Clear Sky Science · pl
Hybrydowe uczenie ewolucyjno‑gradientowe poprawia długoterminowe prognozowanie szeregów czasowych
Dlaczego lepsze prognozy długoterminowe mają znaczenie
Od zapotrzebowania na energię i natężenia ruchu na autostradach po kursy walut i pogodę lokalną — nasze życie kształtują systemy zmieniające się w czasie. Dokładne przewidywanie tych wzorców na kilka dni czy tygodni naprzód może oszczędzać energię, zmniejszać korki i zwiększać odporność przedsiębiorstw. Im dalej w przyszłość patrzymy, tym trudniej współczesnym narzędziom sztucznej inteligencji radzić sobie ze zmieniającymi się warunkami, zakłóceniami pomiarów i ograniczonym budżetem obliczeniowym. W artykule przedstawiono nowy sposób trenowania modeli prognostycznych, dzięki któremu pozostają one dokładne i stabilne nawet wtedy, gdy świat nie stoi w miejscu.
Uczenie się z wielu modeli zamiast z jednego
Większość nowoczesnych prognostyków szeregów czasowych opiera się na pojedynczej głębokiej sieci neuronowej trenowanej metodą spadku gradientu — standardowym podejściu, które krok po kroku koryguje parametry, aby zmniejszyć błąd. To działa dobrze, gdy dane zachowują się spójnie, ale zawodzi przy dryfie warunków, zaszumionych pomiarach czy ograniczonym czasie treningu. Zamiast projektować nową architekturę, autorzy proponują Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR) — ramy treningowe, które można nałożyć na istniejące struktury. Kluczowa idea to utrzymywanie małej „populacji” modeli o tej samej budowie, ale różnym losowym inicjowaniu. W trakcie treningu modele eksplorują różne sposoby dopasowania do danych, a najlepiej radzący sobie w danym momencie model służy jako przewodnik przy ulepszaniu pozostałych.
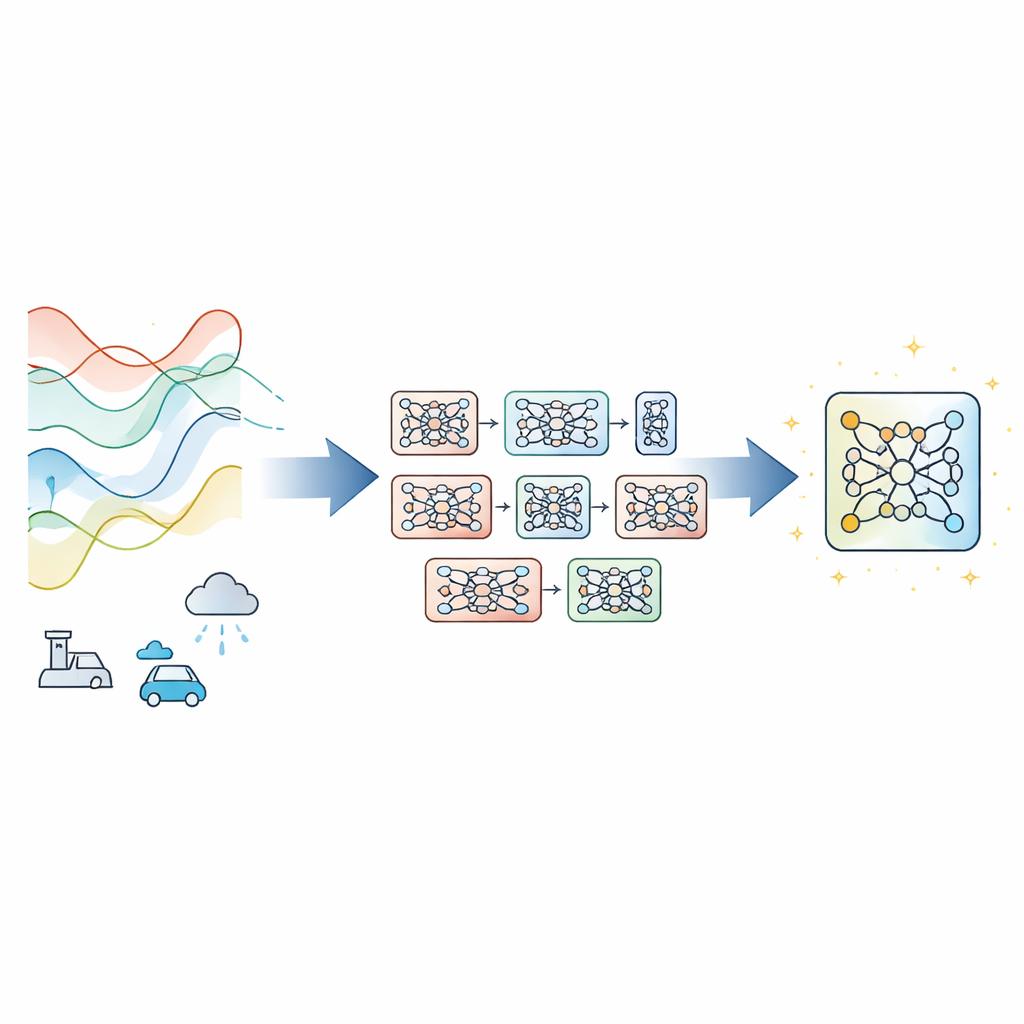
Pożyczanie dobrych części przy zachowaniu użytecznej różnorodności
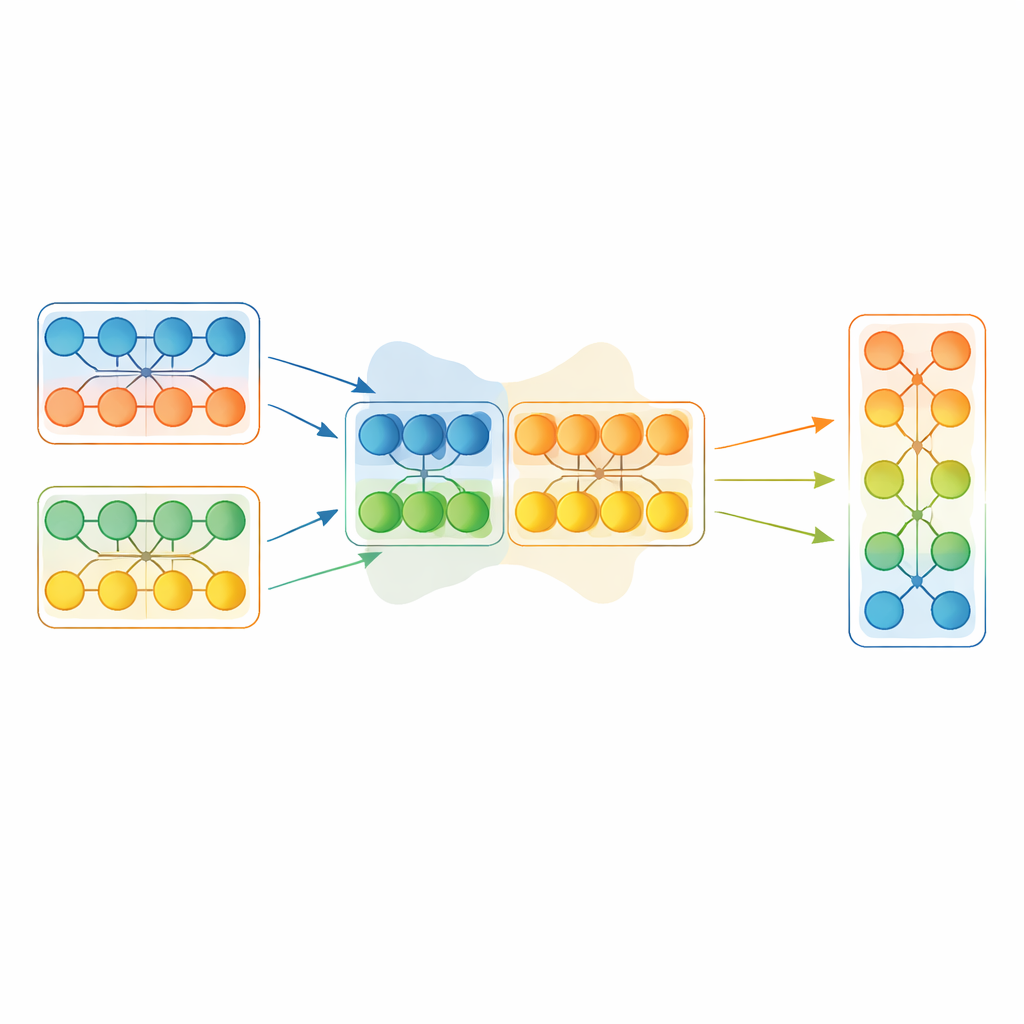
Zamiast bezkrytycznego kopiowania całego zwycięskiego modelu, EGMF‑GR działa na poziomie modułów — powtarzalnych bloków wewnątrz sieci, takich jak stosy warstw. Dla każdego modelu w populacji ramy wyrównują odpowiadające sobie moduły z modułami aktualnie najlepszego modelu i porównują ich wewnętrzne sygnały podczas przetwarzania tej samej partii danych. Stosowane są proste miary różnicy, uwzględniające zarówno kształt wzorców aktywności, jak i ich amplitudę. Te modułowe rozbieżności są następnie podsumowywane, a do aktualizacji trafiają tylko moduły, których zachowanie jest wyraźnie odosobnione względem rówieśników. Gdy tak się dzieje, opóźniony moduł jest przesuwany w stronę odpowiadającego mu modułu w najlepszym modelu poprzez ważoną kombinację ich parametrów oraz niewielkie losowe zakłócenie, aby zachować różnorodność.
Pozwól gradientom uporządkować sprawy po większych ruchach
Mieszanie części z różnych sieci może wprowadzać nagłe zmiany. Aby nie destabilizować treningu, każdy zespawany model przechodzi krótki, konwencjonalny etap spadku gradientu na danych treningowych. Ten etap dopracowania pozwala sieci płynnie zaadaptować się do nowej konfiguracji wewnętrznej, zachowując korzyści z przejętej wiedzy. Procedura powtarza się: wybiera się aktualnie najlepszy model na podstawie wydzielonego fragmentu danych, selektywnie łączy moduły tego lidera z pozostałymi modelami w populacji i krótko dostraja wszystkich gradientami. Co istotne, metoda synchronizuje także wewnętrzne stany administracyjne, takie jak średnie kroczące używane przez niektóre warstwy, które w prostszych schematach łączenia modeli bywają pomijane, a które mogą w dużym stopniu wpływać na stabilność.
Udowodnienie korzyści na wielu rzeczywistych sygnałach
Aby przetestować ramy, autorzy zastosowali EGMF‑GR do kilku popularnych bazowych architektur prognozujących, w tym modeli w stylu Transformera oraz niedawnego projektu opartego na konwolucjach, bez zmiany ich rdzeni. Ocenili wydajność na ośmiu publicznych benchmarkach obejmujących zużycie energii, przepływ ruchu, kursy walut i pogodę oraz na wielu horyzontach prognostycznych od kilku godzin do kilku dni. Przy ściśle dopasowanym budżecie kosztownych aktualizacji wstecznych hybrydowy trening konsekwentnie zmniejszał błędy predykcji i wygładzał przebieg treningu dla większości kombinacji modeli i zbiorów danych, szczególnie w ustawieniach wysokowymiarowych lub zaszumionych. Zespół porównał też swoje podejście z popularnymi sztuczkami dla pojedynczego modelu, takimi jak wykładnicze średnie kroczące czy uśrednianie wag stochastyczne, i wykazał, że populacyjne łączenie modułów daje dodatkowe korzyści ponad prostym wygładzaniem wag.
Utrzymanie niezawodności, gdy warunki się pogarszają
Rzeczywiste systemy rzadko zachowują się jak czyste przykłady z podręcznika, dlatego autorzy przetestowali też odporność w trudniejszych scenariuszach: sztucznie uszkodzone wejścia, brakujące fragmenty danych i okresy, w których dynamika systemu zmienia się nagle. EGMF‑GR wyraźnie pomagał, gdy wejścia były zaszumione lub częściowo brakowały, co sugeruje, że pożyczanie stabilnego zachowania modułów od aktualnie najlepszego modelu może przeciwdziałać lokalnym zakłóceniom. W okresach gwałtownych zmian reżimu przewaga była mniejsza, co wskazuje, że nadmierna alineacja może czasem spowolnić adaptację do nowych wzorców. To sygnał do przyszłych ulepszeń, w których siła fuzji będzie przygaszana, gdy środowisko stanie się wysoce niestabilne.
Co to oznacza dla codziennych narzędzi prognostycznych
Mówiąc prościej, badanie pokazuje, że trenowanie wielu współpracujących wersji tego samego modelu prognostycznego i pozwalanie im dzielić się tylko tymi częściami, które rzeczywiście wyróżniają się jako lepsze, może uczynić prognozy długoterminowe dokładniejszymi i bardziej stabilnymi bez przeprojektowywania samych modeli. EGMF‑GR działa jak zdyscyplinowana gra zespołowa: członkowie od czasu do czasu przyjmują najmocniejsze rozwiązania innych, a następnie trochę ćwiczą na własną rękę, aby dopasować się do bieżącej gry. Dla praktyków to wtyczkowa strategia treningowa, która może wzmocnić istniejące systemy prognostyczne w finansach, energetyce, transporcie i zastosowaniach klimatycznych, zwłaszcza gdy dane są chaotyczne, a budżety obliczeniowe ograniczone.
Cytowanie: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Słowa kluczowe: prognozowanie szeregów czasowych, uczenie ewolucyjne, sieci neuronowe, łączenie modeli, przesunięcie rozkładu