Clear Sky Science · pl
Federacyjne uwzględnianie pewności w grafowych mechanizmach uwagi dla agentów Internetu Rzeczy medycznych przy spełnianiu ograniczeń czasowych SLO
Inteligentniejsze sieci dla urządzeń ratujących życie
Połączone urządzenia medyczne — od monitorów szpitalnych po noszone urządzenia domowe — stają się cichymi strażnikami naszego zdrowia. Wykrywają nieregularne rytmy serca, nietypowy ruch w sieci szpitalnej lub awarie czujników zanim zwróci to uwagę personel. Gdy jednak urządzenia generują alarm, sieć musi zareagować poprawnie i w ułamku sekundy. Artykuł przedstawia nowy sposób koordynacji wielu takich urządzeń, dzięki któremu ich ostrzeżenia są nie tylko dokładne, lecz także uczciwe względem własnej niepewności i na tyle szybkie, by dotrzymać surowych zobowiązań dotyczących czasu reakcji.
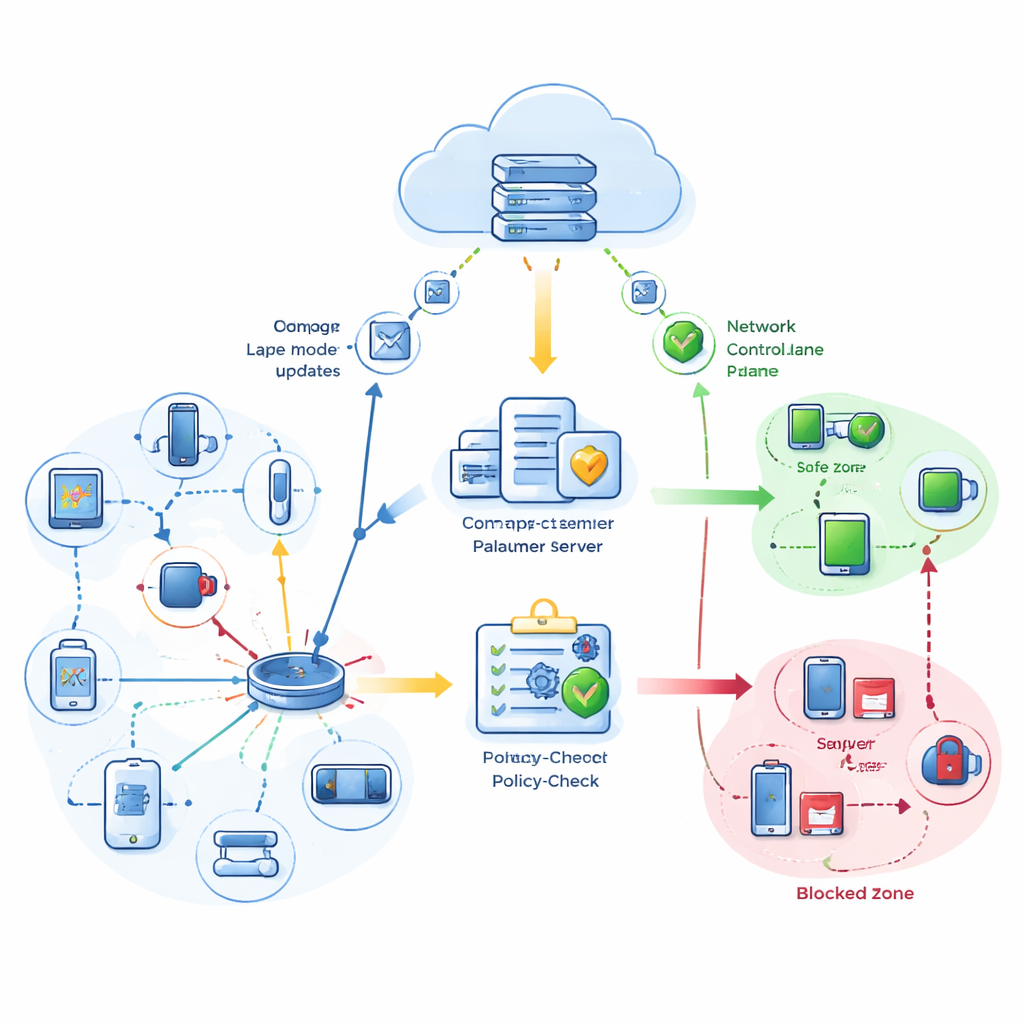
Dlaczego urządzenia medyczne potrzebują i „mózgu”, i „nerwów”
Autorzy koncentrują się na Internecie Rzeczy Medycznych, gdzie niezliczone urządzenia obserwują pacjentów i sprzęt szpitalny w czasie rzeczywistym. W takim środowisku błąd oprogramowania lub opóźniona reakcja mogą oznaczać brak wykrycia alarmu albo niepotrzebne wyłączenia. Tradycyjne podejścia do trenowania modeli na wielu urządzeniach — znane jako uczenie federacyjne — pomagają chronić prywatność, pozostawiając surowe dane lokalnie. Mają jednak często problemy z zawodnymi łączami sieciowymi, nierówną jakością danych i brakiem wglądu w to, na ile modele „ufają” swoim decyzjom. Istniejące modele grafowe, dobrze oddające relacje między urządzeniami, oraz nowoczesne podejścia oparte na intencjach sieciowych, które przekładają cele wysokiego poziomu na działania sieci, były dotychczas badane głównie osobno.
Zamknięta pętla od sensorów do automatycznej akcji
Proponowany system, nazwany HP-FedGAT-Trust-IBN, łączy te elementy w jedną ciągłą pętlę sterowania. Na krawędzi sieci, blisko sensorów i aktuatorów, model oparty na grafie analizuje powiązania między urządzeniami i ich współzachowanie. Przypisuje każdemu połączeniu wagi uwagi oraz oceny zaufania, zadając w praktyce pytanie: „Których sąsiadów powinienem słuchać i jak bardzo jestem pewien?” Zamiast przesyłać pełne modele przez sieć, każde urządzenie wysyła skompaktowane aktualizacje oraz kilka statystyk zaufania do chmury, co znacząco zmniejsza wykorzystanie pasma. W chmurze bezpieczny krok agregacji łączy te aktualizacje, dając większą wagę urządzeniom ocenionym jako bardziej wiarygodne lub mniej niepewne.
Przekształcanie pewności w bezpieczniejsze decyzje
Co wyróżnia tę ramę działania, to traktowanie pewności — nie tylko dokładności — jako sygnału pierwszorzędnego. Model jest trenowany tak, aby gdy deklaruje wysoką pewność co do predykcji, ta pewność była zazwyczaj uzasadniona. Skalibrowane oceny pewności napędzają następnie kontroler oparty na intencjach sieciowych. Zanim zostanie zastosowane jakiekolwiek reguła sieciowa — na przykład odizolowanie podejrzanego urządzenia, ograniczenie jego ruchu czy przeniesienie go do chronionego segmentu — warstwa intencji sprawdza zarówno sugerowane działanie modelu, jak i stopień jego pewności. Decyzje, które przejdą te weryfikacje, są wykonywane automatycznie, podczas gdy przypadki graniczne mogą być spowolnione, umieszczone w kolejce lub skierowane do weryfikacji przez człowieka. To powiązanie pewności z harmonogramowaniem pomaga utrzymać najwolniejsze, choć rzadkie, odpowiedzi w ramach obiecanych limitów, na przykład 50 lub 100 milisekund.
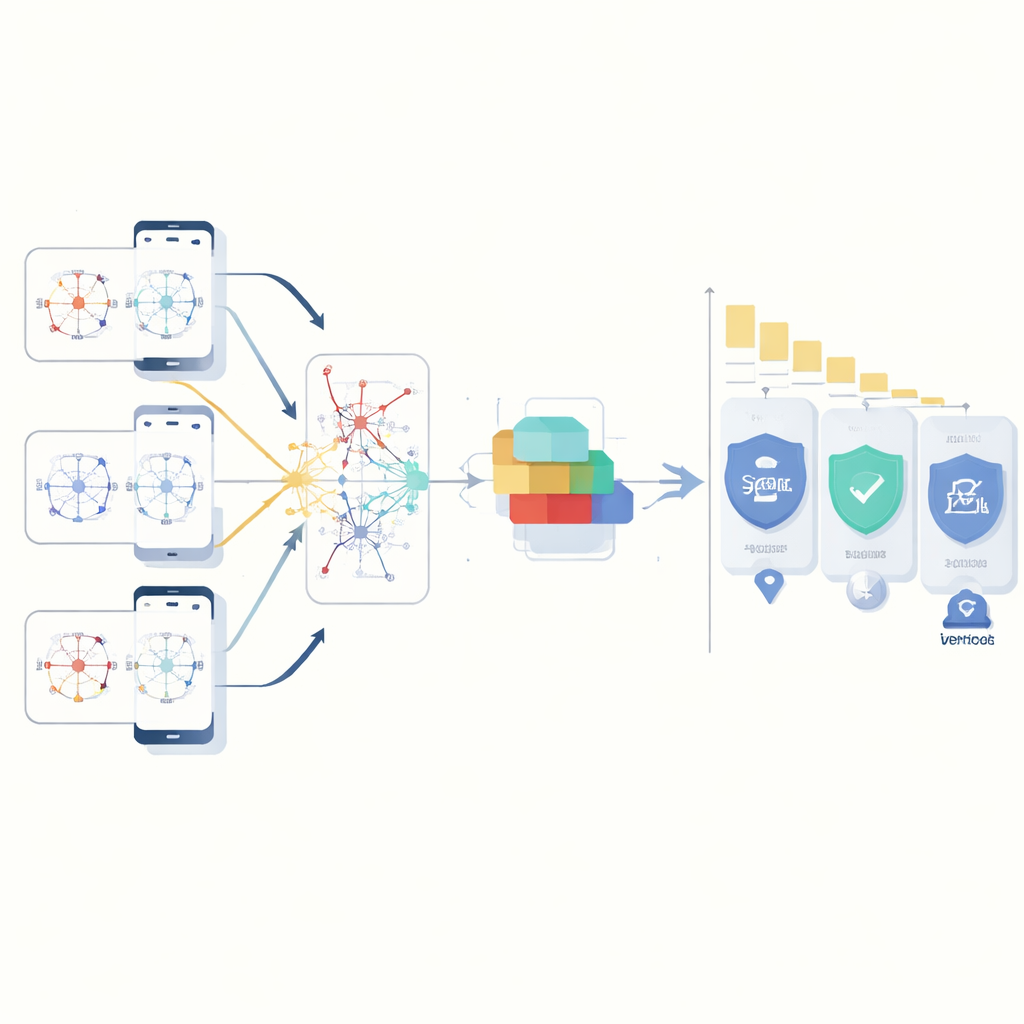
Dowód działania na rzeczywistym sprzęcie
Aby pokazać, że pomysły sprawdzają się poza symulacjami, autorzy przeprowadzili dwuczęściową ewaluację. Najpierw zasymulowali 100 wirtualnych klientów pochodzących z kilku medycznych i noszonych zestawów danych, porównując swoją metodę z nowoczesnymi konkurencyjnymi systemami. Podejście osiąga bardzo wysoką zdolność rozróżniania zachowań normalnych od nieprawidłowych przy jednoczesnym zachowaniu dobrze dostosowanej pewności. Następnie wyeksportowali wytrenowane modele na realne urządzenia brzegowe, w tym Raspberry Pi i niewielki komputer przemysłowy, i zmierzyli pełne czasy „od sensora do akcji”. Nawet po uwzględnieniu dodatkowych obliczeń związanych z estymacją niepewności i opcjami szyfrowania, system utrzymuje najwolniejszy jeden procent odpowiedzi znacznie poniżej 100 milisekund, robiąc to przy ograniczonym wykorzystaniu komunikacji, energii i emisji CO2 na rundę trenowania.
Co to oznacza dla pacjentów na co dzień
Mówiąc prosto, praca ta pokazuje, jak przyszłe sieci medyczne mogą być jednocześnie ostrożne i szybkie. Urządzenia uczą się razem bez udostępniania surowych danych medycznych, wyjaśniają, na ile ufają własnym alertom, a sieć działa automatycznie tylko wtedy, gdy to zaufanie jest uzasadnione i można je wdrożyć w wymaganym czasie. Poprzez mierzenie nie tylko dokładności, lecz także uczciwości wobec niepewności, zużycia energii, ochrony prywatności i opóźnień w najgorszym scenariuszu, ta koncepcja oferuje szpitalom i dostawcom opieki zdrowotnej praktyczny plan działania: wybierz ustawienia, które zapewnią bezpieczeństwo pacjentów, ochronę danych i jednocześnie spełnienie rygorystycznych zobowiązań czasowych.
Cytowanie: Yang, D., Liu, B., Wan, L. et al. Confidence-calibrated federated graph attention for internet of things agents under latency SLOs. Sci Rep 16, 10792 (2026). https://doi.org/10.1038/s41598-026-45662-3
Słowa kluczowe: internet rzeczy medycznych, uczenie federacyjne, grafowe sieci neuronowe, opóźnienia sieciowe, zaufanie i niepewność