Clear Sky Science · pl
Porównanie zdecentralizowanego uczenia maszynowego i klinicznych modeli AI z lokalnymi i scentralizowanymi alternatywami: przegląd systematyczny
Dlaczego ważne jest dzielenie się wiedzą medyczną bez udostępniania danych
Współczesna medycyna coraz częściej opiera się na sztucznej inteligencji do wcześniejszego wykrywania chorób, wyboru odpowiedniego leczenia i przewidywania, kto jest najbardziej narażony na ryzyko. Najlepsze narzędzia AI potrzebują jednak ogromnych ilości danych pacjentów, a szpitale nie mogą po prostu łączyć swoich rejestrów ze względu na surowe przepisy o prywatności i kwestie etyczne. Ten artykuł przegląda ponad dekadę badań nad „zdecentralizowanym” uczeniem — sposobami, dzięki którym placówki medyczne mogą wspólnie szkolić AI, nigdy nie udostępniając surowych danych pacjentów — i stawia praktyczne pytanie: jak dobrze te metody chroniące prywatność radzą sobie w porównaniu z tradycyjnymi podejściami?
Nowe sposoby uczenia się od pacjentów przy jednoczesnej ochronie prywatności
W tradycyjnym uczeniu scentralizowanym szpitale kopiują wszystkie swoje dane do jednej dużej bazy i tam trenują pojedynczy model. W uczeniu lokalnym każda instytucja buduje własny model na swoich danych, bez współpracy. Zdecentralizowane uczenie oferuje środkową drogę. W uczeniu federacyjnym, na przykład, każdy szpital trenuje model lokalnie, a następnie przesyłane są jedynie ustawienia modelu (jak „pokrętła” w sieci neuronowej), które są łączone w model wspólny; rekordy pacjentów nigdy nie opuszczają placówki. Swarm learning usuwa centralnego koordynatora i pozwala instytucjom bezpośrednio wymieniać się aktualizacjami modeli. Inne podejścia zdecentralizowane łączą przewidywania z wielu lokalnych modeli albo dzielą model między strony. Metody te testowano w zadaniach od wykrywania raka i diagnozy COVID‑19 po choroby serca, cukrzycę, zaburzenia mózgu i schorzenia psychiatryczne.
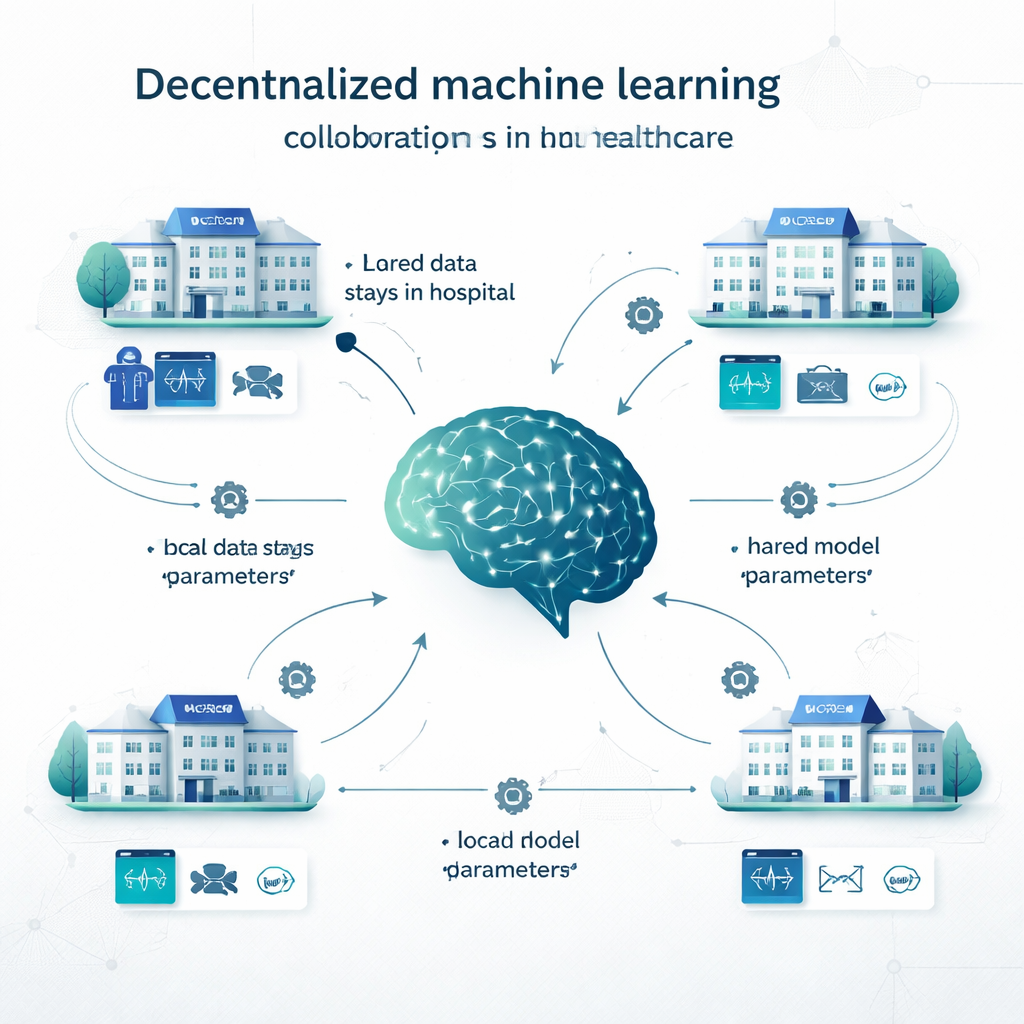
Co badacze przeanalizowali
Autorzy systematycznie przeszukali 11 głównych baz danych i przesiewowo przejrzeli 165 010 prac opublikowanych między 2012 a marcem 2024 r. Po usunięciu duplikatów i badań, które nie dotyczyły rzeczywistych decyzji klinicznych, pozostało 160 artykułów. Łącznie te prace opisały 710 modeli zdecentralizowanych i 8 149 bezpośrednich porównań wydajności w stosunku do modeli scentralizowanych lub lokalnych. Większość badań koncentrowała się na diagnostyce, ale było też wiele badań nad segmentacją obrazów (np. wyznaczanie granic guzów), przewidywaniem przyszłych wyników, takich jak przeżycie czy powikłania, oraz zadaniami mieszanymi. Typy danych objęły niemal każde główne źródło wykorzystywane w medycynie: elektroniczne rekordy zdrowotne, skany CT i MRI, zdjęcia rentgenowskie, cyfrowe skrawki patologiczne, sygnały serca i mózgu, a nawet dane genetyczne.
Jak modele chroniące prywatność wypadają w porównaniu ze scentralizowaną AI
Gdy modele zdecentralizowane porównywano z modelami scentralizowanymi trenowanymi na połączonych danych, uczenie scentralizowane zazwyczaj wychodziło nieco lepiej. Szczególnie dobrze radziło sobie w miarach progowych, takich jak trafność (accuracy) i często stosowany w obrazowaniu współczynnik Dice, wygrywając około trzy czwarte przypadków i przewagą wystarczającą, by uznać ją za umiarkowaną do dużej. Jednak w miarach rankingowych — takich jak pole pod krzywą ROC (AUROC), które ocenia, jak dobrze model porządkuje pacjentów od niższego do wyższego ryzyka — modele zdecentralizowane i scentralizowane były znacznie bliższe, z niewielką przewagą treningu scentralizowanego. Co ważne, gdy oba modele osiągały to, co autorzy nazywają „klinicznie akceptowalną” wydajnością (wynik co najmniej 0,80), typowy zysk modelu scentralizowanego był umiarkowany: często mniej niż 1–1,5 punktu procentowego. W wielu sytuacjach oznaczało to „doskonały versus akceptowalny”, a nie „użyteczny versus bezużyteczny”.
Dlaczego zdecentralizowane uczenie przewyższa działanie w pojedynkę
Najjaśniejszy sygnał w przeglądzie pojawił się przy porównaniu modeli zdecentralizowanych z czysto lokalnymi. We wszystkich głównych miarach — trafność, AUROC, F1, czułość, swoistość i szczególnie precyzja — metody zdecentralizowane prawie zawsze wypadały lepiej, często z dużą przewagą. W bezpośrednich testach zdecentralizowane uczenie przewyższało modele lokalne w ponad 80% porównań dla kluczowych miar, takich jak trafność, precyzja i AUROC. W wielu przypadkach modele lokalne nie osiągały progu 0,80 dla użyteczności klinicznej, podczas gdy odpowiadający im model zdecentralizowany przekraczał go z zapasem, poprawiając czułość nawet o 27 punktów procentowych. Autorzy przypisują to szerszemu doświadczeniu, które zdobywają modele wielostanowiskowe: „widząc” wzorce z wielu szpitali, są mniej zwodzone przez specyficzne dla danej placówki niuanse w urządzeniach obrazujących czy prowadzeniu dokumentacji i lepiej wychwytują cechy chorób, które naprawdę uogólniają się między ośrodkami.
Równoważenie wydajności, prywatności i praktycznego zastosowania
Przegląd konkluduje, że uczenie scentralizowane pozostaje złotym standardem, gdy przepisy o prywatności i logistyka pozwalają na połączenie danych oraz gdy każda ułamkowa różnica w wydajności ma znaczenie, na przykład w bardzo rzadkich chorobach. Jednak zdecentralizowane uczenie stanowi silną i klinicznie akceptowalną alternatywę w sytuacjach, gdy udostępnianie danych jest ograniczone przez przepisy takie jak RODO i rozporządzenia UE dotyczące AI, albo przez polityki instytucjonalne. W porównaniu z utrzymywaniem modeli wyłącznie lokalnie, podejścia zdecentralizowane przynoszą duże korzyści zarówno w dokładności, jak i niezawodności, jednocześnie utrzymując dane w obrębie szpitala. Autorzy argumentują, że prace przyszłe powinny bardziej przejrzyście raportować techniki prywatności i koszty obliczeniowe, aby systemy opieki zdrowotnej mogły podejmować świadome decyzje, kiedy drobne kompromisy w wydajności są warte znacznych korzyści w zakresie prywatności i współpracy.
Cytowanie: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Słowa kluczowe: uczenie federacyjne, AI w opiece zdrowotnej, prywatność danych medycznych, zdecentralizowane uczenie maszynowe, kliniczne modele predykcyjne