Clear Sky Science · pl
Strategie uczenia maszynowego typu ensemble do mapowania perspektyw mineralnych przy niedoborze danych
Znajdowanie rudy przy mniejszej liczbie wskazówek
Współczesne społeczeństwo zależy od metali takich jak ołów i cynk wykorzystywanych w bateriach, elektronice i infrastrukturze, jednak najłatwiejsze złoża zostały już odkryte. W nowych regionach geolodzy często dysponują zaledwie kilkoma potwierdzonymi odkryciami, rozrzuconymi próbkami chemicznymi i niekompletnymi mapami. Badanie to pokazuje, jak stosować uczenie maszynowe nie po to, by osiągnąć najwyższy wynik na danych historycznych, lecz by dostarczać prognozy, którym decydenci rzeczywiście mogą zaufać, gdy informacji jest niewiele.
Dlaczego dane są skąpe w rzeczywistym świecie
Mapowanie perspektyw mineralnych ma na celu wskazanie obszarów krajobrazu, które mają większe prawdopodobieństwo zawierać rudy. Łączy warstwy informacji, takie jak typy skał, uskoki, zdjęcia satelitarne i chemia osadów rzecznych, w mapę prawdopodobieństwa, która kieruje pracami terenowymi i odwiertami. W projektach we wczesnej fazie jednak znane są jedynie nieliczne złoża, a wiele części mapy nigdy nie było badanych. Standardowe narzędzia uczenia maszynowego dobrze działają na dużych, dobrze oznaczonych zbiorach danych; mając do dyspozycji tylko kilkadziesiąt przykładów pozytywnych, stają się niestabilne i nadmiernie pewne siebie, podając liczby, które wyglądają na precyzyjne, lecz są słabo powiązane z rzeczywistością.
Przekształcanie rzadkich wskazówek w użyteczne sygnały
Autorzy pracowali w rejonie ołowiowo‑cynkowym Dehaq w środkowym Iranie, gdzie mineralizacja wiąże się z konkretnymi warstwami wapieni, uskokami i pasmami alteracji chemicznej. Zbudowali cyfrowe mapy skał macierzystych, gęstości spękań i alteracji na podstawie badań geologicznych i zdjęć satelitarnych oraz wydobyli anomalie geochemiczne z 624 próbek osadów. Z tego bogatego, lecz nierównomiernego materiału wyizolowali zaledwie 108 oznakowanych lokalizacji: 27 z potwierdzonymi złożami i 81 bez. Aby zapobiec zdominowaniu przez większość klasę negatywną nielicznych przykładów rudy, zastosowali technikę tworzenia realistycznych syntetycznych punktów złożowych przez interpolację między istniejącymi, wyrównując klasy jedynie w danych treningowych. Zapewniło to bardziej zrównoważony zbiór przykładów przy zachowaniu oddzielonych zestawów walidacyjnych i testowych odzwierciedlających rzeczywiste rzadkości. 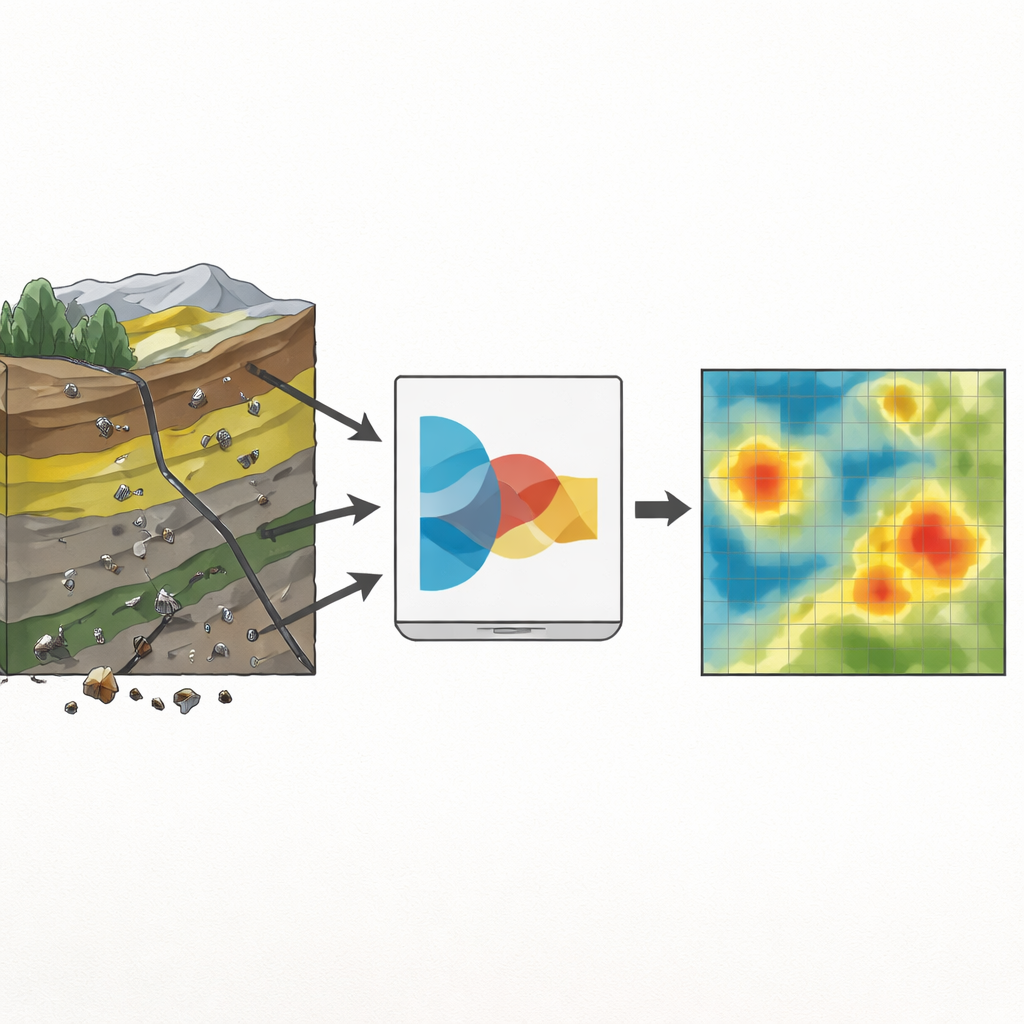
Budowanie zespołów modeli zamiast jednego bohatera
Zamiast polegać na jednym algorytmie, badanie łączyło metody o różnych mocnych stronach. Jeden ensemble parował maszynę wektorów nośnych (SVM), która wyznacza możliwie najostrzejszą granicę między klasami, z prostym modelem probabilistycznym zwanym Gaussian Naive Bayes. Drugi łączył dwie metody oparte na drzewach — LightGBM i AdaBoost — które świetnie wychwytują złożone wzorce w wielu zmiennych. W obu przypadkach końcowa prognoza była średnią estymowanych prawdopodobieństw przez modele składowe, strategią często redukującą gwałtowne wahania wydajności. Co istotne, autorzy porównywali nie tylko, jak często modele miały rację, ale też jak dobrze ich przewidywane prawdopodobieństwa zgadzały się z rzeczywistością — właściwość znaną jako kalibracja.
Strojenie pod kątem zaufania, nie tylko wyniku
Wybór ustawień modelu — jak silnie karze błędy, ile drzew generuje itp. — może dramatycznie zmienić jego zachowanie. Zespół przetestował trzy powszechne strategie strojenia: Grid Search, który systematycznie skanuje ustalony zestaw opcji; Random Search, który losowo próbuje kombinacji; oraz optymalizację bayesowską, która wykorzystuje wcześniejsze próby do wybierania obiecujących nowych konfiguracji. Na papierze optymalizacja bayesowska dała najwyższy pojedynczy wynik dyskryminacji (ROC–AUC 0,95) dla ensemble opartego na SVM. Jednak gdy autorzy przeanalizowali krzywe kalibracji, wersje uzyskane przez Grid Search obu ensemble’ów dały gładsze, bardziej stabilne wyniki, szczególnie w zakresie średnich prawdopodobieństw, gdzie zwykle ustawiane są progi eksploracji. 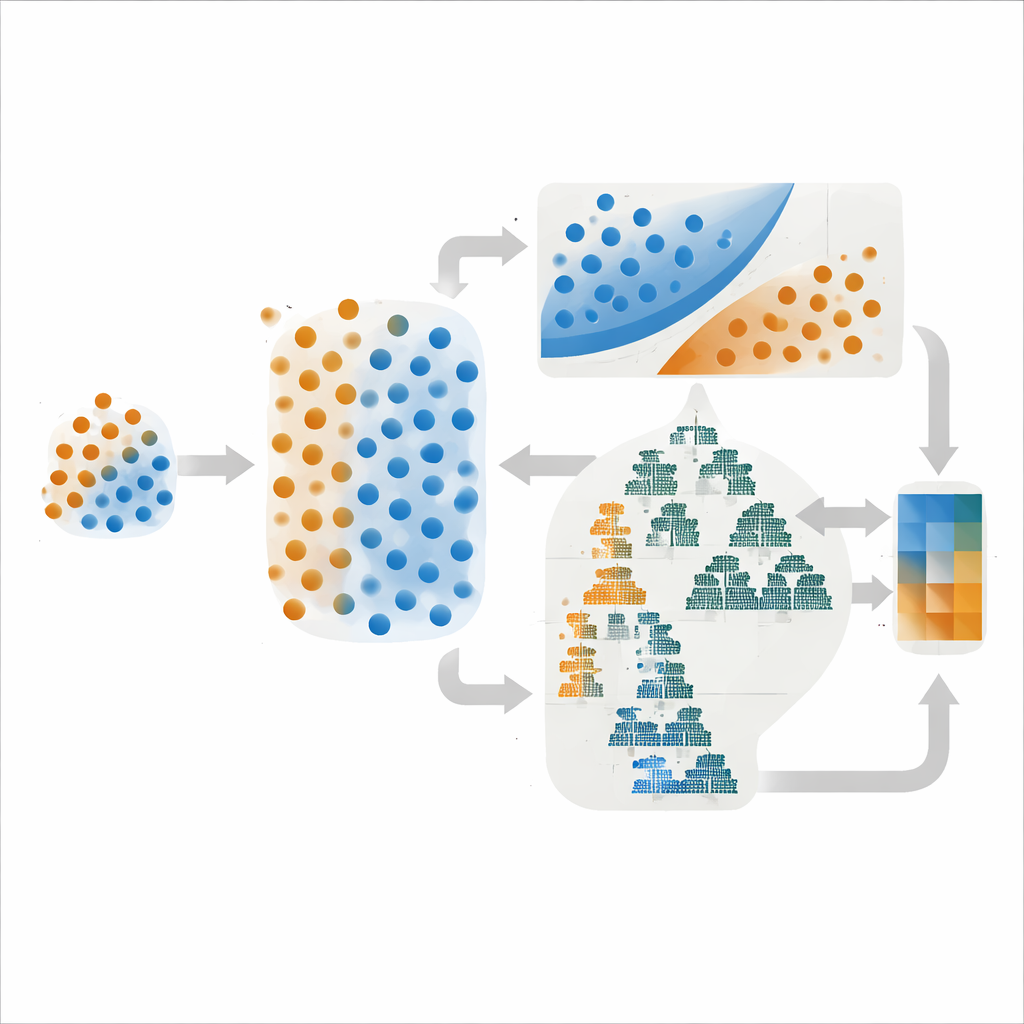
Od liczb do decyzji w terenie
W eksploracji początkowej, gdzie każdy odwiert jest kosztowny, autorzy argumentują, że dobrze zachowujące się prawdopodobieństwa mają większe znaczenie niż wyciskanie niewielkiego zysku w dokładności. Ich najpraktyczniejsza rekomendacja to prostszy ensemble SVM połączony z Bayesem, strojony przez Grid Search. Osiąga on silną dyskryminację przy jednoczesnym zapewnieniu najbardziej wiarygodnego związku między wartościami prawdopodobieństwa a rzeczywistymi wskaźnikami odkryć, co pozwala geologom ustalać progi zgodne z ich tolerancją ryzyka. W miarę dojrzewania projektów i gromadzenia większej ilości danych można wprowadzać bardziej złożone modele oparte na drzewach, takie jak ensemble LightGBM, by udoskonalać prognozy, ale zawsze z uwagą na kalibrację. W ten sposób uczenie maszynowe staje się nie generatorem wyników w czarnej skrzynce, lecz przejrzystym partnerem w podejmowaniu decyzji uwzględniających ryzyko, dotyczących poszukiwania następnej generacji zasobów mineralnych.
Cytowanie: Amirajlo, P., Hassani, H., Pour, A.B. et al. Ensemble machine learning strategies for mineral prospectivity mapping under data scarcity. Sci Rep 16, 9171 (2026). https://doi.org/10.1038/s41598-026-40125-1
Słowa kluczowe: mapowanie perspektyw mineralnych, uczenie maszynowe typu ensemble, niedobór danych, kalibracja modelu, poszukiwanie złóż mineralnych