Clear Sky Science · pl
Stochastyczny ramowy model prywatności osadzony w rozkładzie Poissona dla uczenia federacyjnego z homomorficznym szyfrowaniem w medycznej sztucznej inteligencji
Chroniąc medyczne tajemnice podczas uczenia maszyn
Szpitale gromadzą ogromne liczby zdjęć rentgenowskich, które mogą pomóc lekarzom wykrywać choroby takie jak COVID‑19 szybciej i dokładniej. Te obrazy są jednak też bardzo osobiste, a surowe przepisy dotyczące prywatności utrudniają zbieranie danych w jednym miejscu w celu treningu wydajnych narzędzi sztucznej inteligencji (AI). Badanie przedstawia sposób, w jaki szpitale mogą współpracować przy wspólnym systemie diagnostyki rentgenowskiej, nie przekazując nigdy swoich surowych zdjęć innym podmiotom — z zamiarem zabezpieczenia danych pacjentów przy jednoczesnym zachowaniu wysokiej dokładności.
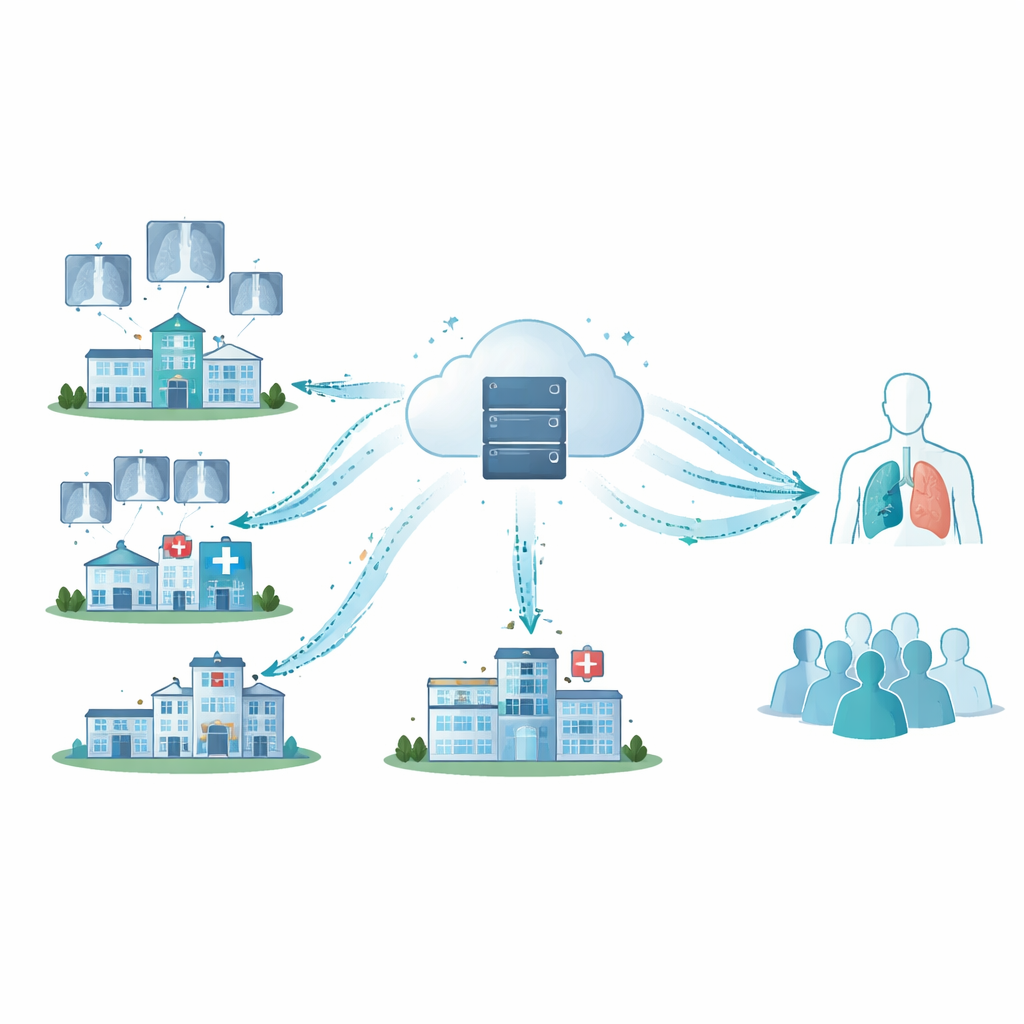
Dlaczego udostępnianie danych medycznych jest tak trudne
Nowoczesna AI potrzebuje dużych, zróżnicowanych zbiorów danych, tymczasem szpitale zwykle przechowują obrazy lokalnie i niechętnie — albo prawnie nie mogą — wysyłać ich na centralny serwer. Tradycyjne metody kopiowania wszystkich danych do jednej, dużej bazy niosą ryzyko wycieków i cyberataków, podważając zaufanie publiczne i łamiąc regulacje. Nawet nowsze podejścia, w których szpitale wspólnie trenują model w układzie zwanym „uczeniem federacyjnym”, nie są w pełni bezpieczne: wyrafinowani napastnicy mogą czasem odtworzyć obrazy pacjentów na podstawie aktualizacji modelu. Równocześnie dane medyczne bywają nierówne i chaotyczne — niektóre placówki mają znacznie więcej przypadków danej choroby niż inne — co może destabilizować trening i obniżać wiarygodność wyników.
Kooperacyjna sieć, która nigdy nie udostępnia surowych zdjęć rentgenowskich
Autorzy opracowali ramy uczenia federacyjnego oparte na silnym modelu rozpoznawania obrazów znanym jako ResNet‑50, służącym do rozróżniania COVID‑19 od prawidłowych zdjęć klatki piersiowej. Każdy szpital trenuje własną kopię tego modelu na lokalnych obrazach, zachowując wszystkie zdjęcia na miejscu. Zamiast wysyłać obrazy, szpitale przekazują jedynie numeryczne aktualizacje opisujące, jak ich lokalny model powinien się zmienić. Serwer centralny uśrednia te aktualizacje, tworząc ulepszony model globalny, a następnie odsyła go z powrotem do każdego szpitala. Powtarzanie tego cyklu pozwala wspólnemu modelowi korzystać z doświadczenia wszystkich uczestników, bez ujawniania pojedynczych badań.
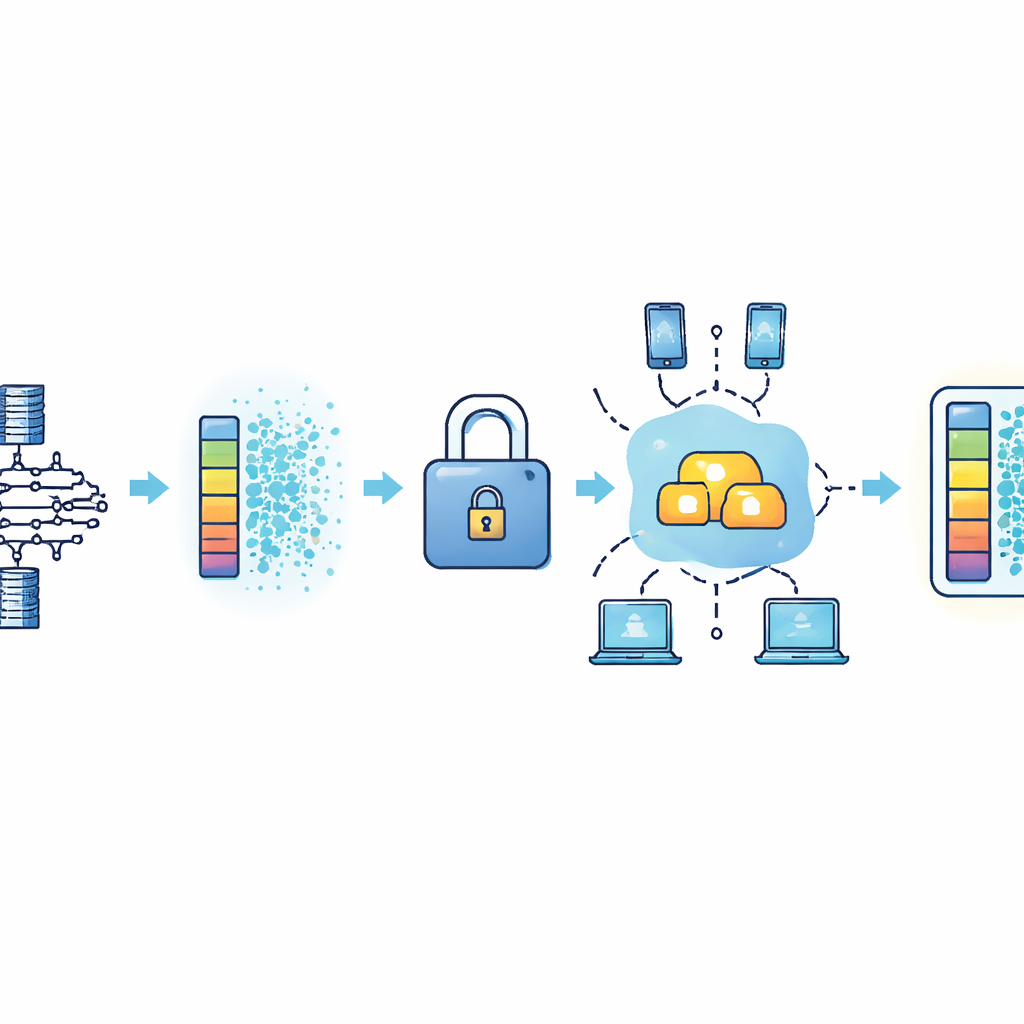
Dodanie cyfrowego „szumu” i sejfów dla dodatkowej prywatności
Aby uniemożliwić napastnikom odtworzenie obrazów pacjentów na podstawie aktualizacji modelu, ramy nakładają dwie techniki prywatności na uczenie federacyjne. Po pierwsze, każdy szpital dodaje ostro skalibrowany losowy szum do swoich aktualizacji modelu — coś w rodzaju dodania szumu do sygnału radiowego, dzięki czemu trudniej wyłapać pojedyncze głosy, podczas gdy ogólny przekaz pozostaje czytelny. Po drugie, zanim aktualizacje zostaną przesłane przez sieć, są szyfrowane metodą, która pozwala serwerowi sumować je, pozostając przy tym zaszyfrowanym — podobnie jak sumowanie wartości w zamkniętych kopertach. Tylko zaufany posiadacz klucza może odszyfrować skombinowany wynik, a serwer centralny nigdy nie widzi żadnej pojedynczej aktualizacji w postaci jawnej. Te kroki razem mają zniechęcić do prób inżynierii wstecznej danych pacjentów przy jednoczesnym zachowaniu użyteczności wspólnego modelu.
Testy systemu
Zespół ocenił swoje ramy na zbilansowanym zbiorze zdjęć rentgenowskich klatki piersiowej z COVID‑19 i bez niego, symulując kilka szpitali jako oddzielne miejsca treningowe. Porównali trzy konfiguracje: klasyczny trening scentralizowany ze wszystkimi danymi w jednym miejscu, standardowe uczenie federacyjne bez dodatkowych zabezpieczeń oraz ich podejście z wzmocnioną prywatnością. Pomimo dodanego szumu i szyfrowania, chroniony system osiągnął imponująco wysokie wyniki — około 99,6% dokładności, z podobnie silnymi miarami precyzji, czułości i F1 — dorównując lub przewyższając zarówno wersję scentralizowaną, jak i federacyjną bez ochrony. Pomiar liczby rund komunikacji, strat treningowych i czasu obliczeń pokazuje, że dokładność stopniowo rośnie wraz ze współpracą placówek, a dodatkowy koszt czasowy związany z szyfrowaniem pozostaje umiarkowany. Eksperymenty ablacyjne, w których części systemu są wyłączane lub włączane, potwierdzają, że dobrane poziomy szumu i strategia szyfrowania z kompresją zapewniają silną prywatność przy jedynie niewielkich kompromisach wydajności.
Co to oznacza dla przyszłej opieki
Dla osób niebędących ekspertami kluczowy przekaz jest taki, że praca ta pokazuje praktyczną receptę na uczenie AI na podstawie zdjęć rentgenowskich wielu szpitali bez ujawniania surowych obrazów lub osłabiania przepisów o prywatności. Łącząc wysoko wydajny model obrazowy z cyfrowym „szumem” i zaszyfrowaną agregacją, ramy demonstrują, że szpitale mogą wspólnie budować dokładne narzędzia diagnostyczne, jednocześnie przechowując dokumentację pacjentów lokalnie i poza zasięgiem niepowołanych osób. Choć testy przeprowadzono na stosunkowo małym zbiorze i skupiono się na rentgenach związanych z COVID‑19, te same pomysły można rozszerzyć na inne choroby, rodzaje obrazowania, a nawet wrażliwe dziedziny poza medycyną, jak finanse. Krótko mówiąc, badanie wskazuje na przyszłość, w której potężna AI i silna prywatność medyczna mogą się wzajemnie wzmacniać, zamiast być ze sobą sprzeczne.
Cytowanie: Gomathi, R., Saranya, K., Mahaboob John, Y.M. et al. Stochastic Poisson-embedded privacy framework for federated learning with secure homomorphic encryption in medical AI. Sci Rep 16, 10931 (2026). https://doi.org/10.1038/s41598-026-41469-4
Słowa kluczowe: uczenie federacyjne, obrazowanie medyczne, prywatność danych, szyfrowanie homomorficzne, diagnoza na podstawie zdjęć rentgenowskich