Clear Sky Science · pl
Model oparty na grupowaniu i regresji oraz analiza wydajności do wczesnego przewidywania chorób serca
Dlaczego wczesne wykrycie problemów z sercem ma znaczenie
Choroby serca często rozwijają się cicho przez wiele lat, a gdy pojawiają się oczywiste objawy, uszkodzenia mogą być już dokonane. W tym badaniu analizuje się, jak codzienne czujniki noszone na ciele i inteligentna analiza danych mogą współdziałać, aby wcześniej wykrywać sygnały ostrzegawcze, dając lekarzom i pacjentom więcej czasu na działanie. Poprzez połączenie dwóch różnych sposobów analizowania danych zdrowotnych autorzy dążą do zwiększenia trafności prognoz bez komplikowania technologii w rzeczywistych warunkach klinicznych.
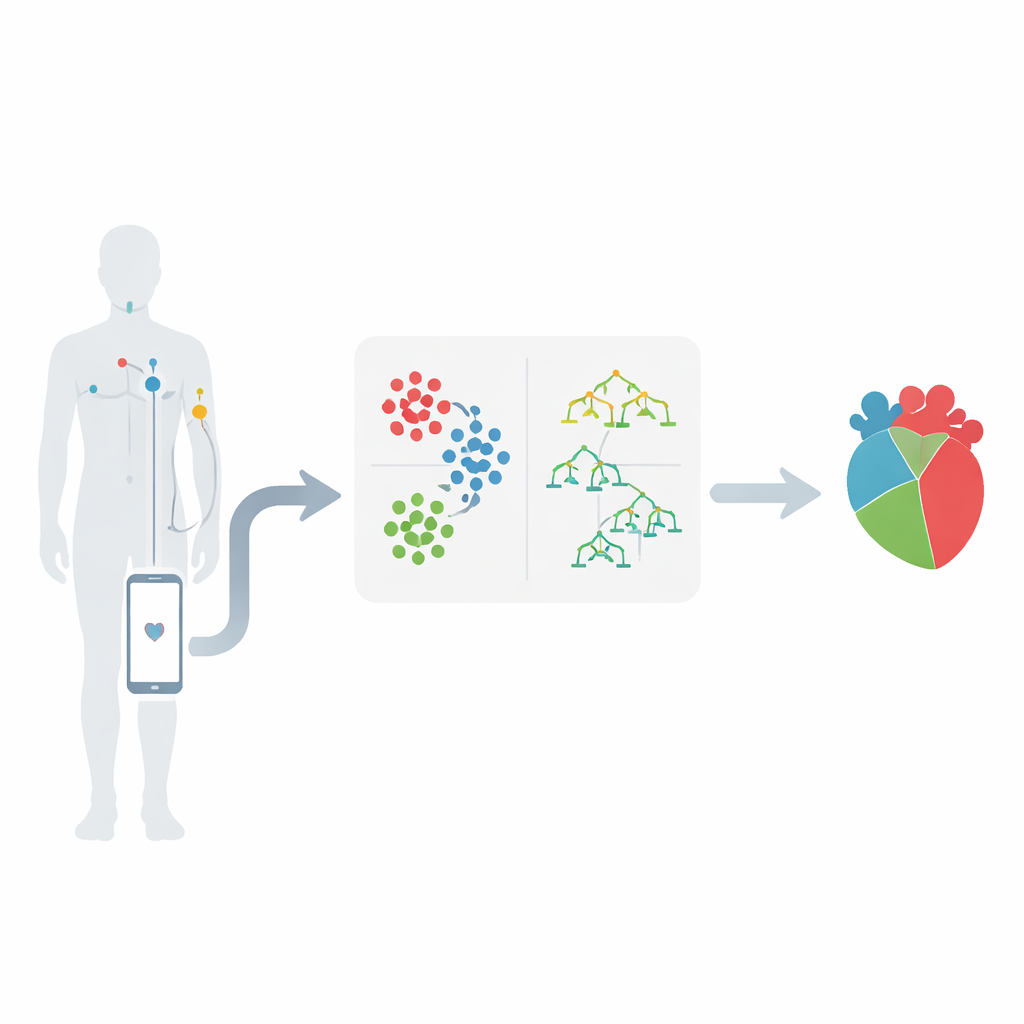
Od czujników na ciele do inteligentnych alertów
Praca osadzona jest w kontekście bezprzewodowych sieci czujników na ciele, gdzie małe sensory umieszczone na skórze rejestrują sygnały takie jak częstość akcji serca, ciśnienie krwi czy aktywność elektryczna serca. Czujniki przesyłają pomiary do urządzenia mobilnego, które przekazuje je do ośrodka medycznego w celu analizy. Kluczową ideą jest to, że strumienie tych liczb mogą ujawnić wzorce sugerujące rozwijające się problemy kardiologiczne na długo przed kryzysem. Autorzy skupiają się na znanym zbiorze danych dotyczących chorób serca, wybierając 12 istotnych cech, w tym rodzaj bólu w klatce piersiowej, ciśnienie krwi, cholesterol, poziom cukru we krwi, ból w klatce wywołany wysiłkiem oraz zmiany widoczne w elektrokardiogramie.
Odnajdywanie ukrytych grup w danych pacjentów
Zamiast wprowadzać wszystkie zapisy pacjentów bezpośrednio do jednej formuły predykcyjnej, zespół najpierw grupuje podobnych pacjentów. Używają metody zwanej K-means, która sortuje osoby w klastry na podstawie podobieństwa ich pomiarów, z wiekiem odgrywającym centralną rolę. Na przykład pacjenci mogą naturalnie tworzyć grupy z bardzo wysokim ciśnieniem krwi, wysokim poziomem cholesterolu lub określonymi wzorcami w badaniach serca. Ten etap grupowania pomaga uwypuklić, które kombinacje pomiarów są szczególnie niepokojące. Ukazuje też, że pewne zakresy — takie jak ciśnienie powyżej 150, cholesterol powyżej 300 czy określone zmiany w zapisie serca — mają tendencję do wiązania się ze znacznie wyższym ryzykiem.
Uczenie maszyn, by oceniać ryzyko
Po pogrupowaniu danych badacze stosują kilka metod uczenia maszynowego, które uczą się na podstawie przypadków historycznych, aby przewidzieć, czy nowy pacjent prawdopodobnie ma istotną chorobę serca. Porównują różne podejścia, w tym drzewa decyzyjne, k–najbliższych sąsiadów, maszyny wektorów nośnych, regresję logistyczną, Naiwny Bayes oraz lasy losowe. W ich hybrydowym rozwiązaniu każdy nowy pacjent zostaje najpierw przypisany do najbliższego klastra; następnie model lasu losowego wytrenowany specjalnie dla tego typu pacjentów dokonuje końcowej prognozy ryzyka. Dane są starannie oczyszczane, skalowane i dzielone na zbiory treningowe oraz testowe, a nierównowaga klas (więcej zdrowych niż chorych pacjentów) jest uwzględniana, aby modele nie uprzywilejowywały grupy większościowej.
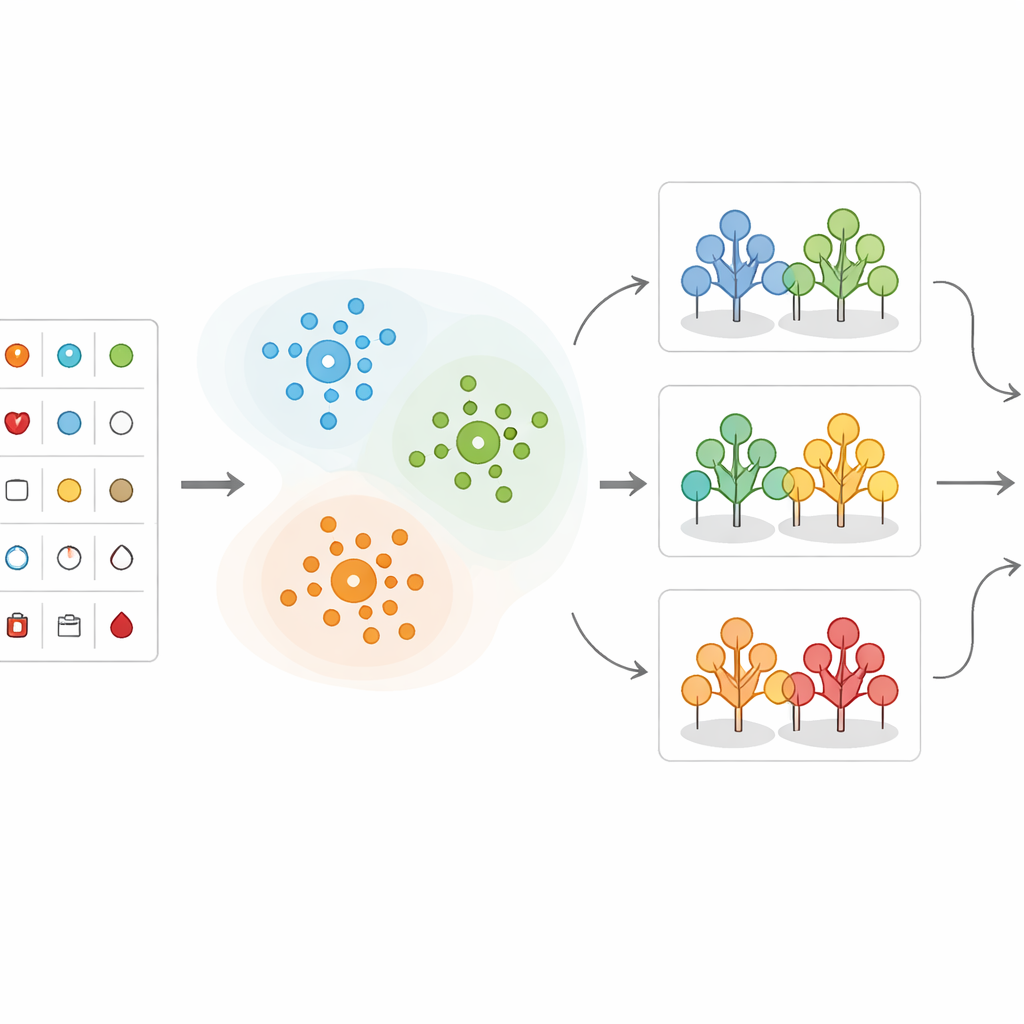
Jak sprawdza się model hybrydowy
Aby ocenić skuteczność, badanie bierze pod uwagę nie tylko ogólną dokładność, lecz także to, jak często model prawidłowo wykrywa chorych pacjentów (czułość), prawidłowo uspokaja zdrowych (swoistość) oraz jak balansuje obie cele (miara F1 i ROC–AUC). Wcześniejsze prace oparte na podobnych danych często osiągały około 85% dokładności i miały trudności z poprawą tych bardziej wyrafinowanych miar. Tutaj podejście łączące grupowanie i las losowy osiąga około 91% dokładności, z silną czułością i bardzo wysoką swoistością. Przedziały ufności dla tego modelu nie pokrywają się z przedziałami prostszych metod, co sugeruje, że poprawa jest mało prawdopodobna do przypisania przypadkowi. Jednocześnie czas obliczeń pozostaje w praktycznym zakresie — od milisekund do sekund — odpowiednim dla systemów monitorowania w czasie rzeczywistym lub bliskim rzeczywistemu.
Co to oznacza dla pacjentów i lekarzy
Mówiąc prościej, badanie pokazuje, że pozwolenie komputerom najpierw na pogrupowanie pacjentów w sensowne kategorie, a następnie zastosowanie dostosowanych reguł predykcyjnych, może wyostrzyć wczesne wykrywanie chorób serca. Metoda jest szczególnie obiecująca dla systemów ciągłego monitoringu, gdzie noszalne czujniki dyskretnie zbierają dane w tle. Chociaż wyniki pochodzą z umiarkowanie dużego, ustrukturyzowanego zbioru danych, a nie pełnych zapisów klinicznych, i autorzy przestrzegają przed możliwymi uprzedzeniami, przekaz jest jasny: mądrzejsze wykorzystanie istniejących pomiarów może dać lekarzom bardziej wiarygodny system wczesnego ostrzegania. Przy dalszych badaniach i większych, bardziej różnorodnych zbiorach danych tego rodzaju hybrydowa analiza może pomóc przekształcić surowe odczyty z czujników w terminowe, spersonalizowane alerty, które zapobiegają zawałom i innym poważnym zdarzeniom, zanim one nastąpią.
Cytowanie: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Słowa kluczowe: predykcja chorób serca, noszalne czujniki zdrowotne, uczenie maszynowe, grupowanie danych medycznych, model lasu losowego