Clear Sky Science · pl
IMFLKD: mechanizm zachęt dla zdecentralizowanego uczenia federacyjnego oparty na destylacji wiedzy
Dlaczego dzielenie się może być bezpieczne i sprawiedliwe
Współczesna sztuczna inteligencja żywi się danymi, a większość z nich znajduje się na prywatnych telefonach, serwerach szpitali lub w chmurach firm, które nie mogą być po prostu skopiowane i udostępnione. Uczenie federacyjne oferuje sposób, w którym wiele urządzeń może trenować wspólny model bez ujawniania surowych danych, ale dzisiejsze systemy nadal borykają się z wyciekami prywatności, centralnymi punktami awarii i niesprawiedliwymi nagrodami dla najbardziej zaangażowanych uczestników. Niniejszy artykuł przedstawia nowe ramy — IMFLKD — łączące trzy silne idee: blockchain, destylację wiedzy i scoring reputacji, aby uczynić tego typu zbiorowe uczenie bardziej prywatnym, bardziej odpornym i długoterminowo sprawiedliwym.
Wspólne trenowanie bez ujawniania tajemnic
W klasycznym uczeniu federacyjnym centralny serwer zbiera aktualizacje modeli od wielu uczestników i je łączy. To oszczędza przesyłania surowych danych, ale sam serwer staje się atrakcyjnym celem: jeśli zawiedzie, cały system ugrzęźnie, a jeśli nie jest godny zaufania, może niewłaściwie wykorzystać lub ujawnić informacje ukryte w aktualizacjach modelu. Autorzy zamiast tego wykorzystują zdecentralizowany łańcuch bloków do koordynacji treningu. Każdy uczestnik trenuje lokalny model na własnych danych, a następnie wchodzi w interakcje ze smart kontraktami na blockchainie, które rejestrują wkłady, agregują informacje i rozdzielają nagrody — wszystko to bez polegania na jednej centralnej instytucji.
Dzielenie wiedzy, nie ciężkich modeli
Aby zmniejszyć koszty komunikacji i dodatkowo chronić prywatność, ramy opierają się na destylacji wiedzy. Zamiast przesyłać pełne parametry modelu, każdy uczestnik wysyła tylko „miękkie etykiety” — przewidywane przez model prawdopodobieństwa dla zestawu współdzielonych wejść — które są znacznie lżejsze i ujawniają mniej o danych pojedynczej osoby. Ponieważ rzeczywisty wspólny zbiór danych może nie istnieć, system wykorzystuje model generatywny zwany warunkowym autoenkoderem wariacyjnym do stworzenia syntetycznego „pseudo-publicznego” zbioru, który w przybliżeniu odwzorowuje ogólną dystrybucję etykiet bez ujawniania oryginalnych rekordów. Uczestnicy trenują na własnych danych, generują przewidywania dla tego syntetycznego zbioru, a następnie udoskonalają swoje modele, korzystając ze zebranej sygnatury pochodzącej z połączonej wiedzy wszystkich.
Pomiary, kto naprawdę pomaga
Kluczowym wyzwaniem w każdym systemie współpracy jest ustalenie, kto zasługuje na uznanie. IMFLKD rozwiązuje to dwustopniową metodą oceny wkładu opartą na agregacji etykiet. Najpierw lekki algorytm bayesowski analizuje przewidywania wszystkich uczestników i wnioskuje zarówno najbardziej prawdopodobną prawdziwą etykietę dla każdego przykładu, jak i ocenę jakości każdego modelu, aktualizując te oceny w miarę pojawiania się kolejnych zadań. Podejście to działa online, bez przechowywania przeszłych danych, i radzi sobie z głośnymi lub złośliwymi uczestnikami poprzez obniżanie wagi modeli, które często nie zgadzają się z wyłaniającym się konsensusem. Eksperymenty pokazują, że taka agregacja etykiet poprawia dokładność o około 10 procent w porównaniu z prostym głosowaniem większościowym, pozostając jednocześnie wystarczająco szybka dla środowisk o dużej skali i ograniczonych zasobach.
Przekształcanie jakości w nagrody i reputację
Gdy jakość wkładu jest znana, IMFLKD stosuje schemat zachęt zwany ważonym peer truth serum, aby przekształcić ją w nagrody. Uczestnicy są porównywani z konsensusem rówieśniczym ważonym jakością: ci, których przewidywania zgadzają się z wysokiej jakości rówieśnikami, zyskują więcej, podczas gdy ci, którzy odbiegają lub często się nie zgadzają, są karani. To sprawia, że uczciwe raportowanie jest najbardziej opłacalną strategią długoterminową, nawet wobec możliwości zmowy. Ponadto system buduje wielowymiarowy wskaźnik reputacji dla każdego uczestnika, łącząc jakość danych, poziom aktywności i stabilność zachowania, a starsze zachowania są regulowane czynnikiem czasowego zaniku. Reputacja z kolei wpływa na późniejsze rundy, decydując o wadze, jaką mają przewidywania uczestnika, oraz o tym, czy zostanie on wybrany do przyszłych zadań.
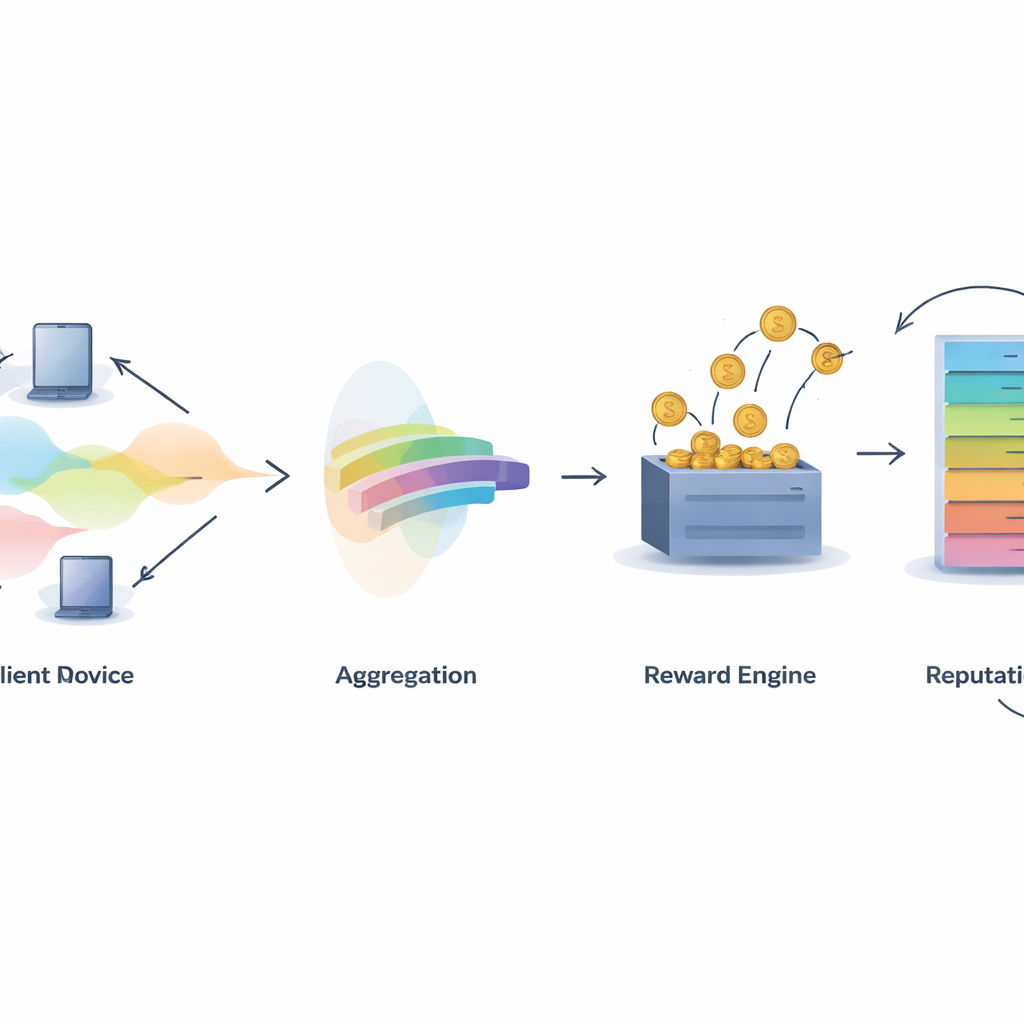
Budowanie zaufania do inteligencji zbiorowej
Ogólnie rzecz biorąc, ramy IMFLKD pokazują, że możliwe jest koordynowanie uczenia wśród wielu niezależnych urządzeń w sposób efektywny, świadomy prywatności i odporny na darmozjadów oraz atakujących. Poprzez połączenie generowania danych syntetycznych, rygorystycznego scoringu wkładów, nagród opartych na teorii gier i dynamicznego śledzenia reputacji na blockchainie, system zachęca uczestników do uczciwego i konsekwentnego zachowania przez wiele rund treningowych. Dla czytelnika niebędącego specjalistą kluczowa myśl jest taka: możemy wykorzystać zbiorową moc rozproszonych danych — takich jak rekordy medyczne, odczyty sensorów czy dane z urządzeń osobistych — bez przekazywania wszystkiego jednej firmie czy serwerowi, a jednocześnie zapewnić, że ci, którzy dostarczają najbardziej użyteczne informacje, czerpią z tego największe korzyści.
Cytowanie: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Słowa kluczowe: uczenie federacyjne, blockchain, destylacja wiedzy, mechanizmy zachęt, systemy reputacyjne