Clear Sky Science · pl
Interpretowalny model uczenia głębokiego do przewidywania molekularnych podtypów raka endometrium na podstawie preparatów barwionych H&E
Dlaczego to ma znaczenie dla zdrowia kobiet
Rak endometrium, który rozpoczyna się w błonie śluzowej macicy, jest jednym z najczęstszych nowotworów u kobiet, a wskaźnik zgonów rośnie na całym świecie. Lekarze wiedzą już, że ten nowotwór występuje w kilku molekularnych „wariantach”, które różnie reagują na zabieg chirurgiczny, radioterapię, chemioterapię i nowsze terapie immunologiczne. Obecnie identyfikacja tych molekularnych podtypów zwykle wymaga kosztownych i czasochłonnych badań genetycznych, których wiele szpitali nie może łatwo zaoferować. W badaniu sprawdzono, czy starannie zaprojektowany system sztucznej inteligencji (SI) może odczytywać rutynowe preparaty patologiczne — różowo‑fioletowe obrazy tkanki wykonywane u każdego pacjenta — i dokładnie wnioskować o tych molekularnych podtypach, co potencjalnie mogłoby uczynić opiekę precyzyjną bardziej dostępną.
Bliższe spojrzenie na zróżnicowanie nowotworu
Nie wszystkie raki endometrium zachowują się tak samo. Niektóre rosną wolno i pozostają ograniczone do macicy; inne szerzą się wcześnie i są trudniejsze do leczenia. Współczesne wytyczne dzielą te guzy na cztery molekularne podtypy w oparciu o zmiany w DNA i mechanizmy naprawy uszkodzeń genetycznych. Kategorie te pomagają przewidywać rokowanie i kierować decyzjami, takimi jak zakres operacji czy to, czy pacjentka może odnieść korzyść z immunoterapii. Jednak wymagane testy genetyczne i specjalne barwienia są kosztowne, zależą od ekspertów i często nie są dostępne w mniejszych lub ograniczonych zasobowo szpitalach. Patolodzy od dawna podejrzewali, że wiele z tych molekularnych różnic pozostawia wizualne wskazówki w wyglądzie komórek i tkanki pod mikroskopem — ale te sygnały mogą być zbyt subtelne i złożone, by oko ludzkie oceniało je spójnie.
Nauka komputerów czytania preparatów patologicznych
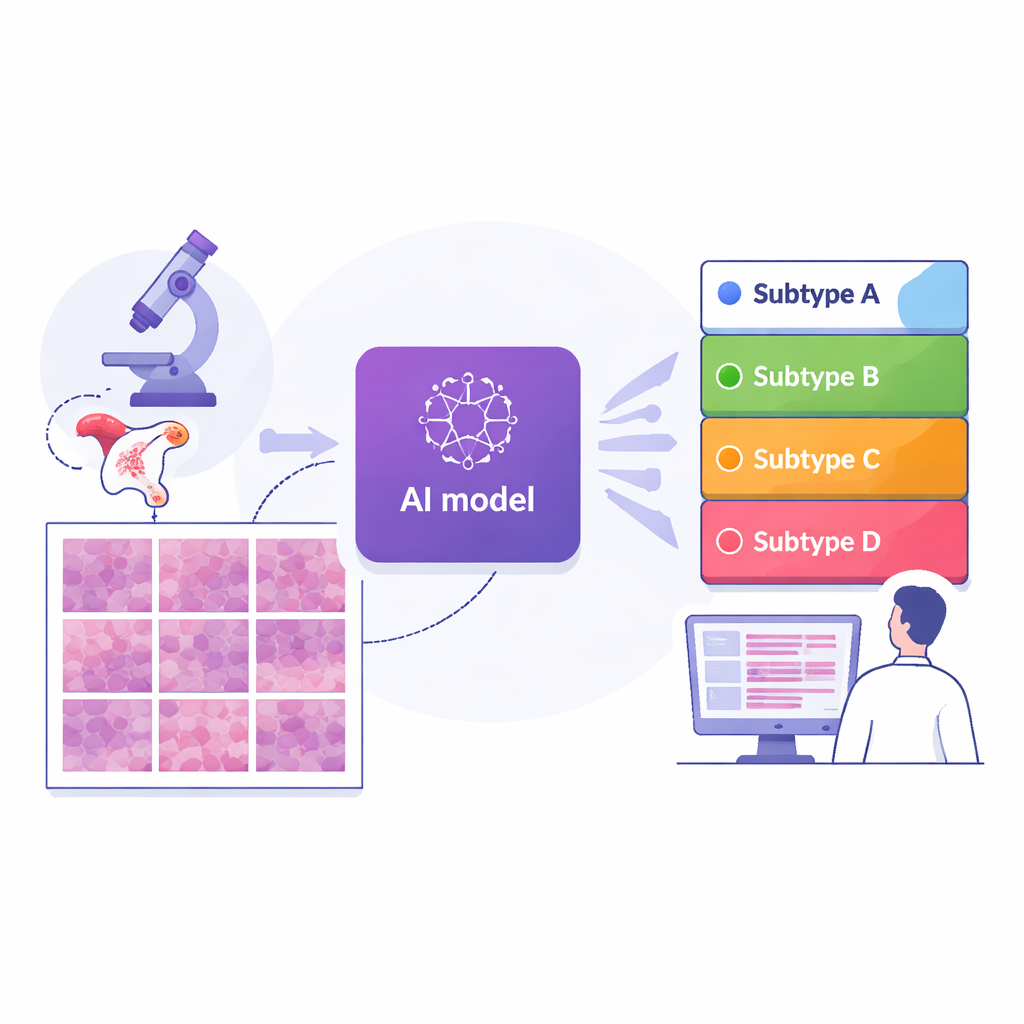
Naukowcy zgromadzili obrazy cyfrowe 364 preparatów od 324 kobiet leczonych w dużym ośrodku onkologicznym w Szanghaju oraz dwie niezależne grupy porównawcze: 296 preparatów z międzynarodowego publicznego zestawu danych i 36 z innego szpitala w Suzhou. Każdy przypadek został wcześniej przypisany do jednego z czterech molekularnych podtypów za pomocą zaawansowanych badań genetycznych. Zespół pociął każde całopreparatowe zdjęcie na tysiące małych płytek i wyszkolił model uczenia głębokiego — rodzaj SI używany w rozpoznawaniu obrazów — aby oceniać każdą płytkę i szacować, jak prawdopodobne jest jej przynależenie do poszczególnych podtypów. Poprzez uśrednianie prognoz płytek dla całego preparatu system generował pojedynczą prognozę podtypu dla każdej pacjentki, co przypomina sposób, w jaki lekarze oceniają guz jako całość.
Jak dobrze działał system
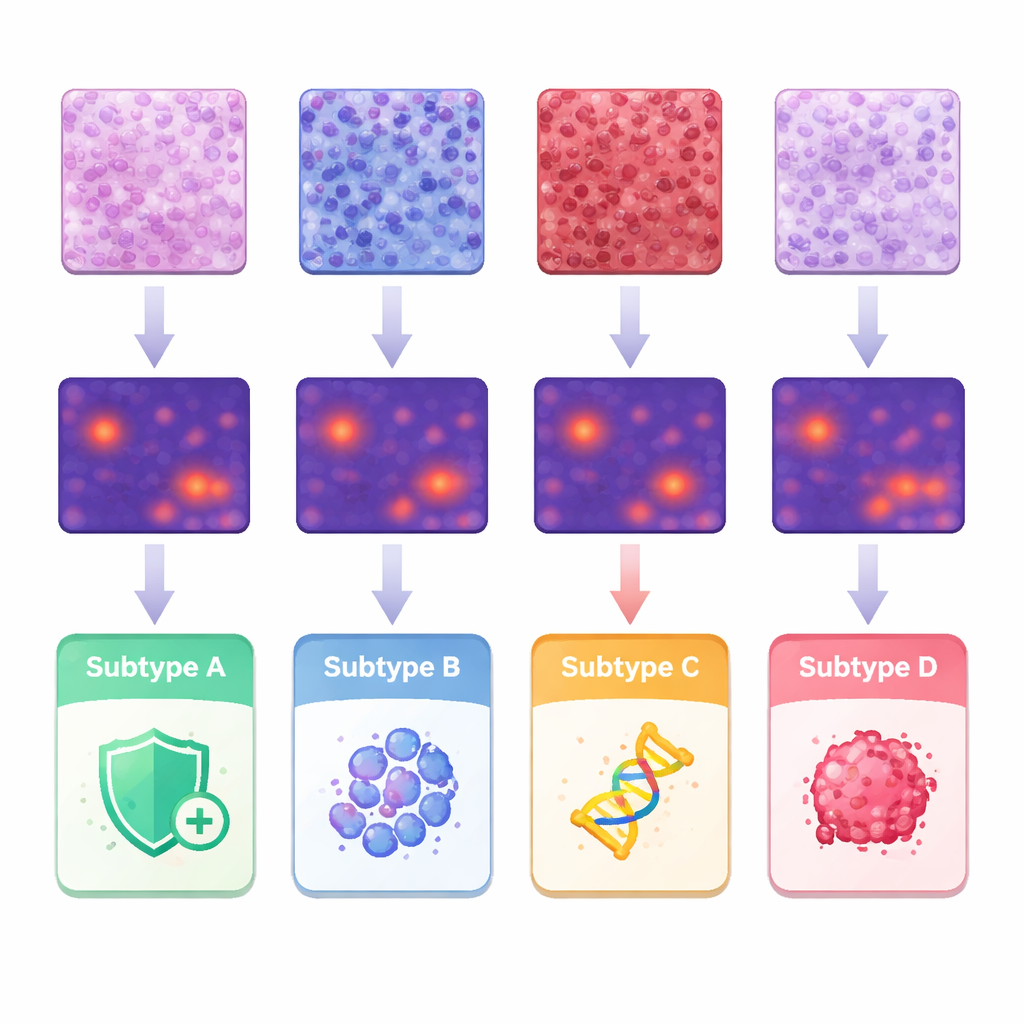
W głównej grupie ze Szanghaju SI osiągnęło wysoki poziom dokładności: jego wynik ogólny w rozróżnianiu między czterema podtypami (mierzony standardową statystyką, która wynosi 0,5 przy zgadywaniu i 1,0 przy idealnym rozdzieleniu) wyniósł około 0,87. Wyniki pozostały silne — około 0,84 — podczas testów na dwóch zewnętrznych grupach pochodzących z różnych szpitali i systemów skanowania preparatów, co sugeruje, że podejście jest relatywnie odporne. W porównaniu z kilkoma wiodącymi strategiami SI wykorzystującymi bardziej złożone mechanizmy uwagi lub łączenia, ten model end‑to‑end, oparty na nowoczesnym rdzeniu analizy obrazu, zazwyczaj radził sobie lepiej. Co ważne, autorzy zaprojektowali system jako interpretowalny: użyli narzędzi wizualizacyjnych, aby podkreślić, które regiony każdej płytki SI brało pod uwagę przy podejmowaniu decyzji.
Co SI „zobaczyło” w mikrośrodowisku guza
Aby zrozumieć, jakie cechy napędzały prognozy, zespół powiązał mapy cieplne SI z klasycznymi obserwacjami patologicznymi oraz ze szczegółowymi pomiarami kształtu i ułożenia poszczególnych komórek. Guzy jednego podtypu wykazywały gęste nacieki komórek odpornościowych w tkance podtrzymującej, inny podtyp miał tendencję do ciasno upakowanych komórek strukturalnych. Trzecia grupa prezentowała bardziej zwarte, lite płyty wysoce nieprawidłowych komórek nowotworowych, a podtyp związany z agresywnym przebiegiem wykazywał struktury brodawkowate, palczaste i bardzo nieregularne jądra. Poprzez segmentację i analizę około 245 milionów komórek badacze skwantyfikowali różnice w wielkości komórek, zmienności i odstępach między nimi oraz pokazali, jak pewne kombinacje korelują z konkretnymi podtypami. Wyniki te wspierają ideę, że molekularne różnice pozostawiają rozpoznawalny odcisk w architekturze tkanki, który maszyny mogą systematycznie wykrywać.
Od dowodu koncepcji do wsparcia klinicznego
To badanie nie ma na celu zastąpienia badań genetycznych; proponuje raczej narzędzie triage „H&E‑first”, które wykorzystuje standardowe barwienie przygotowywane dla każdej biopsji. W praktyce mapa prawdopodobieństwa podtypu wygenerowana przez SI mogłaby pomóc patologom zdecydować, które testy potwierdzające zlecić w pierwszej kolejności, priorytetyzować ograniczoną tkankę dla najbardziej informatywnych analiz i przyspieszyć decyzje terapeutyczne, szczególnie w szpitalach, gdzie pełne profilowanie molekularne jest trudne do uzyskania. Badanie uwypukla również obecne ograniczenia, takie jak słabsze wyniki dla najrzadszego podtypu i potrzebę większych, bardziej zróżnicowanych zbiorów danych przed wdrożeniem. Mimo to dostarcza przekonującego dowodu, że rutynowe obrazy mikroskopowe zawierają wystarczająco dużo ukrytej informacji, by SI mogła przybliżyć złożone etykiety molekularne, otwierając drogę do bardziej równej, opartej na danych opieki dla kobiet z rakiem endometrium.
Cytowanie: Guo, Q., Cui, H., Zhang, Y. et al. An interpretable deep learning model for predicting endometrial cancer molecular subtypes from H&E-stained slides. npj Precis. Onc. 10, 71 (2026). https://doi.org/10.1038/s41698-026-01280-w
Słowa kluczowe: rak endometrium, patologia cyfrowa, uczenie głębokie, molekularne podtypy, precyzyjna onkologia