Clear Sky Science · pl
Wczesne wykrywanie przewlekłej choroby nerek oparte na modelu uczenia maszynowego wzmocnionym metodą SURD
Dlaczego wczesne wykrycie problemów z nerkami ma znaczenie
Przewlekła choroba nerek często rozwija się po cichu, dając niewiele ostrzegawczych sygnałów, dopóki nerki nie są poważnie uszkodzone. Tymczasem proste badania krwi i moczu mogą ujawnić problemy wiele lat wcześniej, kiedy leczenie może spowolnić lub nawet zapobiec poważnemu pogorszeniu. W tym badaniu autorzy badają nowy sposób analizy tych rutynowych wyników testów przy użyciu zaawansowanych, lecz interpretowalnych modeli komputerowych, aby osoby o wysokim ryzyku mogły zostać wykryte wcześniej, a lekarze rozumieli, dlaczego tak się dzieje.
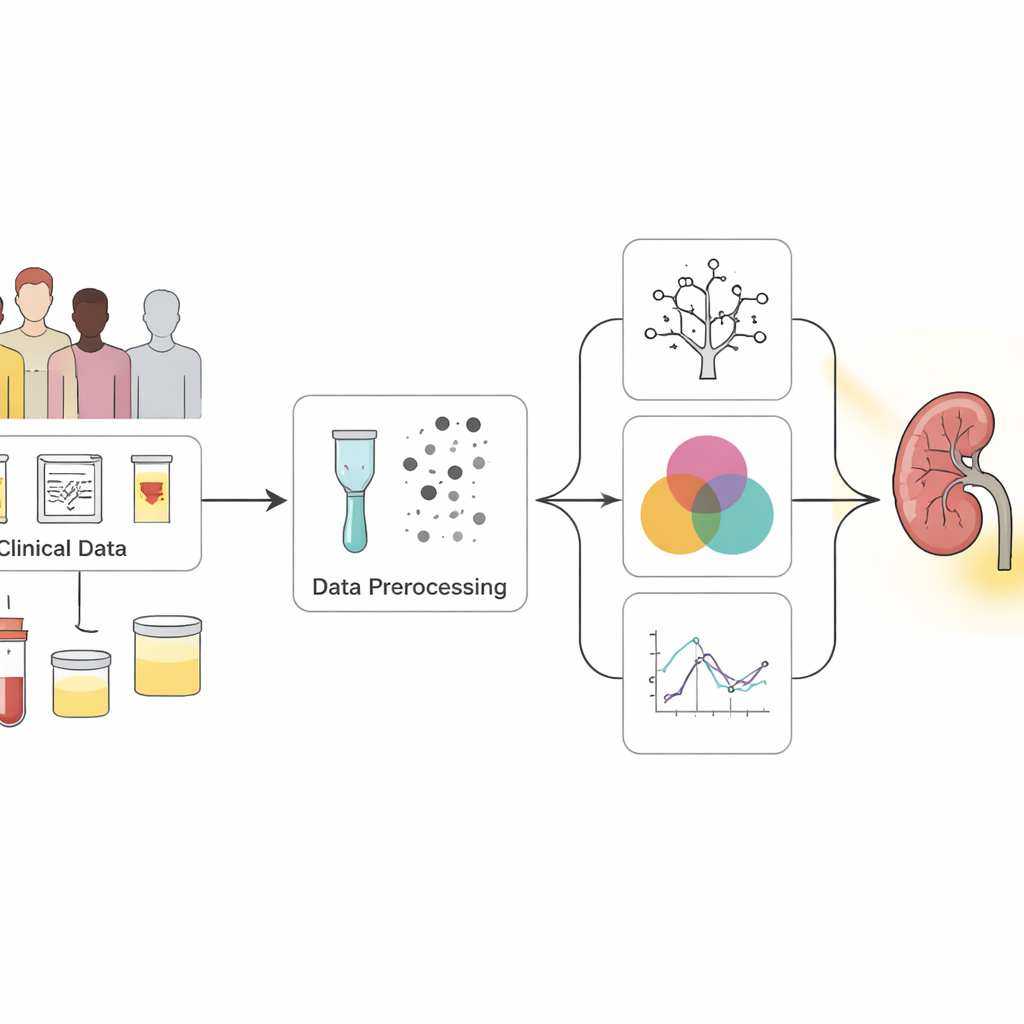
Przekształcanie nieuporządkowanych danych z badań w czytelne sygnały
Naukowcy rozpoczęli od powszechnie stosowanego publicznego zbioru danych zawierającego 400 osób, z których większość miała już rozpoznaną przewlekłą chorobę nerek. Każda osoba miała 25 pomiarów, od ciśnienia krwi i parametrów krwi po wyniki badania moczu oraz historię medyczną, taką jak cukrzyca i nadciśnienie. Wiele wpisów było niekompletnych, więc zespół zastosował staranne techniki statystyczne do uzupełnienia brakujących wartości zamiast po prostu odrzucać pacjentów. Wyważono też dane tak, by przypadki zdrowe i chorobowe były bardziej równomiernie reprezentowane, co ułatwiło modelom komputerowym naukę rozpoznawania obu grup w sposób sprawiedliwy.
Wykraczanie poza proste korelacje
Większość narzędzi predykcyjnych w medycynie traktuje każdy wynik testu oddzielnie: analizują, jak silnie jeden pomiar, na przykład poziom cukru we krwi, wiąże się z chorobą. Jednak w organizmie czynniki ryzyka rzadko działają samodzielnie. Niektóre testy przekazują niemal te same informacje, podczas gdy inne stają się informacyjne dopiero w połączeniu z innymi. Aby to uchwycić, autorzy zastosowali ramę nazwaną SURD, która rozkłada wkład każdej cechy na trzy części: informacje współdzielone z innymi testami, informacje unikalne oraz informacje pojawiające się tylko wtedy, gdy cechy działają wspólnie. Pozwoliło to pogrupować wartości laboratoryjne i ustalenia kliniczne na zbiory „unikalne”, „redundantne” i „synergiczne” zanim podano je modelom predykcyjnym.
Nauka wielu modeli i wybór najbardziej wiarygodnego
Mając te grupy cech oparte na SURD, zespół wytrenował dziesięć różnych modeli uczenia maszynowego, od prostych drzew decyzyjnych po bardziej złożone podejścia, takie jak lasy losowe i sieci neuronowe. Porównywali wydajność modeli korzystających ze wszystkich dostępnych cech z wydajnością modeli używających jedynie połączonego zestawu cech unikalnych i synergicznych. We wszystkich niemal typach modeli ten odchudzony, prowadzony przez SURD zestaw cech wypadał równie dobrze lub lepiej niż pełna kolekcja 25 zmiennych, często poprawiając równowagę między poprawnym identyfikowaniem chorych pacjentów a unikaniem fałszywych alarmów. W szczególności modele oparte na drzewach, takie jak lasy losowe i modele boostowane, osiągnęły niemal perfekcyjne wyniki na oryginalnym zbiorze danych.
Testowanie metody na danych szpitalnych z rzeczywistej praktyki
Świetna wydajność na małym zestawie benchmarkowym może być myląca, jeśli model zawiedzie po zetknięciu z bardziej zróżnicowanymi pacjentami. Aby się przed tym zabezpieczyć, autorzy zweryfikowali swoje podejście używając znacznie większej bazy danych szpitalnych obejmującej ponad 27 000 pacjentów oddziałów intensywnej terapii. Tutaj model lasu losowego zbudowany na wyselekcjonowanych cechach SURD wciąż rozróżniał pacjentów z chorobą nerek i bez niej z wyjątkowo wysoką dokładnością. Jego wydajność wyraźnie przewyższała prostsze drzewo decyzyjne, co wskazuje, że metoda może uogólniać się poza starannie wyselekcjonowany zbiór badawczy do bardziej chaotycznych, rzeczywistych zapisów medycznych.
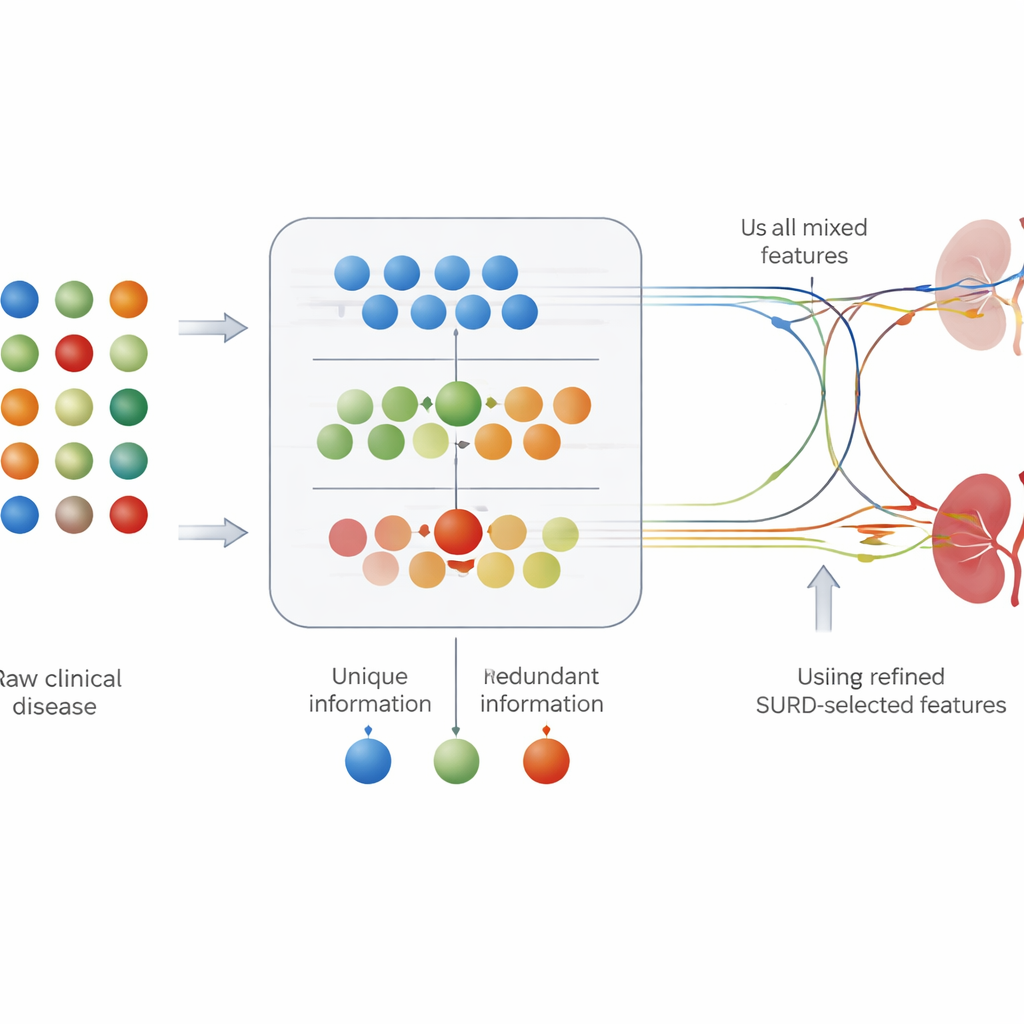
Widzienie, które testy mają znaczenie i w jaki sposób
Sama dokładność nie wystarcza w zastosowaniach klinicznych; lekarze muszą także wiedzieć, które wyniki badań napędzają przewidywanie. Badanie połączyło SURD z nowoczesnymi narzędziami wyjaśniającymi, które przypisują każdej cesze wkład w decyzję modelu dla konkretnego pacjenta. Analiza ta uwydatniła znane markery ryzyka, takie jak stężenie kreatyniny w surowicy (bezpośredni wskaźnik funkcji nerek), poziom hemoglobiny, zagęszczenie moczu oraz obecność cukrzycy czy nadciśnienia. Co ciekawe, SURD pokazał, że niektóre z tych czynników działają głównie w połączeniu z innymi, podczas gdy kreatynina wyróżnia się jako silnie informacyjny sygnał sama w sobie. Razem te techniki oferują zarówno globalny obraz, na których testach model się opiera, jak i rozbicia na poziomie pacjenta wyjaśniające, dlaczego dana osoba jest przewidywana jako obarczona wysokim ryzykiem.
Co to oznacza dla codziennej opieki
Mówiąc prosto, badanie wykazuje, że możliwe jest zbudowanie kalkulatora ryzyka choroby nerek, który jest zarówno wysoce dokładny, jak i stosunkowo przejrzysty. Poprzez oddzielenie nakładających się informacji od naprawdę unikalnych danych w rutynowych wynikach laboratoryjnych i historii choroby, modele prowadzone przez SURD formułują ostrzejsze przewidywania, nie stając się przy tym tajemniczą czarną skrzynką. Chociaż konieczne są dalsze prace na szerszych i bardziej zróżnicowanych grupach pacjentów, podejście to mogłoby ostatecznie pomóc klinicystom wcześniej dostrzegać problemy nerkowe, skupić uwagę na najbardziej informatywnych testach i w prostych słowach wyjaśniać pacjentom, które aspekty ich zdrowia zagrażają nerek.
Cytowanie: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Słowa kluczowe: przewlekła choroba nerek, predykcja ryzyka nerek, medyczne uczenie maszynowe, wyjaśnialna sztuczna inteligencja, elektroniczne rekordy zdrowotne