Clear Sky Science · pl
Wzmacnianie rzadkości sygnałów źródłowych w oparciu o algorytm lokalnej maksymalnej synchroekstrakcji do estymacji mieszanej macierzy w UBSS
Rozplątywanie ukrytych sygnałów
Wiele technologii, na których polegamy — sieci bezprzewodowe, radary, skanery medyczne, a nawet inteligentne mikrofony — musi wyłapywać słabe sygnały, które są beznadziejnie wymieszane. Wyobraźmy sobie próby śledzenia kilku rozmów jednocześnie w zatłoczonej kawiarni, mając tylko dwoje uszu. W artykule przedstawiono nową metodę „rozplątywania” nakładających się sygnałów, gdy liczba czujników jest mniejsza niż liczba źródeł, co jest wyjątkowo trudnym przypadkiem. Poprzez ostrzejsze spojrzenie na sygnały w dziedzinie czasu i częstotliwości oraz poprawę komputerowego grupowania powiązanych danych, autorzy pokazują, że można oddzielać mieszaniny dokładniej i bardziej niezawodnie, nawet w zaszumionych warunkach rzeczywistych. 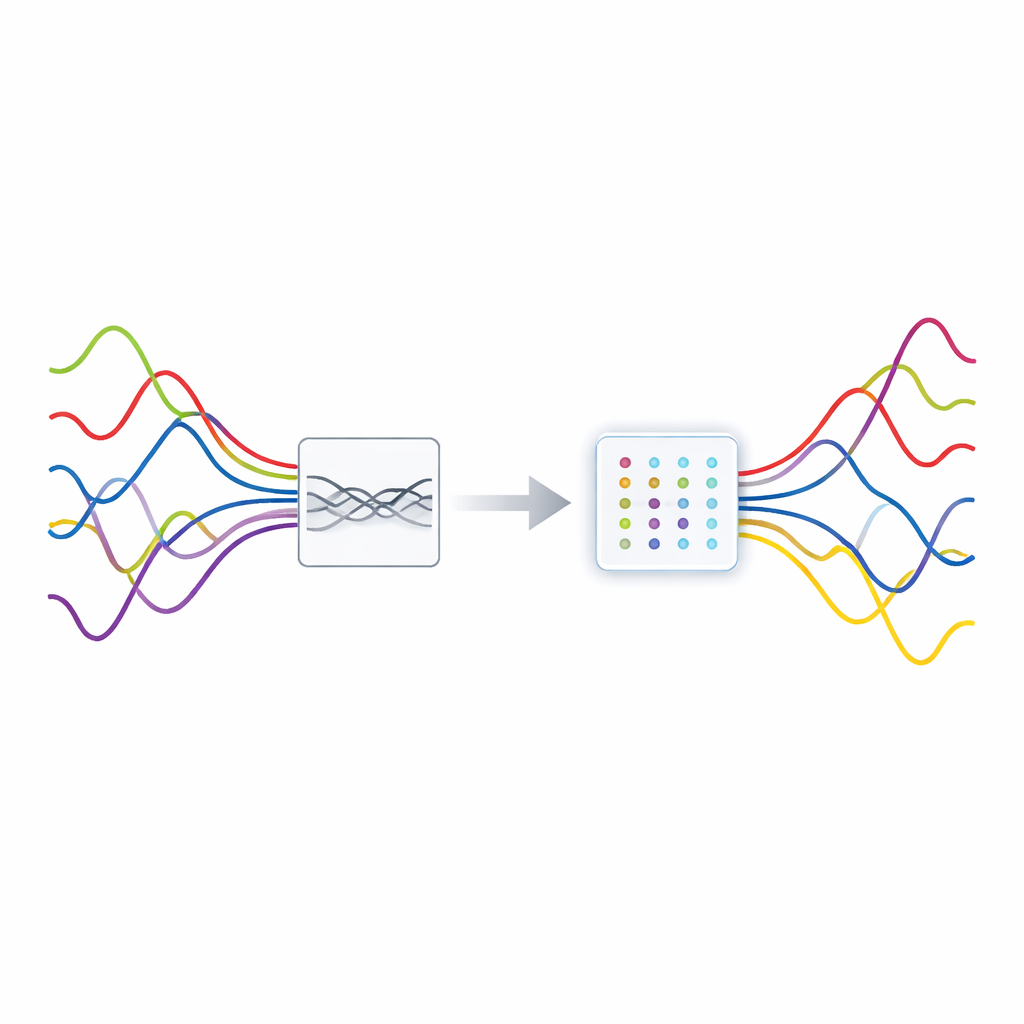
Dlaczego mieszane sygnały są tak trudne do rozdzielenia
W wielu systemach kilka niezależnych sygnałów przechodzi tym samym kanałem i jest odbieranych przez niewielką liczbę odbiorników. Ta sytuacja, zwana niedookreślonym ślepym rozdzielaniem źródeł (underdetermined blind source separation), oznacza, że jest więcej nieznanych źródeł niż pomiarów. Klasyczne metody rozdzielania sygnałów zazwyczaj zakładają odwrotną sytuację, dlatego zawodzą tutaj. Kluczową współczesną sztuczką jest wykorzystanie rzadkości: w odpowiedniej reprezentacji każde źródło jest aktywne tylko w kilku momentach lub w wąskich pasmach częstotliwości. Jeśli w większości chwil dominuje co najwyżej jedno źródło, chmura obserwowanych danych naturalnie tworzy klastry, których kierunki kodują, jak każde źródło zostało wymieszane w odbiornikach. Dokładne znalezienie tych klastrów zależy jednak od posiadania reprezentacji, w której energia każdego źródła jest ostro skoncentrowana, a nie rozmyta.
Wyostrzenie obrazu sygnału
Aby ujawnić rzadkość, inżynierowie często przekształcają sygnały do obrazu czas–częstotliwość pokazującego, jakie tony występują w jakich chwilach. Prosty krótkookresowy transformata Fouriera robi to przez przesuwanie okna w czasie i obliczanie wielu małych widm, ale rozmywa energię i nie daje jednocześnie ostrego oznaczenia czasu i precyzyjnego tonu. Bardziej zaawansowane warianty, takie jak synchrosqueezing i synchroextracting, próbują przesunąć rozciągniętą energię w kierunku grzbietu podążającego za chwilową częstotliwością sygnału. Te metody poprawiają ostrość, ale pozostają podatne na szum: gdy losowe zakłócenia są skompresowane wzdłuż tych samych grzbietów co sygnał, wynik może być jasnym, lecz rozmytym pasmem, które ukrywa drobną strukturę.
Znajdowanie lokalnych szczytów dla zwiększenia rzadkości
Wychodząc od tych idei, autorzy wprowadzają Lokalny Maksymalny Transform Synchroekstrakcyjny, czyli LMSET. Zamiast przesuwać całą pobliską energię w kierunku grzbietu częstotliwościowego, LMSET skanuje płaszczyznę czas–częstotliwość i dla każdej chwili skupia się na lokalnych szczytach wzdłuż osi częstotliwości. Zachowywane i przemapowywane są jedynie współczynniki wokół tych lokalnych maksimów, podczas gdy reszta jest tłumiona. Ta prosta zmiana daje reprezentację, w której energia każdego składowego sygnału koncentruje się w cienkich, czystych krzywych z znacznie mniejszą liczbą rozproszonych punktów. W symulacjach z sygnałami wieloskładnikowymi LMSET daje najniższą entropię Rényiego, standardową miarę koncentracji, przewyższając metody tradycyjne i nowoczesne w szerokim zakresie poziomów szumu. Mówiąc prościej: LMSET daje wyraźniejszy obraz tego, gdzie każdy sygnał występuje w czasie i częstotliwości.
Sprytniejsze grupowanie do odkrywania ukrytego mieszania
Bardziej ostry obraz to tylko połowa sukcesu; następnym krokiem jest zgrupowanie uzyskanych punktów, aby oszacować nieznaną macierz mieszania opisującą, jak każde źródło przyczynia się do sygnałów odbieranych przez każdy odbiornik. Wiele podejść opiera się na rozmytej metodzie C-średnich, popularnej metodzie klasteryzacji, która często utknie w złych rozwiązaniach, ponieważ jest bardzo wrażliwa na początkowe zgadywanie i na punkty odstające. Aby przezwyciężyć te słabości, autorzy łączą LMSET z nowym, bardziej odpornym schematem klasteryzacji. Najpierw używają algorytmu przeszukiwania opartego na PID, inspirowanego teorią sterowania, aby przeszukać pełną przestrzeń możliwych środków klastrów i uniknąć złych pozycji początkowych. Następnie wprowadzają mechanizm wag logicznych, by osłabić wpływ wartości odstających, oraz strategię opartą na entropii informacji, która zmniejsza wrażliwość na warunki początkowe. Razem te kroki pozwalają klasteryzacji bardziej konsekwentnie zlokalizować prawdziwe kierunki ukrytych źródeł.
Co ujawniają testy
Autorzy testują cały swój proces — LMSET wraz z ulepszoną klasteryzacją — na mieszankach cyfrowo modulowanych sygnałów komunikacyjnych, w tym QAM, QPSK i FSK, w warunkach cichych i zaszumionych. Porównują oszacowane macierze mieszania z rzeczywistymi, używając błędu kątowego i znormalizowanego błędu średniokwadratowego. We wszystkich przypadkach użycie LMSET zamiast tradycyjnego transformatu zmniejsza błędy, ponieważ punkty danych tworzą ciaśniejsze, bardziej wyraźne klastry. Spośród metod klasteryzacji proponowana, zoptymalizowana PID-em, odporna rozmyta metoda C-średnich osiąga najmniejsze średnie odchylenia kątowe i najlepsze wyniki błędów. W sumie połączona metoda poprawia dokładność estymacji macierzy mieszania o niemal 20 procent w porównaniu z konwencjonalnymi podejściami, zachowując silną wydajność nawet przy wysokich poziomach szumu. 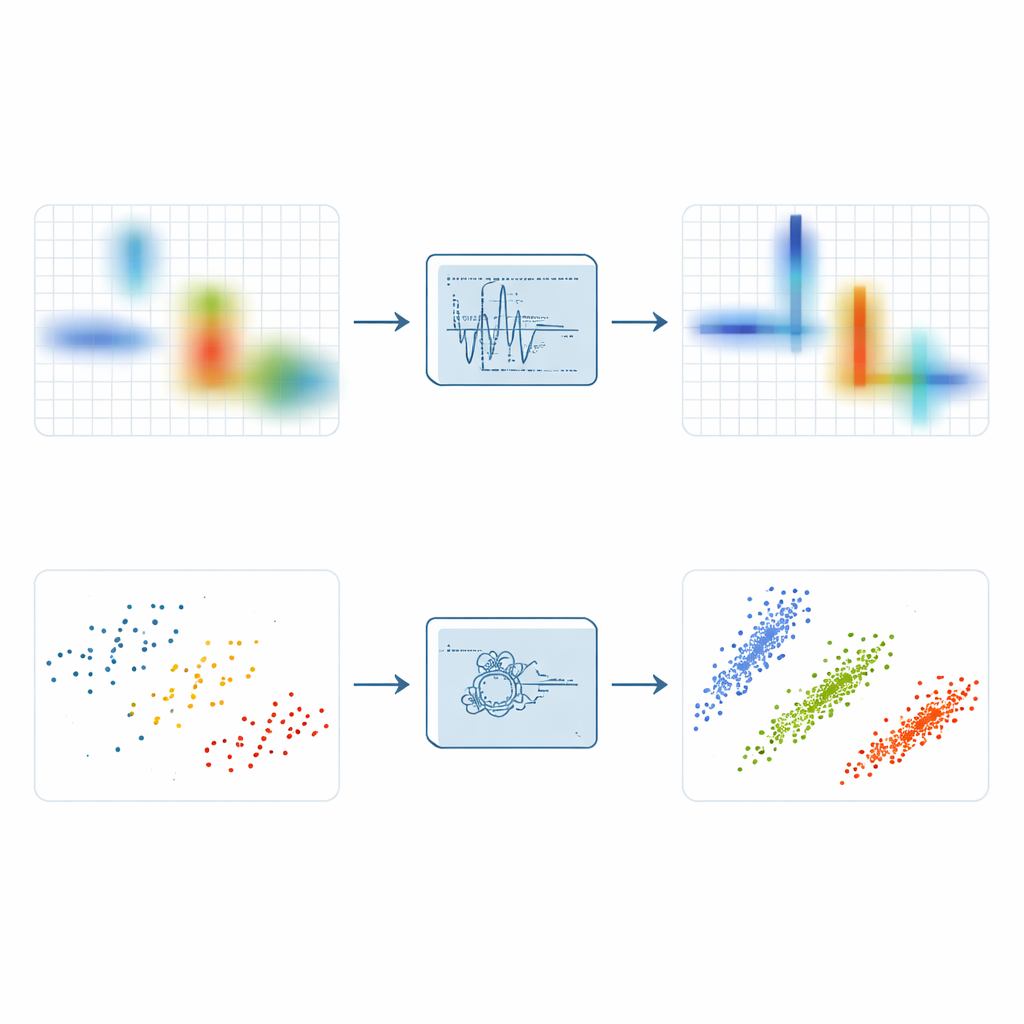
Dlaczego to ma znaczenie poza teorią
Dla czytelnika niezaznajomionego ze szczegółami technicznymi, kluczowy wniosek jest taki, że autorzy znaleźli lepszy sposób patrzenia na splątane sygnały i ich grupowania, tak aby każdy pierwotny strumień można było odtworzyć czyściej. Skupiając się na lokalnych szczytach w krajobrazie czas–częstotliwość i łącząc ten wgląd z ostrożniejszą strategią klasteryzacji, ich metoda sprawia, że pozornie niemożliwy problem kawiarni — wiele głosów, za mało uszu — staje się nieco bardziej rozwiązywalny. To osiągnięcie może przynieść korzyści w zastosowaniach od łączy satelitarnych, które muszą rozdzielać nakładające się transmisje, po systemy medyczne, które muszą izolować słabe sygnały biologiczne pogrzebane w szumie, oferując jaśniejsze informacje z tych samych ograniczonych pomiarów.
Cytowanie: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Słowa kluczowe: ślepe rozdzielanie źródeł, rzadkość sygnału, analiza czas–częstotliwość, algorytmy klasteryzacji, komunikacja bezprzewodowa