Clear Sky Science · pl
Dokładne kolizje cech w sieciach neuronowych
Kiedy różne obrazy oszukują inteligentną maszynę
Nowoczesne systemy sztucznej inteligencji potrafią rozpoznawać twarze, analizować skany medyczne i prowadzić samochody autonomiczne. Wiemy już, że można je zmylić drobnymi, starannie dobranymi zmianami obrazu. Ten artykuł pokazuje coś jeszcze bardziej zaskakującego: te same sieci mogą być ślepe na ogromne, oczywiste zmiany, traktując bardzo różne obrazy tak, jakby były takie same. Zrozumienie, jak i dlaczego tak się dzieje, jest kluczowe, jeśli chcemy ufać systemom AI.
Od drobnych poprawek do dużych ślepot
Głębokie sieci neuronowe napędzają dzisiejsze przełomy w wizji maszynowej, przetwarzaniu języka i wielu innych dziedzinach. Wcześniejsze badania nad przykładami adwersarialnymi ujawniły, że ledwie widoczna zmiana obrazu może skłonić sieć do błędnej klasyfikacji z wysokim prawdopodobieństwem. Nowsze prace wykazały przeciwne zjawisko: niektóre sieci prawie nie reagują na duże, oczywiste zmiany, wciąż generując niemal identyczne przewidywania. W takich przypadkach wyodrębnione wewnętrzne cechy dwóch bardzo różnych obrazów „kolidują”, czyli sieć reprezentuje je w prawie taki sam sposób. Niniejsze badanie idzie o krok dalej, dowodząc, że powszechne sieci nie tylko mają przybliżone kolizje, lecz mogą występować także dokładne kolizje cech, gdy dwa różne wejścia są mapowane na dokładnie te same wewnętrzne sygnały.
Jak kolizje powstają wewnątrz sieci
Aby wyjaśnić te kolizje, autorzy zaglądają pod maskę sieci neuronowych i skupiają się na macierzach wag — wytrenowanych liczbach łączących warstwy. Kolizja cech zachodzi, gdy dwa różne wejścia dają taki sam wynik na pewnej warstwie; gdy to nastąpi, wszystkie kolejne warstwy widzą to samo i nie są w stanie rozróżnić tych wejść. Matematycznie ma to miejsce, gdy różnica między dwoma wejściami leży w „przestrzeni zerowej” macierzy wag danej warstwy: kierunkach w przestrzeni wejściowej, które warstwa całkowicie ignoruje. Autorzy pokazują, że zawsze gdy macierz wag ma wartość własną równą zero lub mapuje z przestrzeni o wyższej wymiarowości do niższej, takie ignorowane kierunki muszą istnieć. Ponieważ większość rzeczywistych architektur, w tym popularne modele do klasyfikacji, segmentacji i detekcji obiektów, wykorzystuje wiele takich warstw, kolizje nie są rzadkimi przypadkami brzegowymi, lecz niemal nieuniknioną cechą tych sieci.
Nowy sposób konstruowania kolidujących wejść
Wykorzystując tę obserwację, artykuł przedstawia praktyczny przepis nazwany przeszukiwaniem przestrzeni zerowej. Zamiast polegać na metodzie prób i błędów czy trikach opartych na gradientach, metoda ta bezpośrednio używa przestrzeni zerowej pierwszej macierzy wag. Z dowolnego obrazu autorzy obliczają wektor ignorowany przez pierwszą warstwę, a następnie dodają do obrazu skalowaną wersję tego wektora. Ponieważ ten kierunek jest niewidoczny dla warstwy, wewnętrzne cechy sieci — i ostateczne przewidywanie — pozostają dokładnie takie same, nawet jeśli obraz dla ludzkiego obserwatora wygląda na mocno zniekształcony. Ta sama idea rozszerza się na warstwy splotowe i w zasadzie na późniejsze warstwy. Autorzy przeanalizowali wiele standardowych modeli i stwierdzili, że większość ma mnóstwo takich ignorowanych kierunków, co oznacza, że w ten sposób można wygenerować niezliczone kolidujące obrazy dla szerokiego zakresu zadań.
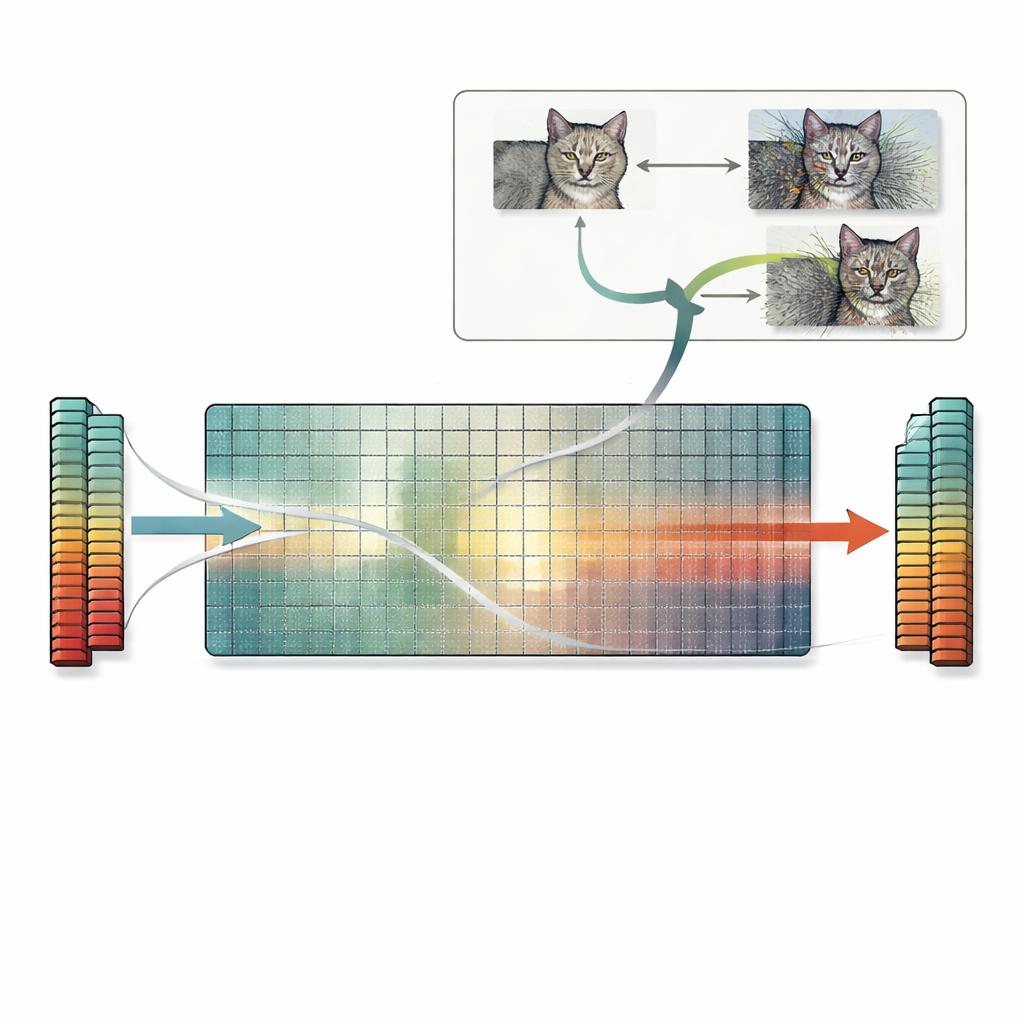
Ukryte ryzyka dla miar podobieństwa, wyjaśnień i bezpieczeństwa
Te dokładne kolizje cech niosą dalekosiężne konsekwencje. Dwa obrazy z kolidującymi cechami nie tylko będą miały takie samo przewidywanie, lecz często także identyczne mapy wyjaśnień generowane przez popularne narzędzia interpretowalności. To może sprawić, że nierozpoznawalny, silnie zniekształcony obraz będzie wydawał się równie dobrze uzasadniony jak czysty obraz, podważając zaufanie do metod wyjaśnień. Problem dotyczy również miar podobieństwa opartych na cechach z sieci neuronowych: takie metryki mogą uznać silnie zniszczony obraz za „identyczny” z oryginałem, ponieważ cechy zgadzają się dokładnie, choć proste wskaźniki pikselowe poprawnie wskazują duże różnice. Wreszcie, przeszukiwanie przestrzeni zerowej można połączyć ze standardowymi atakami adwersarialnymi, tworząc wiele różnych obrazów adwersarialnych, które wszystkie dają to samo błędne przewidywanie i mieszczą się w standardowych granicach zaburzeń, pogłębiając istniejące obawy o bezpieczeństwo.
Co to oznacza dla budowy bezpieczniejszej AI
Mówiąc prosto, praca pokazuje, że dzisiejsze sieci neuronowe często odrzucają informacje w przewidywalny sposób, pozostawiając całe kierunki w przestrzeni wejściowej, które w żaden sposób nie wpływają na ich decyzje. Atakujący mogą wykorzystywać te ślepe punkty do tworzenia dziwacznych lub adwersarialnych obrazów, które sieć traktuje jako identyczne z normalnymi. Autorzy sugerują użycie prostych liczników tych ignorowanych kierunków jako sposobu oceny, jak podatny może być model, i argumentują, że cieńsze, lepiej zregularizowane sieci z mniejszą przestrzenią zerową mogłyby być bardziej odporne. Choć w praktyce wciąż pozostaje wiele do przetestowania, przesłanie jest jasne: jeśli chcemy niezawodnej AI, musimy zwracać uwagę nie tylko na to, na co sieci reagują, lecz także na to, co ignorują.
Cytowanie: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Słowa kluczowe: sieci neuronowe, przykłady adwersarialne, kolizje cech, odporność modeli, przeszukiwanie przestrzeni zerowej