Clear Sky Science · pl
Nowe ilościowe modele odpowiedzi losowej wykorzystujące opcjonalne i częściowe zaciemnianie dla danych wrażliwych
Dlaczego zadawanie trudnych pytań jest takie problematyczne
Wiele z najważniejszych pytań społecznych — dotyczących używania narkotyków, ukrytych dochodów, uchylania się od płacenia podatków czy nielegalnych zachowań — to właśnie te, na które ludzie najmniej chcą odpowiadać uczciwie. Jeśli obawiają się oceny lub kary, mogą kłamać albo odmawiać odpowiedzi, co zniekształca wyniki badań. W artykule przedstawiono nowe sposoby projektowania ankiet, które pozwalają ludziom bezpiecznie ukryć swoje osobiste odpowiedzi, jednocześnie umożliwiając badaczom dokładne oszacowanie, jak powszechne są te wrażliwe zachowania w populacji.
Jak przypadek może chronić twoją prywatność
Od lat 60. XX wieku statystycy stosują sprytny trik znany jako odpowiedź losowa. Zamiast odpowiadać bezpośrednio na wrażliwe pytanie, osoba korzysta z losowego urządzenia — na przykład rzutu monetą lub wirnika — by zdecydować, czy powiedzieć prawdę, czy podać zamaskowaną odpowiedź. Ponieważ tylko respondent widzi wynik losowania, nikt z zewnątrz nie może wiedzieć, czy dana odpowiedź jest autentyczna. Znając jednak reguły losowania, badacze mogą odtworzyć dokładne średnie dla całej grupy. Późniejsze prace rozszerzyły ten pomysł z pytań tak/nie na pytania liczbowe, takie jak ile razy ktoś złamał prawo czy ile ma nieujawnionych dochodów.

Pozwolenie ludziom wybrać, ile chcą ukryć
Tradycyjne metody ochrony prywatności traktują wszystkich tak samo: odpowiedź każdego respondenta jest zaciemniana w identyczny sposób, nawet jeśli niektórzy nie są szczególnie zaniepokojeni danym pytaniem. Takie podejście „jeden rozmiar dla wszystkich” może marnować informację i wciąż nie przekonać ostrożnych osób, że są bezpieczne. Aby to naprawić, badacze opracowali modele opcjonalne. W nich każda osoba może albo podać swoją prawdziwą liczbę, albo wysłać wersję zaciemnioną, w zależności od poziomu komfortu. Nowe badanie rozwija tę ideę dla danych liczbowych, tworząc cztery modele łączące odpowiedzi bezpośrednie z różnymi typami zaciemniania — czasem dodawaniem losowego szumu, czasem mnożeniem przez losowy czynnik, a czasem użyciem kilku etapów losowania.
Cztery nowe sposoby równoważenia bezpieczeństwa i dokładności
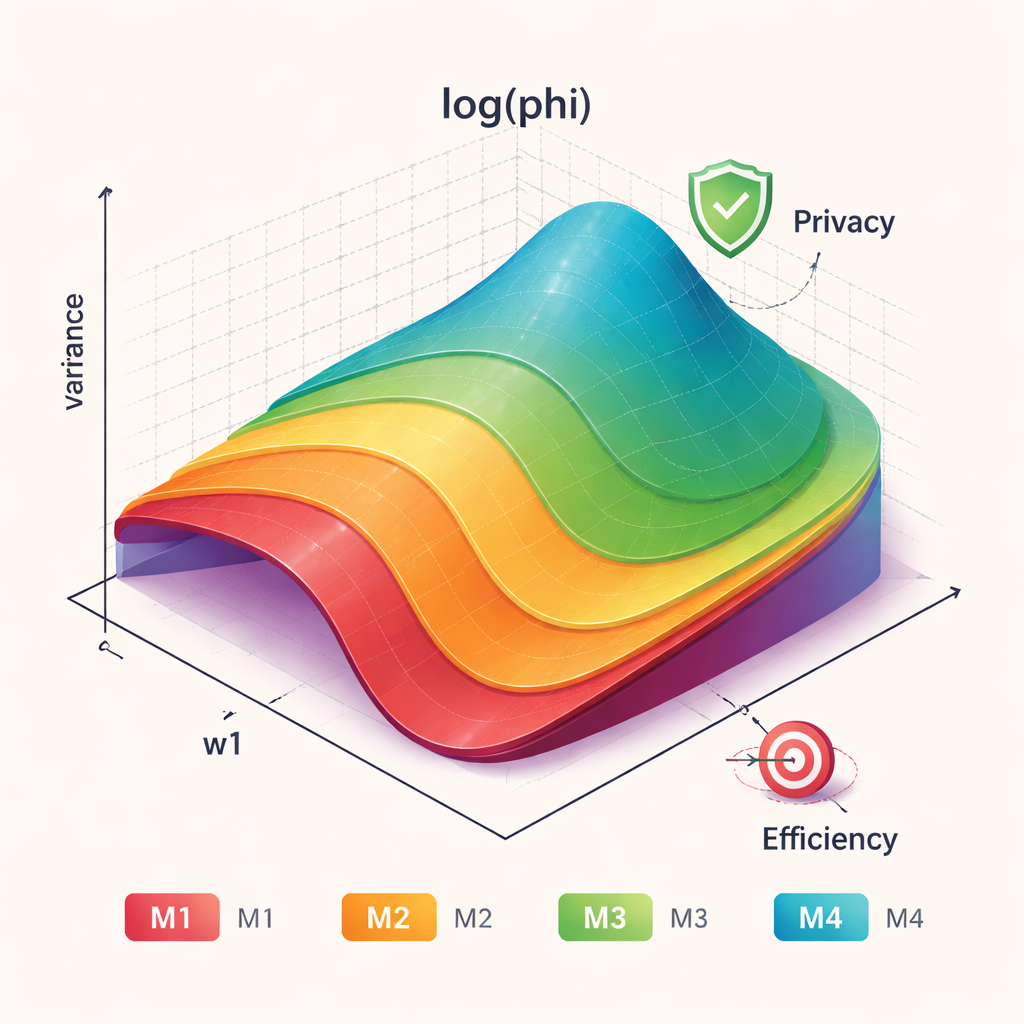
Autorzy przedstawiają cztery powiązane modele oznaczone M1 do M4. Wszystkie mają na celu oszacowanie średniego poziomu wrażliwej wielkości w populacji bez obciążenia, co oznacza, że średnio odtwarzają prawdziwą wartość. M1 rozszerza istniejącą metodę przez dodanie drugiego etapu losowania, co zwiększa niepewność co do odpowiedzi pojedynczej osoby, przy zachowaniu prostoty obliczeń. M2 łączy pierwszy krok, w którym niektórzy odpowiadają bezpośrednio, z drugim krokiem zaciemniającym odpowiedzi albo przez mnożenie, albo przez dodanie losowego szumu. M3 i M4 dalej uogólniają wcześniejsze projekty z wieloma opcjami, dając respondentom kilka możliwych zamaskowanych form ich prawdziwej wartości. Te dodatkowe warstwy wyboru i losowości tworzą więcej „osłony” dla jednostek, jednocześnie pozwalając statystykom rozplątać ogólny wzorzec.
Pomiary prywatności i precyzji
Ponieważ większe zaciemnienie może chronić ludzi, ale też rozmywać dane, kluczowe pytanie brzmi, jak ocenić kompromis między prywatnością a precyzją. Autorzy porównują swoje cztery modele z siedmioma dobrze znanymi wcześniejszymi metodami, używając kilku miar. Przyglądają się efektywności statystycznej, która odzwierciedla, jak zmienna jest końcowa estymacja, oraz miernikom prywatności, które pokazują, jak bardzo zgłaszane wartości odbiegają od prawdziwej liczby osoby. Używają też składanego wyniku — zwanego miarą phi — który pozwala analitykowi określić, jak dużą wagę nadać prywatności w stosunku do efektywności. W szerokim zakresie ustawień nowe modele, szczególnie M1 i M4, osiągają konsekwentnie lepsze wyniki łączone niż starsze metody.
Wybór właściwego narzędzia do wrażliwego tematu
Badanie nie twierdzi, że jeden model jest najlepszy we wszystkich sytuacjach. Zamiast tego oferuje jasne wskazówki, kiedy stosować każde podejście. Gdy ochrona prywatności jednostki jest najwyższym priorytetem i badacze są gotowi zaakceptować nieco większy szum statystyczny, zalecane są modele M1–M3. Zapewniają one mocne gwarancje, że prawdziwej odpowiedzi pojedynczej osoby nie da się łatwo odgadnąć. Gdy organizatorom badań zależy bardziej na wyciśnięciu jak największej dokładności z ograniczonych danych — na przykład w małych lub kosztownych badaniach — model M4 zwykle wypada najlepiej. Ogólnie rzecz biorąc, przesłanie dla osób niebędących specjalistami jest uspokajające: poprzez staranne zaprojektowanie reguł losowania w ankiecie można zadawać bardzo wrażliwe pytania liczbowe w sposób zarówno etycznie bezpieczniejszy dla uczestników, jak i naukowo bardziej wiarygodny.
Cytowanie: Iqbal, S., Hussain, Z. & Omer, T. Some new quantitative randomized response models using optional and partial scrambling for sensitive data. Sci Rep 16, 7734 (2026). https://doi.org/10.1038/s41598-026-40714-0
Słowa kluczowe: badania z zachowaniem prywatności, odpowiedź losowa, dane wrażliwe, metodologia badań, statystyczna poufność