Clear Sky Science · pl
Dynamiczne podejście uczenia maszynowego do prognozowania obciążenia w środowiskach chmurowych
Dlaczego inteligentne prognozowanie ruchu ma znaczenie
Za każdym razem, gdy oglądasz strumieniowo wideo, śledzisz duże wydarzenie sportowe online lub robisz zakupy podczas wyprzedaży błyskawicznej, tysiące innych osób mogą klikać w tym samym momencie. W tle centra danych w chmurze starają się utrzymać strony szybkie, nie marnując przy tym pieniędzy na bezczynne maszyny. Artykuł odpowiada na proste pytanie o wielkim praktycznym znaczeniu: jak systemy chmurowe mogą przewidzieć nagłe fale ruchu na tyle dobrze, by włączać i wyłączać serwery w samą porę, zamiast zgadywać i przepłacać?
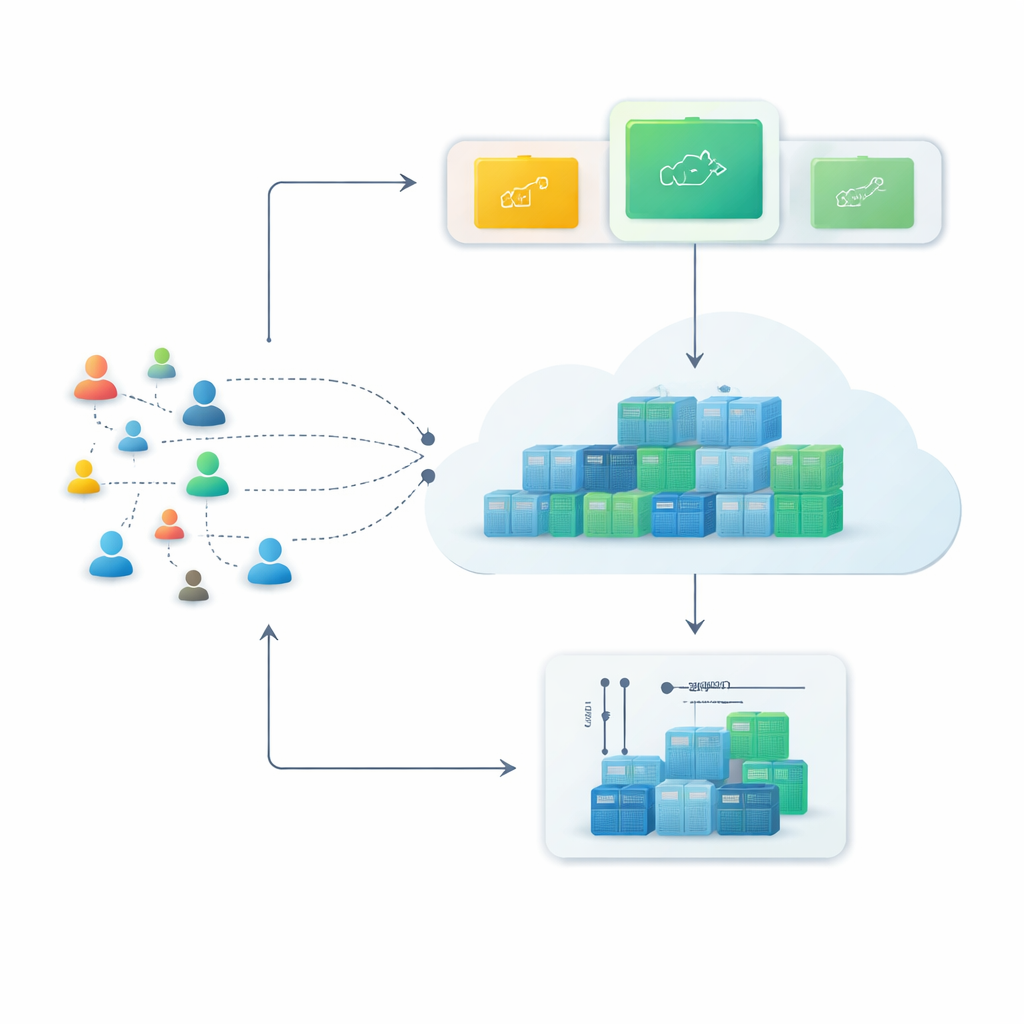
Od sztywnych serwerów do elastycznych kontenerów
Nowoczesne platformy chmurowe coraz częściej polegają na kontenerach — małych pakietach oprogramowania, które można uruchomić lub zatrzymać w ciągu kilku sekund. W porównaniu z tradycyjnymi maszynami wirtualnymi kontenery są lżejsze i można je gęściej upakować, co czyni je idealnymi dla usług, które muszą szybko się rozrastać w godzinach szczytu i potem ponownie kurczyć. Jednak ta elastyczność ma sens tylko wtedy, gdy system potrafi przewidzieć nadchodzące problemy — czyli ile żądań webowych przyjdzie w najbliższych minutach i przygotować odpowiednią liczbę kontenerów z wyprzedzeniem.
Dlaczego uniwersalne prognozowanie zawodzi
Wcześniejsze badania stosowały wiele sposobów prognozowania ruchu sieciowego — od klasycznych metod statystycznych po głębokie sieci neuronowe. Niektóre działają dobrze, gdy zapotrzebowanie zmienia się płynnie w ciągu dnia; inne radzą sobie lepiej, gdy ruch gwałtownie skacze, na przykład podczas meczu Mistrzostw Świata. Problem polega na tym, że żadna metoda nie jest najlepsza przez cały czas. Jeśli operatorzy wybiorą jeden ulubiony model i się go trzymają, dokładność może gwałtownie spaść za każdym razem, gdy zmieni się zachowanie użytkowników, co prowadzi albo do wolnych stron, albo do szeregu niedowykorzystanych maszyn, które po cichu zużywają pieniądze i energię.
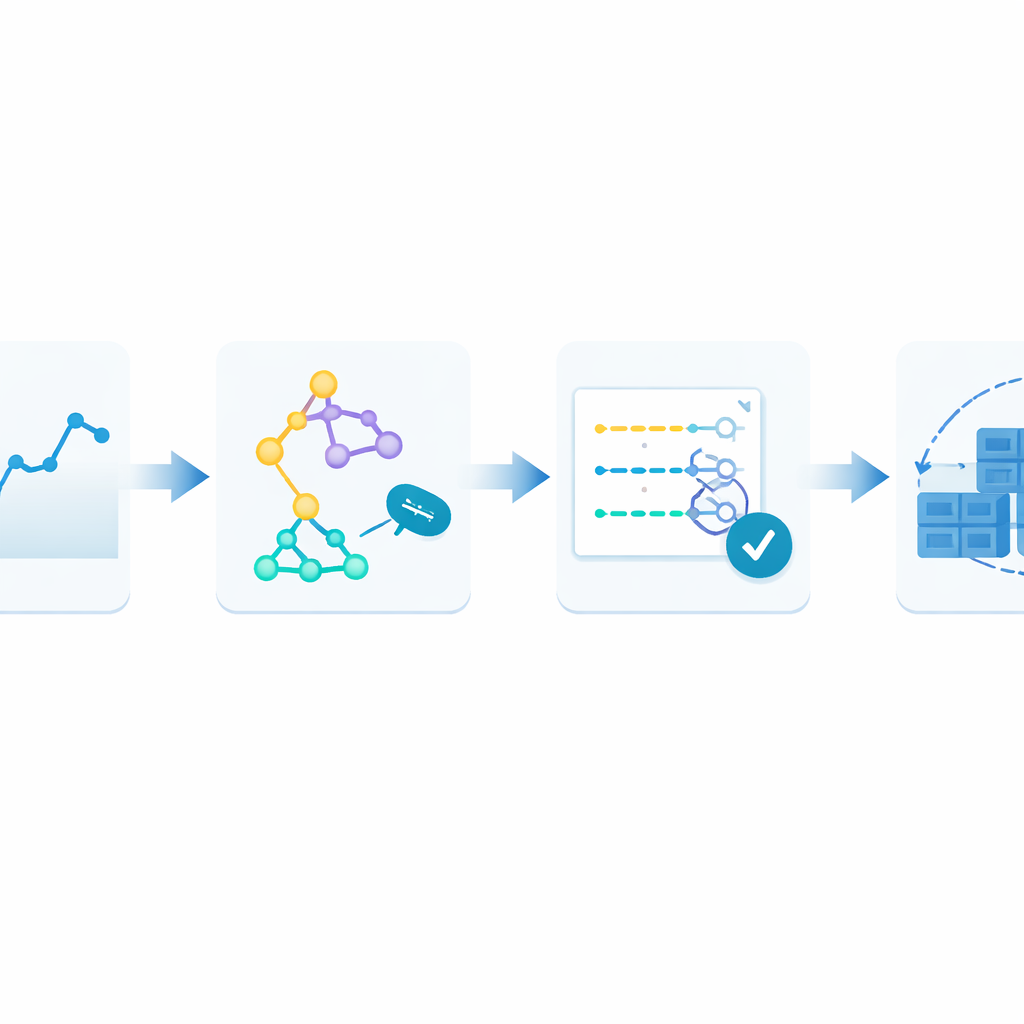
Pętla uczenia, która nigdy nie przestaje się dostosowywać
Aby to przezwyciężyć, autorzy proponują zamknięty framework nazwany Monitor–Train–Test–Deploy. Pomysł polega na traktowaniu prognozowania jako proces żywy. Najpierw system ciągle zapisuje przychodzące żądania webowe do historii z oznaczonymi znacznikami czasowymi. Następnie równolegle trenuje kilka różnych metod prognozowania, z których każda próbuje wyłapać wzorce w tej niedawnej historii. Potem testuje te kandydackie modele na najnowszych danych i ocenia je według tego, jak bardzo ich przewidywania odbiegają od rzeczywistości. Tylko najlepiej działający model zostaje odpowiedzialny za prognozy na żywo, które wskazują, ile kontenerów uruchomić. W miarę napływu świeżego ruchu pętla się powtarza: jeśli błędy prognoz przekroczą tolerowany poziom przez dwa cykle z rzędu, system automatycznie przeprowadza retrening i może przekazać kontrolę innemu modelowi.
Testowanie frameworku
Badacze ocenili to podejście, używając zarówno syntetycznych, jak i rzeczywistych śladów aktywności webowej. Wygenerowali kilka wzorców idealizowanych — gładkie krzywe dzwonowe, stopniowo rosnące obciążenia o różnych prędkościach oraz bardzo nieregularny ruch — a także użyli zapisów ze stron oficjalnych Mistrzostw Świata w 1998 i 2018 roku, gdzie zainteresowanie gwałtownie rośnie. W każdym przypadku porównali trzy lub cztery znane narzędzia prognostyczne, w tym metodę opartą na statystyce, model wektorów wspierających, zespół drzew decyzyjnych oraz, w późniejszych eksperymentach, popularny typ rekurencyjnej sieci neuronowej. Kluczowym wynikiem było to, że „zwycięzca” zmieniał się w zależności od sytuacji: proste modele statystyczne sprawdzały się, gdy zapotrzebowanie było stabilne, podczas gdy metody uczące się miały przewagę, gdy ruch stawał się dziki i skokowy.
Zyski w dokładności i wydajności
Dzięki ciągłemu przełączaniu się na model najlepiej dostosowany do obserwowanego zachowania, framework zmniejszył błędy prognozowania o około 15% w porównaniu z trzymaniem się dowolnego stałego modelu. Co równie ważne, osiągnięto to bez uruchamiania wszystkich modeli cały czas. Podczas pracy na żywo aktywny jest tylko jeden predyktor; pozostałe są okresowo retrenowane i sprawdzane, co utrzymuje obciążenie obliczeniowe na umiarkowanym poziomie. Autorzy wprowadzają także stopniowo zaostrzany próg decydujący o retreningu, tak aby system stawał się mniej tolerancyjny na powtarzające się błędy, zmniejszając ryzyko długich okresów złych prognoz.
Co to oznacza dla codziennych użytkowników chmury
W praktyce badanie pokazuje, że platformy chmurowe można obsługiwać inteligentniej, pozwalając modelom prognostycznym konkurować i dostosowując ich wybór w czasie. Dla użytkowników może to przekładać się na płynniejsze doświadczenia online podczas dużych wydarzeń i mniej spowolnień, gdy pojawią się niespodziewane tłumy. Dla dostawców oznacza to bardziej oszczędne wykorzystanie zasobów obliczeniowych, niższe koszty operacyjne i marnowanie mniej energii. Zamiast stawiać na jeden sprytny algorytm, praca ta opowiada się za elastyczną pętlą sterowania, która ciągle się uczy, testuje i koryguje przewidywanie zapotrzebowania w coraz bardziej nieprzewidywalnym cyfrowym świecie.
Cytowanie: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Słowa kluczowe: prognozowanie obciążenia chmury, autoskalowanie, kontenery, uczenie maszynowe, szeregi czasowe