Clear Sky Science · pl
KM-DBSCAN: ulepszona ramka wykrywania granic oparta na gęstości i centroidach do redukcji danych w kierunku zielonej AI
Dlaczego zmniejszanie AI może uczynić je bardziej ekologicznym
Sztuczna inteligencja ma ukryty koszt: energię elektryczną. Trenowanie nowoczesnych modeli uczenia maszynowego często oznacza przetwarzanie milionów punktów danych na energochłonnym sprzęcie, co z kolei powoduje emisję dwutlenku węgla. W artykule przedstawiono KM-DBSCAN — nowy sposób kurczenia zbiorów danych przed treningiem bez wyrzucania informacji istotnych dla modeli. Zachowując tylko najbardziej informacyjne dane, metoda przyspiesza uczenie, zmniejsza zużycie energii i nadal zapewnia dokładne prognozy w zadaniach od rozpoznawania odręcznych cyfr po wczesne wykrywanie raka skóry.
Za dużo danych, za dużo energii
Przez lata dominowało przekonanie, że więcej danych niemal zawsze prowadzi do lepszych modeli. Choć może to poprawić dokładność, wiąże się też z dłuższym czasem treningu, większymi komputerami i wyższymi rachunkami za prąd. Badacze zaczęli rozróżniać „Red AI”, która goni za dokładnością bez względu na koszty, oraz „Green AI”, która stara się równoważyć wydajność z wpływem na środowisko. Jednym z obiecujących kierunków w stronę bardziej ekologicznej AI jest redukcja danych: zamiast podawać modelowi każdy dostępny przykład, wybrać znacznie mniejszy zestaw przypadków, które nadal dobrze definiują problem, szczególnie trudne przypadki brzegowe decydujące o klasyfikatorze.
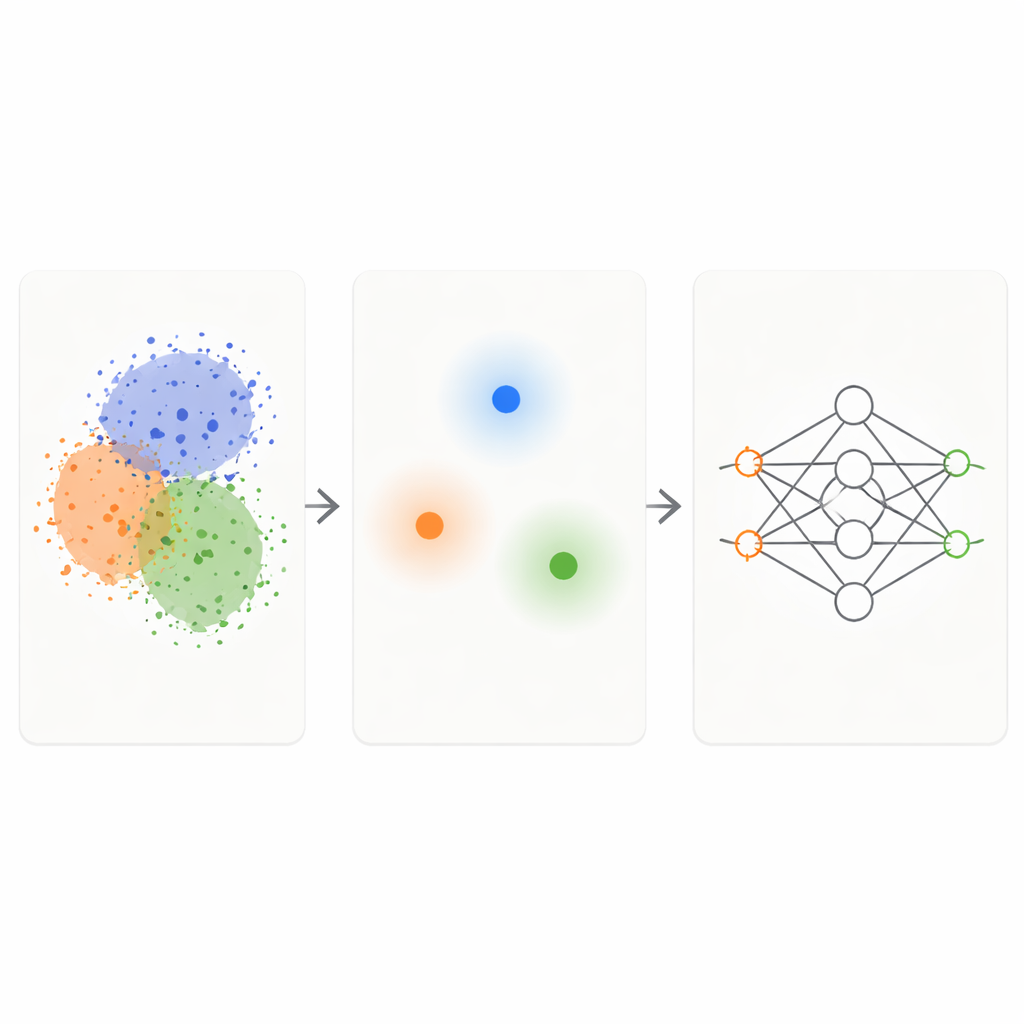
Połączenie dwóch prostych pomysłów w jeden inteligentny filtr
Ramka KM-DBSCAN łączy dwa dobrze znane podejścia grupowania, by działać jak inteligentny filtr na surowych danych. Najpierw szybka metoda K-Means grupuje punkty w zwarte klastry i zastępuje każdą grupę reprezentacyjnym środkiem, czyli centroidem. To redukuje problem z tysięcy lub milionów punktów do kilkuset reprezentantów. Następnie na tych centroidach uruchamiana jest metoda oparta na gęstości (DBSCAN), aby znaleźć obszary leżące na granicach między klastrami oraz gęste, jednorodne wnętrza albo izolowany szum. Pracując na poziomie centroidów, DBSCAN staje się znacznie szybszy i mniej czuły na drobne dobory parametrów niż przy stosowaniu go bezpośrednio do wszystkich punktów danych.

Zachowywanie tylko trudnych, informacyjnych przypadków
Gdy KM-DBSCAN zidentyfikuje, gdzie różne grupy stykają się lub nachodzą na siebie, zachowuje tylko punkty danych leżące blisko tych granic i odrzuca zarówno głębokie punkty wnętrza, jak i wyraźne odosobnione odstępstwa. Punkty wnętrza są w dużej mierze redundantne: wyglądają podobnie i przekazują modelowi tę samą informację o swojej klasie. Punkty graniczne natomiast mówią modelowi dokładnie, gdzie kończy się jedna klasa, a zaczyna druga. Na syntetycznych zestawach testowych ta strategia odtwarza te same granice decyzyjne, które klasyfikator uczy się z pełnych danych, nawet gdy większość punktów zostanie usunięta. W rzeczywistych zbiorach, takich jak Banana, USPS digits, zbiór danych o dochodach Adult, dane o kolizjach pojazdów, odmiany suchych fasoli oraz obrazy skóry z czerniakiem, zredukowane zbiory zachowują kluczową strukturę problemu, będąc przy tym o rząd wielkości mniejsze.
Szybkość, oszczędności emisji i rzeczywiste zastosowania
Autorzy przetestowali KM-DBSCAN jako warstwę wstępną dla kilku popularnych modeli, w tym maszyn wektorów nośnych (SVM), wielowarstwowych perceptronów i splotowych sieci neuronowych. W wielu przypadkach trening na zredukowanych danych był dziesiątki do tysięcy razy szybszy przy zachowaniu niemal tej samej dokładności — a czasem nawet jej lekkiej poprawie. Na przykład przy rozpoznawaniu odręcznych cyfr metoda zmniejszyła zbiór treningowy do zaledwie 1,4% pierwotnego rozmiaru i mimo to nieznacznie podniosła dokładność, przyspieszając trening 284 razy. W zadaniu prognozowania dochodów przy niezrównoważonych klasach osiągnięto przyspieszenie 6907 razy, używając tylko około 3% danych przy minimalnej utracie dokładności. W eksperymencie wykrywania czerniaka głęboka sieć neuronowa osiągnęła ponad 90% dokładności, trenując na mniej niż jednej trzeciej pierwotnego zbioru obrazów skóry, co wiązało się z redukcją emisji dwutlenku węgla o ponad 70%.
Co to oznacza dla codziennej AI
Dla osób niebędących specjalistami kluczowy komunikat jest taki: mądrzejszy wybór może pokonać samą objętość. KM-DBSCAN pokazuje, że uważne wybieranie przykładów widzianych przez model — koncentrując się na najbardziej informacyjnych przypadkach brzegowych — może drastycznie skrócić czas obliczeń i zużycie energii przy zachowaniu wiarygodnych predykcji. Podejście to wpisuje się w szerszy ruch na rzecz Green AI, gdzie jakość danych i przemyślany projekt procesów treningowych liczą się równie mocno co surowa wielkość modeli. Jeśli zostanie szeroko przyjęte, takie filtrowanie uwzględniające charakter danych mogłoby uczynić wszystko, od analizy obrazów medycznych po systemy bezpieczeństwa ruchu drogowego, bardziej zrównoważonymi, udostępniając potężne narzędzia AI organizacjom nieposiadającym ogromnych zasobów obliczeniowych.
Cytowanie: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Słowa kluczowe: zielona AI, redukcja danych, grupowanie, efektywność uczenia maszynowego, wykrywanie czerniaka