Clear Sky Science · pl
System wyszukiwania wieloużytkownikowego z ochroną prywatności dla multimodalnej sztucznej inteligencji
Dlaczego ważne jest, by inteligentne wyszukiwania pozostawały prywatne
Wielu z nas polega dziś na chmurowej sztucznej inteligencji, która przeszukuje zdjęcia, dokumenty, a nawet skany medyczne. Systemy te są potężne, ponieważ potrafią rozumieć zarówno obrazy, jak i słowa, ale pojawia się trudne pytanie: jak korzystać z tej wygody, nie przekazując jednocześnie znaczenia naszych najwrażliwszych danych odległym serwerom? Artykuł przedstawia PMIRS, nowy system, który ma pozwolić wielu użytkownikom wyszukiwać w mieszanych zbiorach obrazowo-tekstowych, jednocześnie ukrywając ich informacje przed maszynami chmurowymi obsługującymi te wyszukiwania.
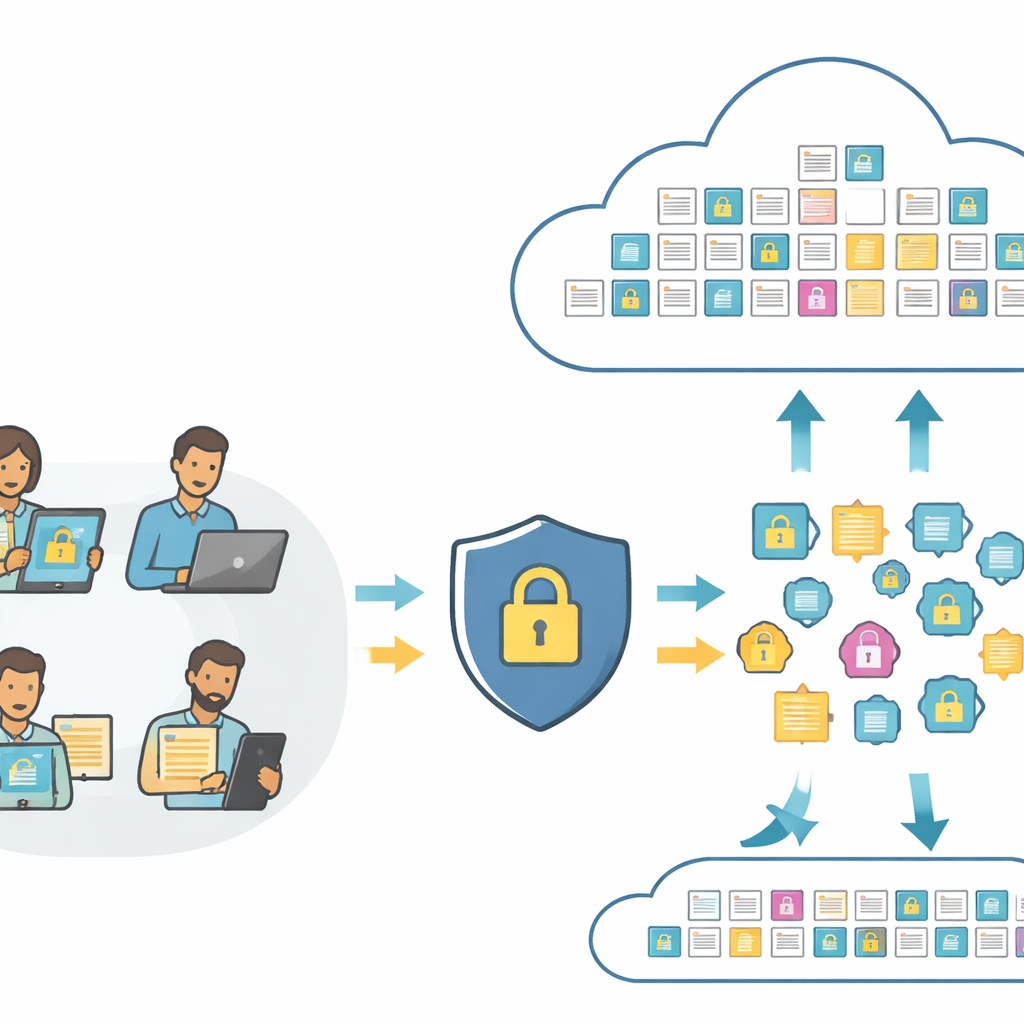
Wyszukiwanie obrazów i tekstu bez ujawniania ich znaczenia
U podstaw współczesnych narzędzi wyszukiwania leżą „embeddingi” — numeryczne odciski palców, które uchwycają zawartość zdjęcia lub zdania, aby komputer mógł je porównywać. Standardowe systemy wysyłają te odciski wprost do chmury, gdzie mogą być analizowane lub nawet nadużywane. PMIRS zmienia ten proces. Użytkownicy najpierw przesyłają surowe obrazy i tekst do lokalnej warstwy, która zamienia je na odciski za pomocą zwartego modelu wizji i języka. Zanim cokolwiek opuści urządzenie użytkownika, odciski są celowo pomieszane i następnie zaszyfrowane. Chmura widzi jedynie te chronione odciski oraz w pełni zaszyfrowane kopie przechowywanych danych, a mimo to może dokonywać dopasowań i zwracać najlepsze wyniki.
Uczenie się od wielu użytkowników bez łączenia ich danych
Trening dobrego modelu obraz–tekst zwykle wymaga zgromadzenia ogromnych ilości oznaczonych przykładów w jednym miejscu — co stanowi wyraźne ryzyko prywatności. PMIRS zamiast tego korzysta z uczenia federacyjnego. W tym rozwiązaniu podstawowy model, oparty na znanej architekturze CLIP, jest wysyłany do wielu urządzeń. Każde z nich szkoli się lokalnie na własnych prywatnych parach obraz–tekst i wysyła z powrotem jedynie zaktualizowane wagi modelu, które same są szyfrowane. Centralny serwer uśrednia te aktualizacje, aby ulepszyć wspólny model, nigdy nie widząc surowych zdjęć ani opisów użytkowników. Autorzy dodatkowo redukują i dopracowują model poprzez etapowy proces „destylacji”, który przycina niepotrzebne części przy zachowaniu dokładności, czyniąc system wystarczająco lekki do praktycznego wdrożenia.
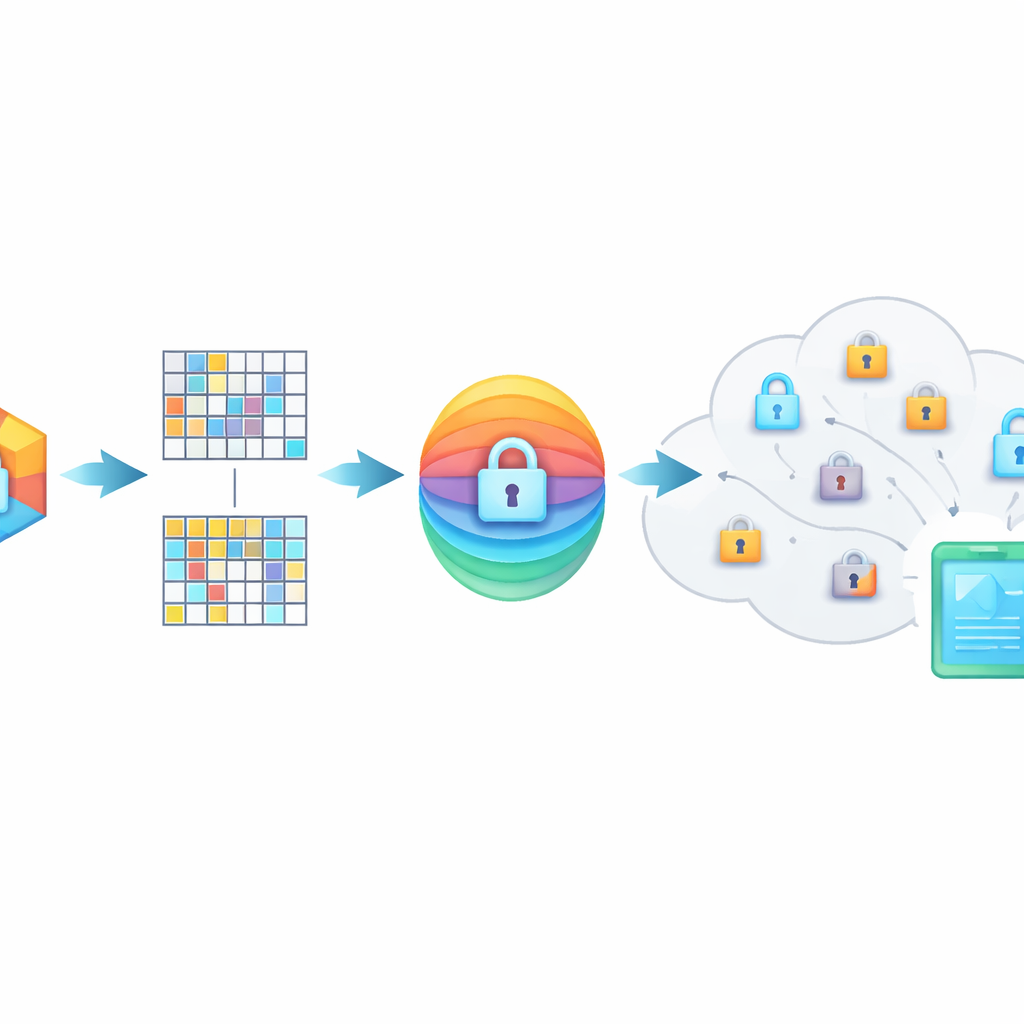
Ukrywanie znaczenia poprzez pomieszane odciski
PMIRS chroni zapytania za pomocą dwuwarstwowej tarczy. Najpierw każdy odcisk dzielony jest na bloki, a każdy blok przekształcany przy użyciu tajnej macierzy oraz starannie zaprojektowanego wzoru szumu. To mieszanie ukrywa oryginalną strukturę danych, ale jest skonstruowane tak, że gdy dwa powiązane elementy zostaną przekształcone w ten sam sposób, ich podobieństwo pozostaje niezmienione. Po drugie, wynik jest szyfrowany powszechnie stosowaną metodą AES, przy użyciu kluczy, które nigdy nie są przesyłane jawnie przez sieć. W sytuacjach, gdy jedna osoba musi przeszukać dane innej osoby — na przykład lekarz konsultujący się ze specjalistą — system używa protokołu wymiany kluczy Diffie–Hellmana, aby mogli uzgodnić wspólne sekrety bez ich ujawniania podsłuchującym.
Jak system sprawdza się w praktyce
Aby sprawdzić, czy te zabezpieczenia nie obciążają zbytnio wydajności, badacze zbudowali benchmark łączący codzienne obrazy z krótkimi frazami w języku naturalnym — bliżej temu, jak ludzie rzeczywiście opisują rzeczy, niż pojedyncze etykiety. Porównali PMIRS ze standardowym wyszukiwaniem opartym na CLIP w trzech kategoriach: sceny przyrodnicze, przedmioty wytworzone oraz aktywności lub krajobrazy. W różnych rozmiarach repozytoriów PMIRS konsekwentnie osiągał lepszą równowagę między odnajdywaniem wszystkich właściwych wyników (czułość) a unikaniem fałszywych trafień (precyzja), prowadząc do średniego wyniku F1 — skumulowanej miary dokładności — około 7,7% wyższego niż punkt odniesienia. Co ważne, czasy odpowiedzi utrzymywały się poniżej około 180 milisekund, wystarczająco szybko do interaktywnego użycia, i często były nieco szybsze niż niechroniona baza mimo dodatkowych kroków ochronnych.
Co to oznacza dla użytkowników na co dzień
Mówiąc prosto, PMIRS pokazuje, że można zbudować chmurowe narzędzia wyszukujące, które dobrze rozumieją obrazy i tekst, obsługują wielu użytkowników jednocześnie, a jednocześnie utrzymują znaczenie danych każdej osoby poza zasięgiem dostawcy chmury. Łącząc lokalne szkolenie, sprytne mieszanie odcisków, silne szyfrowanie i bezpieczną wymianę kluczy, system oferuje kompleksową, chroniącą prywatność ścieżkę end-to-end, zamiast zabezpieczać tylko pojedynczy etap. Choć nie obejmuje jeszcze wszystkich możliwych ataków i będzie wymagać dalszych udoskonaleń oraz prób w rzeczywistych warunkach, praca wskazuje kierunek dla przyszłych usług — takich jak wyszukiwanie obrazów medycznych, boty wsparcia klienta czy archiwa przedsiębiorstw — gdzie użytkownicy mogą korzystać z bogatego, multimodalnego wyszukiwania AI przy znacznie mniejszym ryzyku ujawnienia lub nadużycia ich treści.
Cytowanie: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Słowa kluczowe: AI chroniąca prywatność, wyszukiwanie multimodalne, uczenie federacyjne, wyszukiwanie szyfrowane, bezpieczne przetwarzanie w chmurze