Clear Sky Science · pl
MedicalPatchNet: oparta na łatkach samowyjaśniająca się architektura AI do klasyfikacji zdjęć rentgenowskich klatki piersiowej
Dlaczego inteligentniejsze zdjęcia rentgenowskie mają znaczenie
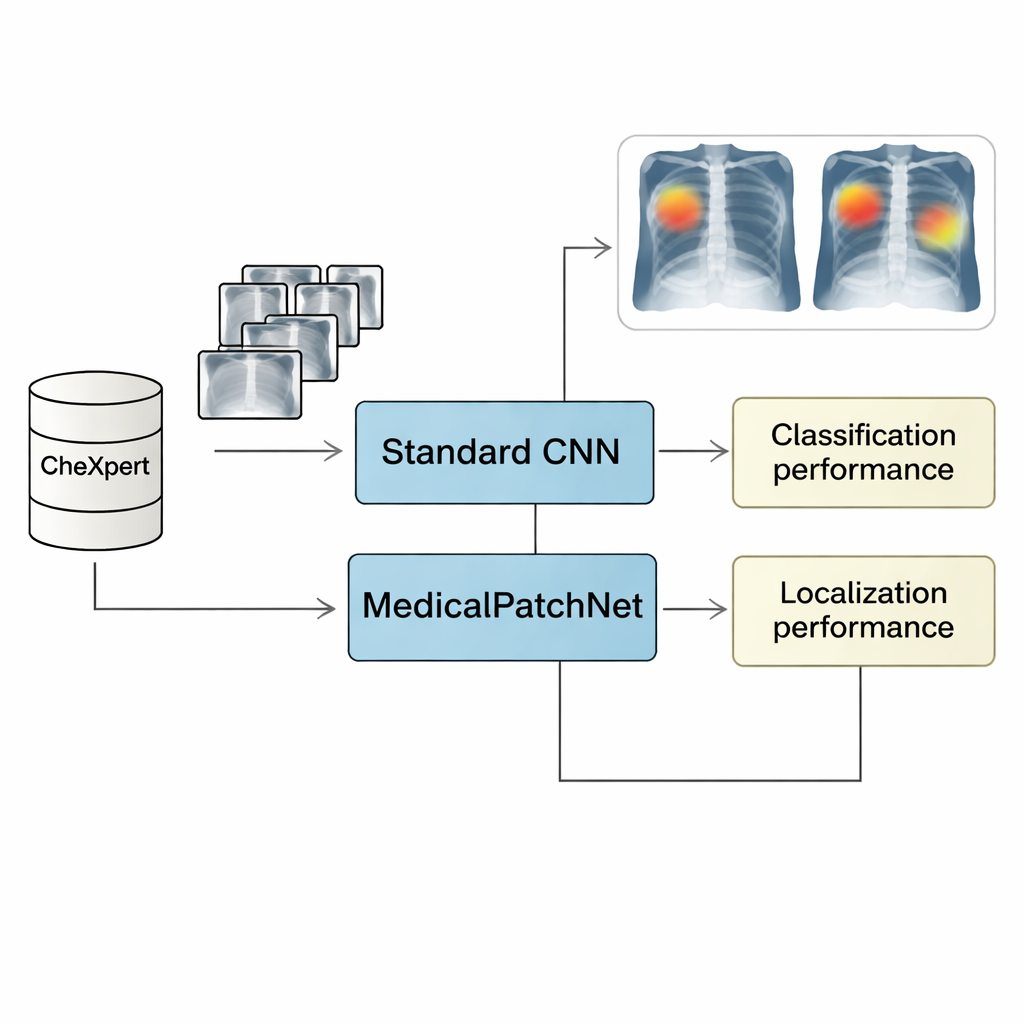
Zdjęcia rentgenowskie klatki piersiowej są jednym z najpowszechniejszych badań medycznych na świecie, a systemy sztucznej inteligencji (AI) coraz częściej pomagają lekarzom je interpretować. Jednak wiele z najlepszych dziś modeli działa jak „czarne skrzynki”: mogą być dokładne, lecz nawet eksperci nie potrafią łatwo sprawdzić, dlaczego podjęto konkretne rozpoznanie. Taki brak przejrzystości utrudnia klinicystom zaufanie i bezpieczne stosowanie AI w rzeczywistej opiece nad pacjentem. W badaniu przedstawiono MedicalPatchNet — nowe podejście AI, które ma na celu utrzymanie wysokiej dokładności przy jednoczesnym uczynieniu jej rozumowania widocznym i zrozumiałym, także dla osób bez wiedzy z zakresu uczenia maszynowego.
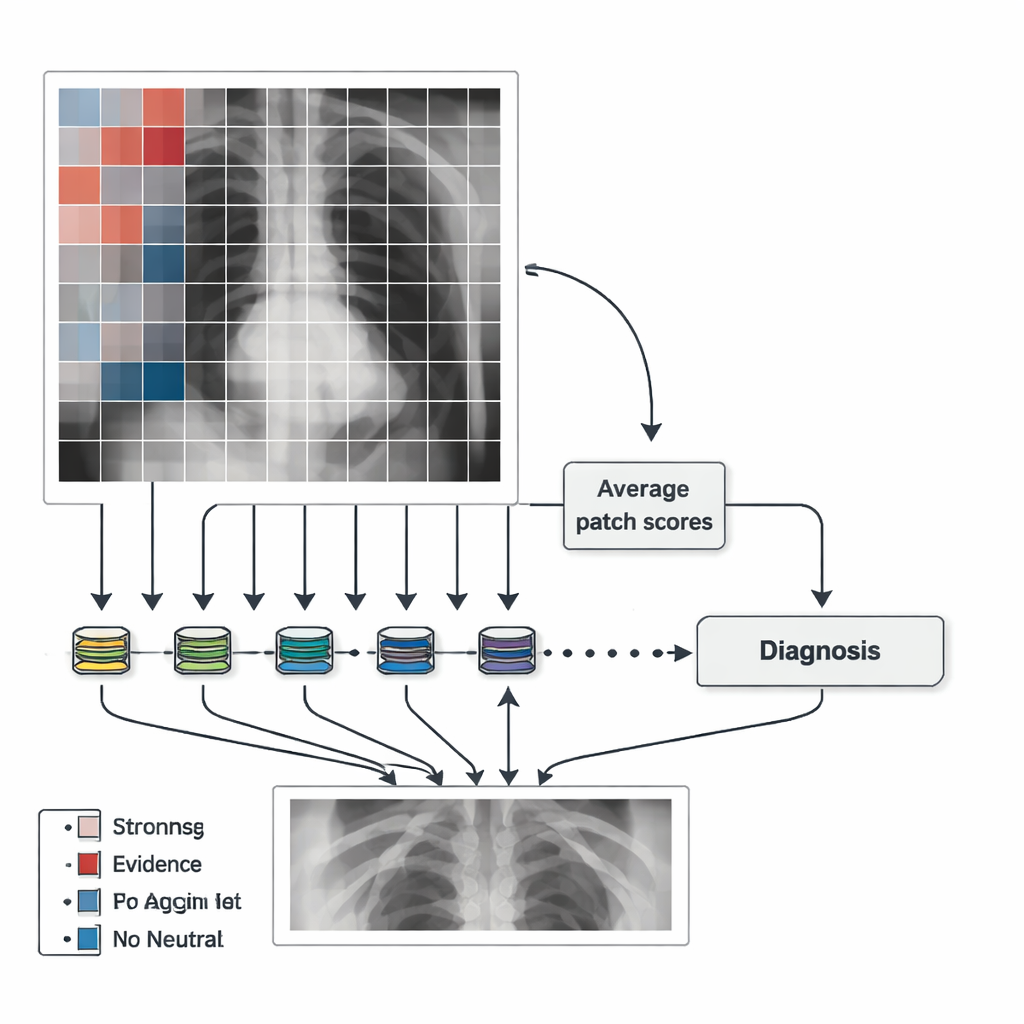
Dzielenie obrazów na małe, znaczące rejony
Zamiast analizować zdjęcie klatki piersiowej jako jedną dużą, tajemniczą całość, MedicalPatchNet działa, dzieląc obraz na wiele małych, niepokrywających się kwadratów, zwanych „łatkami”. Każda łatka jest przetwarzana przez tę samą sieć neuronową, która generuje wynik dla kilku możliwych ustaleń, takich jak obłokowatość płuc, zapalenie płuc czy wysięk opłucnowy (płyn wokół płuc). Wyniki na poziomie łatki są następnie uśredniane, aby uzyskać decyzję dotyczącą całego obrazu. Ponieważ końcowa odpowiedź jest po prostu sumą wielu lokalnych głosów, łatwo pokazać, jak bardzo każda łatka przyczyniła się do rozpoznania. Co istotne, brak tu ukrytych mechanizmów uwagi czy złożonych wewnętrznych wag — wpływ każdego regionu jest zdefiniowany jasno, zamiast być nauczonym w nieprzejrzysty sposób.
Przekształcanie decyzji modelu w czytelne mapy wizualne
Autorzy wykorzystują te wyniki łatkowe do tworzenia „map ważności”, które podkreślają, gdzie AI znalazła dowody na występowanie lub brak choroby. Łatki silnie wspierające rozpoznanie są pokazane ciepłymi kolorami (na przykład czerwonym), te przeciwdziałające mu — chłodnymi (np. niebieskim), a obszary neutralne — szarymi. Dzięki temu łatwo zobaczyć, czy model koncentruje się na płucach, sercu, czy niepokojąco na nieistotnych elementach, takich jak artefakty brzegowe czy etykiety tekstowe. Aby mapy były gładsze i mniej blokowe, zespół generuje też mapy po nieznacznym przesunięciu obrazu w wielu małych krokach i uśrednieniu wyników. To zwiększa koszty obliczeniowe, ale daje mapy cieplne lepiej odpowiadające anatomii, zachowując jednocześnie wyraźne powiązanie między każdym regionem a jego wkładem w końcową decyzję.
Osiąganie wydajności „czarnych skrzynek” przy poprawie zaufania
Aby przetestować MedicalPatchNet, badacze trenowali go na CheXpert, dużym publicznym zbiorze ponad 220 000 zdjęć rentgenowskich klatki piersiowej opisanych pod kątem 14 powszechnych ustaleń. Porównali jego wydajność z silnym, konwencjonalnym modelem analizującym obraz jako całość, używając tego samego szkieletu sieci (EfficientNetV2-S). Średnio oba modele osiągnęły niemal identyczną skuteczność diagnostyczną, mierzoną polem pod krzywą ROC (AUROC), czułością, specyficznością i trafnością. Innymi słowy, zmuszenie modelu do rozumowania łatka po łatce i następnie uśrednienia wyników nie osłabiło znacząco jego zdolności do rozpoznawania chorób. Sugeruje to, że dla wielu zadań dotyczących zdjęć rentgenowskich lokalna informacja obrazowa jest wystarczająca i nie ma potrzeby polegania na złożonych, w pełni globalnych wzorcach, aby dobrze działać.
Widzienie, gdzie model „patrzy” w poszukiwaniu choroby
Ponad ogólną dokładnością kluczowe pytanie brzmi: czy MedicalPatchNet wyjaśnia swoje decyzje bardziej wiarygodnie niż popularne narzędzia „po fakcie”, takie jak Grad-CAM i jego warianty. W tym celu zespół użył drugiego zbioru danych, CheXlocalize, który zawiera obrysy obszarów chorobowych narysowane przez radiologów. Mierzyli, jak często najbardziej podkreślony punkt metody znajdował się wewnątrz prawdziwego obszaru nieprawidłowości („wskaźnik trafień”) oraz jak dobrze podkreślony obszar pokrywał się z adnotacjami ekspertów (średni współczynnik Intersection over Union, mIoU). Mapy oparte na łatkach MedicalPatchNet uzyskały wyższe wskaźniki trafień niż wyjaśnienia w stylu Grad-CAM dla dziewięciu z dziesięciu warunków oraz najlepsze ogólne pokrycie przy liczeniu zarówno poprawnych, jak i błędnych predykcji. Szersza ocena jest ważna, ponieważ karze wyjaśnienia, które wyglądają dobrze tylko wtedy, gdy model ma rację, ale zawodzą w ukazywaniu mylących zachowań, gdy model się myli.
Od nieprzejrzystych domysłów do przejrzystych partnerów
Dla osób spoza specjalizacji główny wniosek jest taki, że MedicalPatchNet pokazuje, iż możliwe jest utrzymanie niemal stanu wiedzy w diagnostyce zdjęć rentgenowskich klatki piersiowej przy jednoczesnym uczynieniu rozumowania AI znacznie bardziej przejrzystym. Zamiast tajemniczych map cieplnych, które mogą, ale nie muszą odzwierciedlać rzeczywistych przyczyn decyzji, podejście to wiąże każde podkreślenie bezpośrednio z lokalnym głosem w obliczeniach modelu. Klinicyści mogą zobaczyć nie tylko to, czy AI uważa, że choroba występuje, lecz także dokładnie gdzie na obrazie znalazła dowody za lub przeciw. Choć metoda nadal ma ograniczenia — na przykład trudności w rozpoznawaniu stanów zależnych od analizy odległych regionów obrazu łącznie — oferuje praktyczną ścieżkę do narzędzi AI, które działają mniej jak czarne skrzynki, a bardziej jak przejrzyste, rozliczalne partnerzy w obrazowaniu medycznym.
Cytowanie: Wienholt, P., Kuhl, C., Kather, J.N. et al. MedicalPatchNet: a patch-based self-explainable AI architecture for chest X-ray classification. Sci Rep 16, 7467 (2026). https://doi.org/10.1038/s41598-026-40358-0
Słowa kluczowe: AI do zdjęć rentgenowskich klatki piersiowej, wyjaśnialne uczenie głębokie, MedicalPatchNet, mapy ważności obrazów medycznych, wspomaganie decyzji w radiologii