych, sieć predykcyjna nie musi od nowa odkrywać tych powiązań. Gdy autorzy trenowali GRASP na znacznie mniejszych podzbiorach danych z Wielkiej Brytanii — aż do zaledwie 10 000 osób — wciąż przewyższał konkurencyjne modele trenowane na tych samych ograniczonych próbkach, zarówno w Wielkiej Brytanii, jak i podczas transferu za granicę. Wyniki ryzyka GRASP były także bliżej powiązane z dziedziczonym genetycznym ryzykiem kilku chorób, co sugeruje, że model uchwytuje głębsze aspekty podatności na choroby, a nie tylko zapamiętuje wzorce z jednego zbioru danych.
Co to oznacza dla przyszłej opieki
Dla osób niezajmujących się specjalistycznie tą dziedziną kluczowy przekaz jest taki, że GRASP pokazuje, jak nowoczesne, oparte na języku metody AI mogą pomóc różnym systemom opieki zdrowotnej „mówić tym samym językiem” bez przymuszania ich do jednego sztywnego schematu kodowania. Czytając znaczenie terminów medycznych, GRASP może tworzyć prognozy ryzyka chorób, które lepiej uogólniają się między krajami i formatami zapisów, i robić to przy mniejszej liczbie przykładów pacjentów. Choć metoda wciąż wymaga starannych testów, rekalkibracji i kontroli pod kątem równości zanim zostanie użyta w codziennej opiece, wskazuje na przyszłość, w której potężne narzędzia ryzyka opracowane w jednym miejscu mogą być bezpiecznie i efektywnie udostępniane szpitalom i klinikom na całym świecie.
Cytowanie: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Słowa kluczowe: elektroniczna dokumentacja medyczna, prognozowanie ryzyka chorób, duże modele językowe, udostępnianie danych medycznych, AI w opiece zdrowotnej