Clear Sky Science · pl
Uogólnienie automatycznej segmentacji nowotworu w patologii cyfrowej na obrazy całych preparatów dla różnych typów raka
Dlaczego to ma znaczenie w opiece nad pacjentem onkologicznym
Rozpoznanie nowotworu wciąż opiera się na ekspertach, którzy dokładnie oglądają szkiełka z utrwalonym barwionym materiałem pod mikroskopem — to czasochłonne zadanie, utrudniane przez rosnącą liczbę przypadków i deficyt patologów. Badanie stawia proste, lecz istotne pytanie: czy jeden system sztucznej inteligencji może niezawodnie wykrywać obszary nowotworowe na cyfrowych obrazach mikroskopowych dla wielu różnych typów guza, zamiast tworzyć oddzielne narzędzie dla każdego raka? Jeśli tak, mogłoby to odciążyć specjalistów, przyspieszyć diagnostykę i udostępnić zaawansowaną analizę także dla rzadziej występujących nowotworów, dla których danych jest mało.
Od szkiełek do cyfrowych pomocników
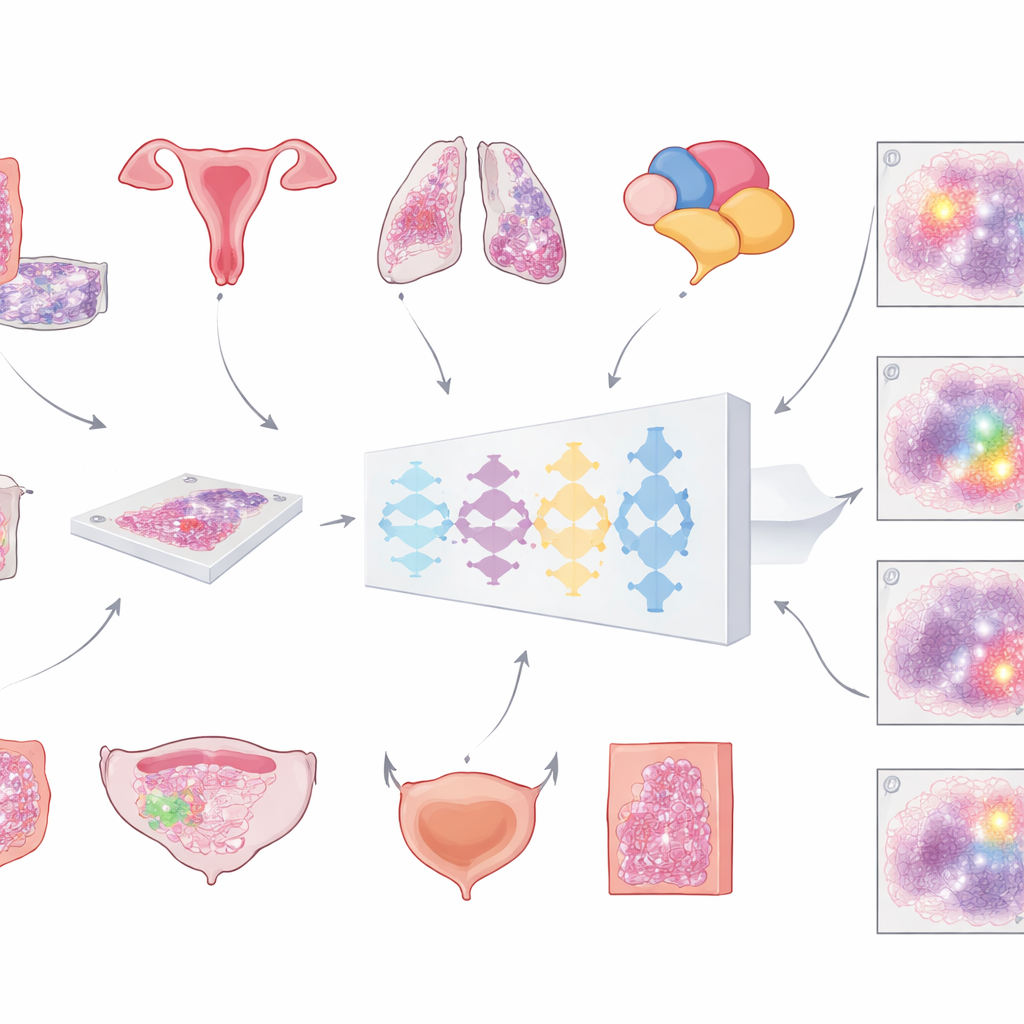
Nowoczesne szpitale coraz częściej skanują preparaty mikroskopowe, tworząc ogromne, szczegółowe „obrazy całych preparatów” guza. Pierwszym kluczowym krokiem dla każdej analizy komputerowej jest oddzielenie tkanki nowotworowej od wszystkiego innego — komórek prawidłowych, tłuszczu, pustego szkła i artefaktów. Dotąd większość zautomatyzowanych narzędzi była trenowana na jednym typie nowotworu, co ograniczało ich zastosowanie. Zespół autorów pracy postawił sobie za cel zbudowanie jednego, uniwersalnego modelu, który potrafiłby wskazać obszary guza w preparatach z kilku powszechnych typów raka barwionych rutynowymi barwnikami hematoksyliną i eozyną. Ich wizją było narzędzie ogólnego przeznaczenia, które można by podłączyć do wielu ścieżek diagnostycznych bez konieczności każdorazowej przebudowy.
Trenowanie jednego modelu, by rozpoznawał wiele raków
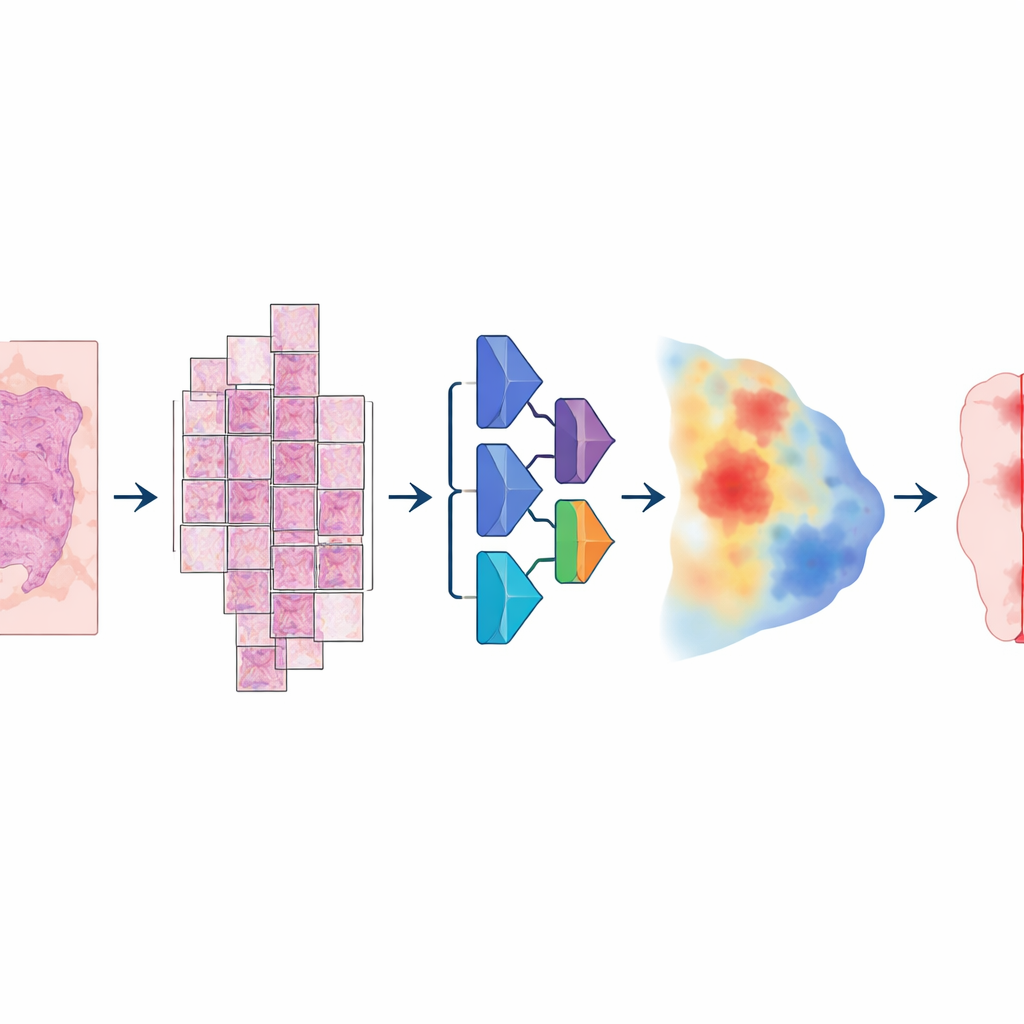
Aby zbudować model, badacze zgromadzili nietypowo dużą i zróżnicowaną kolekcję cyfrowych preparatów: ponad 20 000 obrazów całych preparatów pochodzących od ponad 4 000 pacjentów z rakiem jelita grubego, endometrium, płuca i prostaty. Wszystkie próbki pochodziły z rutynowego materiału utrwalonego formaliną i zatopionego w parafinie oraz zostały zeskanowane na dwóch różnych wysokorozdzielczych skanerach. Patolog dokładnie obrysował obszary nowotworu na każdym preparacie, dostarczając „prawdy” będącej podstawą uczenia. Model działał w kilku etapach: każdy ogromny obraz dzielono na duże, nakładające się płytki, przeprowadzano przez sieć neuronową oceniającą dla każdego piksela prawdopodobieństwo bycia guzem, a następnie składano z powrotem w gładką mapę, która ostatecznie przekształcana była w czystą maskę guz kontra nie‑guz.
Testowanie systemu
Co istotne, zespół nie zatrzymał się na wynikach treningu. Ten sam model przetestowano na ponad 3 000 dodatkowych pacjentów obejmujących sześć typów nowotworów — w tym raka piersi i pęcherza, które nie były używane podczas treningu — oraz na preparatach z różnych szpitali i skanerów. Dokładność mierzono głównie standardowym wskaźnikiem nakładania (współczynnikiem Dice’a), który osiąga 100% gdy obrys guza przez komputer idealnie pokrywa się z obrysem patologów. Dla dużych, ciągłych próbek guza w raku jelita grubego, endometrium, płuca, prostaty i piersi średnie nakładanie przekraczało 80%, często osiągając ponad 90%. W dużych zewnętrznych zbiorach z The Cancer Genome Atlas, pochodzących z wielu laboratoriów i skanerów na świecie, wyniki również utrzymywały się powyżej 80%, co sugeruje, że model dobrze uogólnia się poza instytucję macierzystą.
Gdzie ma trudności i jak się wypada w porównaniu z innymi
Główną słabością okazały się wczesne stadia raka pęcherza pobierane zabiegiem dającym bardzo małe, fragmentaryczne kawałki tkanki. W takich przypadkach model często nie oznaczał żadnego guza, zwłaszcza gdy obszar nowotworu był bardzo niewielki. Jednak gdy wykrywał guz, nakładanie z obrysami patologów było wysokie, a proste dostosowania progów końcowych poprawiały wyniki — co sugeruje, że sama sieć rozpoznawała wzorzec, ale post‑processing był zbyt rygorystyczny. Badacze zbudowali też cztery „specjalistyczne” modele, każdy trenowany na jednym typie raka, i stwierdzili, że żaden z nich istotnie nie przewyższał modelu ogólnego w jego własnej domenie. W przeciwieństwie do tego, systemy specjalistyczne przeważnie zawodziły po zastosowaniu do innych typów nowotworów, podczas gdy model ogólny pozostawał odporny. W porównaniu z popularnym, bardziej ogólnym narzędziem do segmentacji medycznej wymagającym wskazówek od użytkownika, nowy model zwykle działał równie dobrze lub lepiej, pozostając przy tym w pełni automatycznym.
Co to oznacza dla pacjentów i lekarzy
Dla osób niebędących ekspertami kluczowy wniosek jest taki, że jeden dobrze zaprojektowany system AI może wiarygodnie wskazywać tkankę nowotworową na cyfrowych preparatach w kilku głównych typach raka, bez konieczności tworzenia wersji dostosowanych do każdej choroby czy skanera. Nie zastępuje on patologa, ale może wstępnie oznaczać prawdopodobne obszary guza, wspierać spójne pomiary i uwalniać specjalistów, by skupili się na najbardziej wymagających przypadkach. Obecna wersja wciąż pomija niektóre bardzo małe lub wczesne guzy — szczególnie fragmentaryczne próbki pęcherza i prawdopodobnie inne tkanki przypominające biopsję — więc nie nadaje się jeszcze do wykrywania najdrobniejszych śladów choroby. Niemniej jednak badanie pokazuje, że szeroka, „pan‑rakowa” segmentacja guzów jest wykonalna w warunkach rzeczywistych i może stanowić solidny pierwszy krok dla przyszłych zautomatyzowanych narzędzi oceniających stopień zaawansowania, przewidujących odpowiedź na leczenie lub wspierających terapie precyzyjne.
Cytowanie: Skrede, OJ., Pradhan, M., Isaksen, M.X. et al. Generalisation of automatic tumour segmentation in histopathological whole-slide images across multiple cancer types. npj Precis. Onc. 10, 107 (2026). https://doi.org/10.1038/s41698-026-01311-6
Słowa kluczowe: patologia cyfrowa, uczenie głębokie, segmentacja nowotworu, obrazowanie całych preparatów, model pan‑rakowy