Clear Sky Science · pl
Metoda uczenia maszynowego oparta na kNN do automatyzacji oceny przyczynowości działań niepożądanych
Dlaczego to ma znaczenie dla osób przyjmujących leki
Kiedy nowy lek trafia na rynek, jego historia dopiero się zaczyna. Miliony ludzi będą go stosować w warunkach rzeczywistych i niektórzy doświadczą problemów zdrowotnych, które mogą, ale nie muszą być związane z lekiem. Rozróżnienie, które reakcje są naprawdę spowodowane przez lek, jest kluczowe dla bezpieczeństwa pacjentów, jednak dzisiaj ta praca jest powolna, złożona i w dużej mierze ręczna. To badanie analizuje, jak prosta, lecz skuteczna forma sztucznej inteligencji może pomóc ekspertom szybciej i bardziej konsekwentnie przeglądać raporty bezpieczeństwa, nie zastępując ludzkiego osądu, który ostatecznie chroni pacjentów.
Jak historie bezpieczeństwa stają się danymi
Firmy farmaceutyczne i organy regulacyjne opierają się na indywidualnych raportach bezpieczeństwa przypadków, które są uporządkowanymi streszczeniami doświadczeń prawdziwych osób z lekami. Każdy raport może zawierać, co poszło nie tak (na przykład ból głowy lub problem z wątrobą), jak poważny był ten incydent, jakie inne leki i choroby występowały oraz co pierwotny recenzent sądził o związku z lekiem. Dla ponad 800 000 takich raportów dotyczących sześciu leków w obrocie, medyczni recenzenci firmy już ustalili, czy każde działanie niepożądane było związane z lekiem, niezwiązane, czy niemożliwe do oceny z powodu brakujących lub sprzecznych informacji. Badacze wykorzystali ten bogaty historyczny zbiór jako materiał szkoleniowy dla modelu komputerowego, który miał się nauczyć naśladować te ludzkie decyzje w nowych przypadkach.

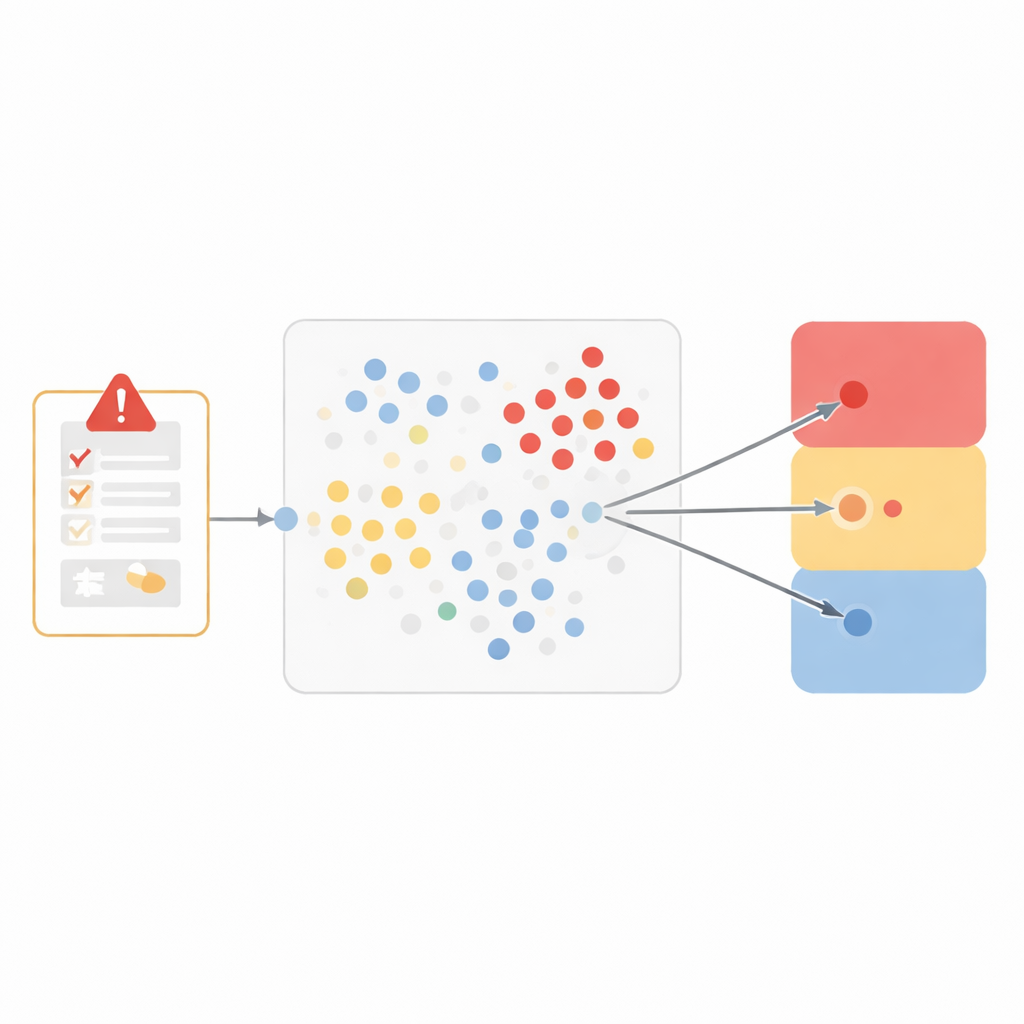
Nauczenie komputera rozpoznawania podobnych przypadków
Zamiast budować system typu „czarna skrzynka”, zespół wybrał szczególnie przejrzystą metodę zwaną „najbliższymi sąsiadami”. Pomysł jest intuicyjny: jeśli dwa przypadki wyglądają bardzo podobnie, prawdopodobnie będą miały tę samą konkluzję dotyczącą tego, czy lek spowodował problem. Aby uchwycić podobieństwo, badacze przedstawili każde działanie niepożądane jako siedmioelementowy profil, obejmujący medyczny termin opisu zdarzenia, co się stało po odstawieniu i ponownym włączeniu leku, czy problem był spodziewany dla tego leku, opinię zgłaszającego, inne przyjmowane leki, historię medyczną oraz jak poważne było zdarzenie. Następnie mierzyli, jak bliskie są dwa przypadki w tej siedmiowymiarowej przestrzeni, przypisując większą wagę cechom, które mają największe znaczenie dla przyczynowości, takim jak dokładny opis zdarzenia i to, co się stało po zmianie leczenia.
Z bliskości do trójstronnej decyzji
Kiedy napływa nowy raport, model przeszukuje dane historyczne, aby znaleźć dziesięć najbardziej podobnych przypadków. Sprawdza, jak ci sąsiedzi zostali sklasyfikowani, i pozwala im „głosować” wśród trzech szerokich wyników: prawdopodobnie związane z lekiem, niezwiązane lub mało prawdopodobne oraz nie do oceny. To trójdzielne rozgraniczenie osiąga równowagę między niuansami klinicznymi a niezawodnością działania. Przetestowany na ponad 250 000 wcześniej niewidzianych zdarzeń model w dużym stopniu odpowiadał ocenom ludzkich recenzentów dla zdarzeń uznanych za związane oraz dla tych ocenionych jako nie do oceny, osiągając niskie wskaźniki błędów i silne miary łączące trafność i kompletność. Miał większe trudności z mniejszą grupą wyraźnie niezwiązanych przypadków, co odzwierciedla wyzwanie, przed którym stoją systemy uczenia maszynowego, gdy pewien typ przykładów jest stosunkowo rzadki.
Zmniejszanie mgły „nie da się stwierdzić”
Jednym z praktycznych problemów w pracy nad bezpieczeństwem w warunkach rzeczywistych jest to, że etykieta „nie do oceny” może stać się workiem, do którego trafiają przypadki przy ubogiej lub niejednoznacznej informacji, co utrudnia dostrzeżenie prawdziwych wzorców bezpieczeństwa. Badacze dodali narzędzie strojenia, które sprawia, że model jest bardziej ostrożny przy przypisywaniu tej etykiety. Zamiast wybierać „nie do oceny” za każdym razem, gdy wygra prosta większość wśród podobnych przypadków, model teraz wymaga wyższego odsetka sąsiadów popierających tę decyzję. Podniesienie tego progu pozwoliło zespołowi znacznie zmniejszyć częstotliwość przypisywania etykiety „nie do oceny” i poprawić wyniki dla pozostałych dwóch kategorii, kosztem zwiększenia niezgodności w najtrudniejszych do oceny przypadkach. Panel sterowania dostępny przez przeglądarkę pozwala medycznym recenzentom dostosować ten próg dla konkretnego produktu, natychmiast zobaczyć, jak zmienia się rozkład wyników, i skoncentrować uwagę na przypadkach, w których model i ludzie się nie zgadzają.
Co to oznacza dla przyszłości bezpieczeństwa leków
Dla próbki niedawnych przypadków, które recenzenci-ludzie oznaczyli jako nie do oceny, system wyróżnił setki, w których jego wniosek się różnił. Gdy starsi recenzenci ponownie przeanalizowali te przypadki, zgodzili się z modelem w ponad dwóch trzecich przypadków, co pokazuje, że takie narzędzia mogą wskazywać przeoczone wzorce i wspierać nadzór jakości, zamiast zastępować ekspertów. Praca dowodzi, że jasne, oparte na podobieństwie podejście może wprowadzić sztuczną inteligencję do bezpieczeństwa leków w sposób wytłumaczalny, regulowany i zgodny z praktyką medyczną. W miarę gromadzenia większej ilości danych i dodawania narracji tekstowych przy użyciu nowoczesnych technologii językowych, systemy tego typu mogłyby pomóc we wcześniejszym wykrywaniu pojawiających się ryzyk, przy jednoczesnym zachowaniu ostatecznej decyzji w rękach klinicystów.
Cytowanie: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Słowa kluczowe: farmakovigiliancja, działania niepożądane leków, ocena przyczynowości, uczenie maszynowe, k najbliższych sąsiadów