Clear Sky Science · pl
Wielopłaszczyznowy vision transformer do klasyfikacji krwotoków przy użyciu danych MRI w płaszczyźnie osiowej i strzałkowej
Dlaczego to badanie ma znaczenie dla pacjentów i lekarzy
Gdy ktoś może mieć udar lub krwotok mózgowy, każda minuta jest cenna. Badania obrazowe mózgu mogą ujawnić niebezpieczne krwotoki, ale szybkie i dokładne ich odczytanie jest trudne, szczególnie w przypadku rezonansu magnetycznego (MRI), który generuje wiele rodzajów obrazów z różnych kątów. W tym badaniu przedstawiono nową metodę sztucznej inteligencji (AI) zaprojektowaną do czytania wielokątowych skanów MRI bardziej podobnie do doświadczonego radiologa, z celem wykrywania krwotoków mózgu bardziej niezawodnie w warunkach szpitalnych.
Trudność wykrywania krwotoków mózgowych w MRI
Krwotok wewnątrzczaszkowy — krwawienie wewnątrz czaszki — to stan zagrażający życiu, który wymaga szybkiej diagnozy. Przez dekady tomografia komputerowa (CT) była podstawowym narzędziem obrazowania przy podejrzeniu krwotoku, ponieważ jest szybka i stosunkowo łatwa do interpretacji. MRI może dorównać lub nawet przewyższyć CT w wykrywaniu krwotoków i lepiej pokazywać wiek krwawienia oraz inne problemy, takie jak obszary mózgu pozbawione dopływu krwi. Jednak MRI trwa dłużej, bywa mniej dostępne w niektórych ośrodkach, a jego obrazy są trudniejsze w interpretacji. Ta złożoność sprawia, że MRI jest atrakcyjnym celem dla narzędzi AI, które mogą wspierać radiologów, przesiewając dużą liczbę badań, wskazując podejrzane przypadki i zmniejszając ryzyko przeoczenia subtelnego, lecz krytycznego krwotoku.
Dlaczego wiele widoków i rodzajów skanów jest trudne dla komputerów
W rutynnej opiece klinicznej MRI mózgu często wykonywane jest z relatywnie grubymi warstwami, aby skrócić badanie, co powoduje, że obrazy są dużo ostrzejsze w niektórych kierunkach niż w innych. Radiolodzy oglądają mózg w kilku płaszczyznach — osiowej (z góry), strzałkowej (z boku) i czasem czołowej (z przodu) — ponieważ niektóre krwotoki są łatwiejsze do zobaczenia pod określonym kątem. Skanom towarzyszą też różne „kontrasty” lub warianty, takie jak FLAIR, dyfuzja czy sekwencje wrażliwe na podatność, z których każdy uwydatnia inne właściwości tkanek. Jednak większość obecnych systemów AI oczekuje, że wszystkie obrazy będą wyrównane w jednej standardowej orientacji i tej samej rozdzielczości. Aby spełnić ten wymóg, ośrodki muszą cyfrowo przekręcać i skalować dane, co może rozmazać drobne detale i potencjalnie ukryć małe krwotoki. Rzeczywiste zbiory kliniczne dodają kolejną komplikację: nie każdy pacjent jest badany przy użyciu tych samych kontrastów, więc modele muszą radzić sobie z brakującymi informacjami.
Nowy wielopłaszczyznowy model AI, który zachowuje więcej obrazu
Aby rozwiązać te problemy, autorzy zaprojektowali „wielopłaszczyznowy vision transformer” (MP-ViT), typ AI pierwotnie rozwinięty do analizy obrazów naturalnych. Zamiast zmuszać wszystkie dane MRI do jednej płaszczyzny widzenia, MP-ViT ma dwa dedykowane kanały przetwarzania: jeden dla obrazów osiowych i jeden dla obrazów strzałkowych. Każdy kanał dzieli trójwymiarowy mózg na małe bloki, przekształca je w tokeny, które transformer może przetwarzać, a następnie uczy się wzorców mogących wskazywać obecność krwotoku. Kluczowe jest to, że te kanały nie działają jedynie równolegle i pozostaają oddzielne. Model wykorzystuje mechanizm cross-attention, aby umożliwić wymianę informacji między dwoma kanałami, naśladując sposób, w jaki radiolog mentalnie łączy widoki z różnych kątów, by uzyskać jaśniejszy ogólny obraz mózgu.
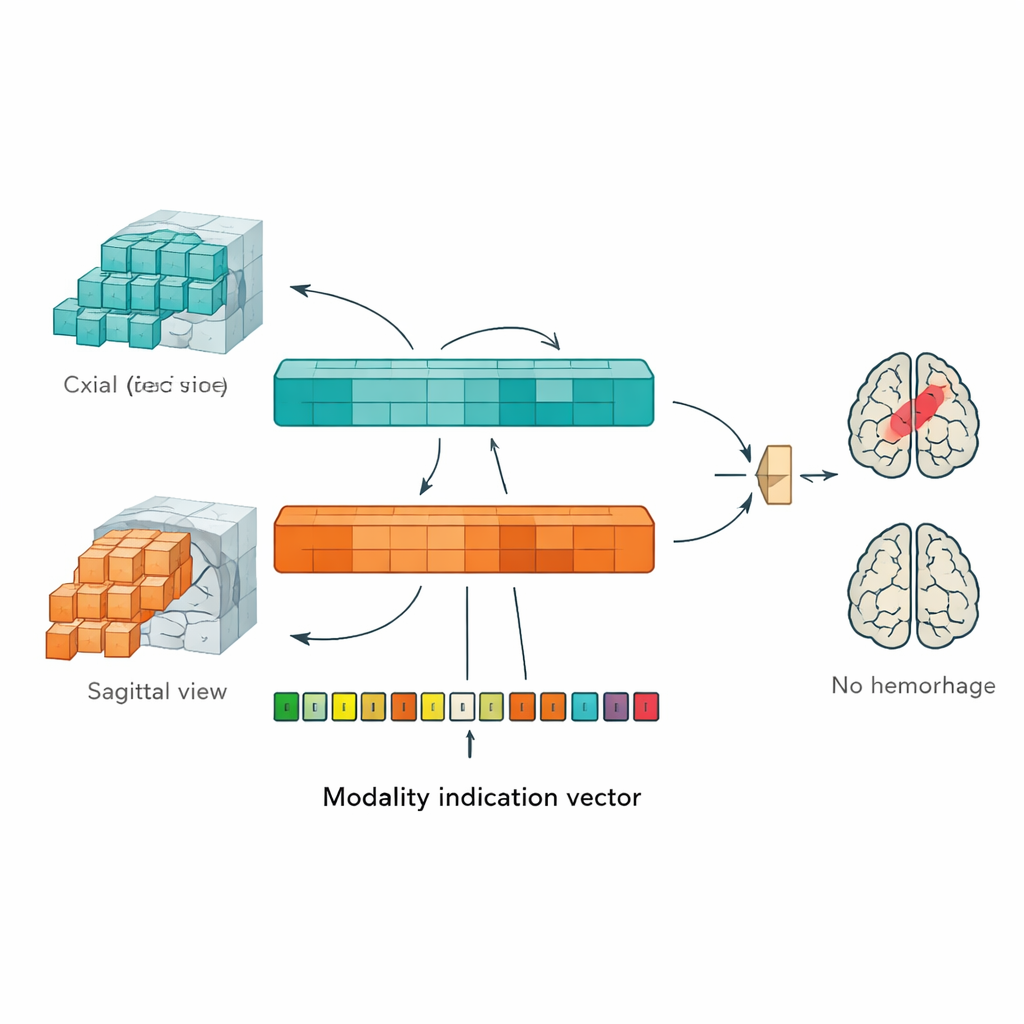
Radzenie sobie z brakującymi rodzajami skanów za pomocą sygnału wskazującego
W rzeczywistych przepływach pracy szpitalnej nie każdy pacjent ma ten sam zestaw kontrastów MRI; niektórzy mogą nie mieć określonych sekwencji, na przykład szczególnie wrażliwych na krwawienie. Aby uczynić AI odporną na takie luki, autorzy dodali „wektor wskazania modalności” — prosty kod informujący model, jakie typy obrazów są obecne, a jakich brakuje dla danego pacjenta. Ten wektor jest przekształcany w zestaw wewnętrznych sygnałów, które wchodzą w interakcję z wyuczonymi cechami modelu poprzez dodatkowy krok cross-attention. W praktyce sieć jest kierowana do dostosowania swoich oczekiwań, gdy pewne rodzaje informacji są niedostępne, zamiast być zdezorientowaną lub nadmiernie pewną siebie. Takie rozwiązanie sprawia, że MP-ViT lepiej nadaje się do nieuporządkowanych, niespójnych danych występujących w codziennej praktyce klinicznej.
Jak dobrze działa nowa metoda
Naukowcy trenowali i testowali MP-ViT na dużym, rzeczywistym zbiorze obejmującym ponad 12 000 badań MRI pochodzących od trzech głównych producentów skanerów, oznaczonych przez doświadczonych radiologów jako wykazujące ostry lub podostra krwotok wewnątrzczaszkowy albo jego brak. Na niezależnym zestawie testowym MP-ViT osiągnął pole pod krzywą (AUC) równe 0,854, miarę jakości rozdzielania przypadków z krwotokiem od tych bez krwotoku dla wszystkich możliwych progów decyzyjnych. Wynik ten był wyraźnie wyższy niż w przypadku standardowego vision transformera pracującego z jednej płaszczyzny oraz w porównaniu z kilkoma znanymi architekturami sieci konwolucyjnych, takimi jak ResNet i DenseNet. Testy statystyczne potwierdziły, że te różnice raczej nie wynikają z przypadku. Wewnętrzna analiza wykazała również, że uwzględnienie wektora wskazania modalności poprawiło wydajność o ponad jeden punkt procentowy, co podkreśla wartość jawnego informowania modelu o dostępnych typach skanów.
Co to może oznaczać dla przyszłej opieki
Dla osoby niebędącej specjalistą najważniejsze jest, że badanie pokazuje inteligentniejszy sposób, w jaki AI może czytać skany MRI: analizuje mózg z więcej niż jednego kąta, zachowuje więcej oryginalnych detali i dostosowuje się, gdy brakuje pewnych rodzajów obrazów. Chociaż praca była oceniana na jednym wewnętrznym zbiorze danych i koncentrowała się wyłącznie na klasyfikacji, a nie na precyzyjnym wyznaczaniu zarysów krwotoków, pokazuje, że starannie zaprojektowane transformatory mogą lepiej odpowiadać na nieuporządkowaną rzeczywistość obrazowania klinicznego. Jeśli zostaną szerzej zwalidowane i odpowiedzialnie zintegrowane z procesami szpitalnymi, metody takie jak MP-ViT mogą pomóc radiologom w bardziej niezawodnym wykrywaniu krwotoków mózgu zarówno w sytuacjach nagłych związanych z udarem, jak i w rutynowych badaniach ambulatoryjnych, potencjalnie przyspieszając leczenie i poprawiając bezpieczeństwo pacjentów.
Cytowanie: Das, B.K., Zhao, G., Mailhe, B. et al. Multi-plane vision transformer for hemorrhage classification using axial and sagittal MRI data. Sci Rep 16, 9333 (2026). https://doi.org/10.1038/s41598-026-44524-2
Słowa kluczowe: krwotok mózgu, MRI, Sztuczna inteligencja w obrazowaniu medycznym, vision transformer, diagnoza udaru