Clear Sky Science · pl
De novo generowanie i przesiew in silico kandydatów na peptydy przeciwcukrzycowe za pomocą frameworku głębokiego uczenia z mechanizmem attention i fuzją cech fizykochemicznych
Dlaczego inteligentniejsze projektowanie peptydów ma znaczenie w cukrzycy
Cukrzyca dotyka setek milionów ludzi na całym świecie, a dostępne leki nie działają idealnie u wszystkich. Wiele terapii traci skuteczność z czasem lub wywołuje działania niepożądane. Obiecującą nową opcją jest klasa małych białek nazywanych peptydami przeciwcukrzycowymi, które potrafią precyzyjnie regulować poziom cukru we krwi. Wyzwaniem jest to, że odkrywanie nowych leków peptydowych w laboratorium jest powolne i kosztowne. W tym badaniu przedstawiono komputerowy pipeline, który potrafi tworzyć i przesiać dużą liczbę potencjalnych peptydów przeciwcukrzycowych, wskazując badaczom najbardziej obiecujące kandydatury do testów w warunkach eksperymentalnych.
Od znanych peptydów związanych z cukrzycą do czystych danych wyjściowych
Badacze zaczęli od zebrania wysokiej jakości zbioru peptydów, które eksperymentalnie wykazano, że wpływają na poziom cukru we krwi, głównie poprzez oddziaływanie na hormony takie jak GLP-1 lub enzymy jak DPP-IV. Stanowiły one przykłady „pozytywne”. Następnie zbudowali dopasowany zbiór „negatywny” peptydów bez udokumentowanej aktywności przeciwcukrzycowej, starannie dobranych tak, by długość, skład i podstawowa chemia przypominały peptydy pozytywne. Aby uniknąć oszukania modelu przez niemal identyczne sekwencje, użyli narzędzi do analizy podobieństwa sekwencji, by upewnić się, że blisko spokrewnione peptydy nigdy nie pojawiają się jednocześnie w grupach treningowych i testowych. To rozdzielenie z uwzględnieniem homologii zapewniło, że system będzie oceniany pod kątem zdolności rozpoznawania rzeczywiście nowych wzorców, a nie zapamiętywania starych.
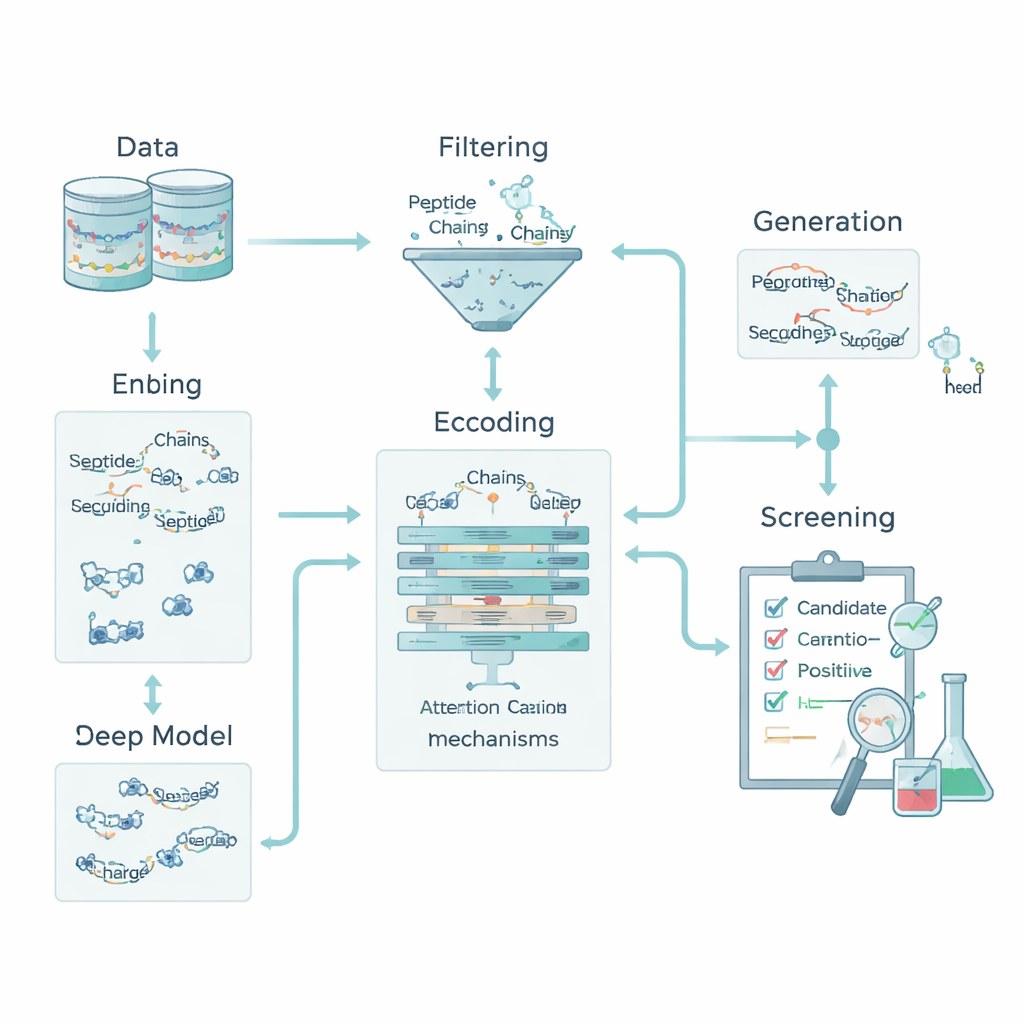
Kodowanie chemii, żeby maszyny mogły czytać peptydy
Dla komputera peptyd to po prostu ciąg liter reprezentujących aminokwasy. Aby połączyć te litery z biologią, zespół przekształcił każdy aminokwas w pięć podstawowych cech chemicznych: hydrofobowość (jak bardzo unika wody), ładunek elektryczny, skłonność do tworzenia wiązań wodorowych, masę oraz obecność pierścienia aromatycznego. To zamieniło każdy peptyd w mały „obraz”, który uchwycił zarówno kolejność, jak i chemię. Dodatkowo dodano deskryptory całego peptydu, takie jak całkowity ładunek, średnia hydrofobowość i indeks Bomana, związany ze skłonnością peptydu do wiązania innych białek. Razem te cechy pozwalają modelowi uwzględniać zarówno lokalne wzorce — krótkie motywy aminokwasów — jak i właściwości globalne wpływające na zachowanie peptydu w organizmie.
Silnik głębokiego uczenia, który wyjaśnia swoje wybory
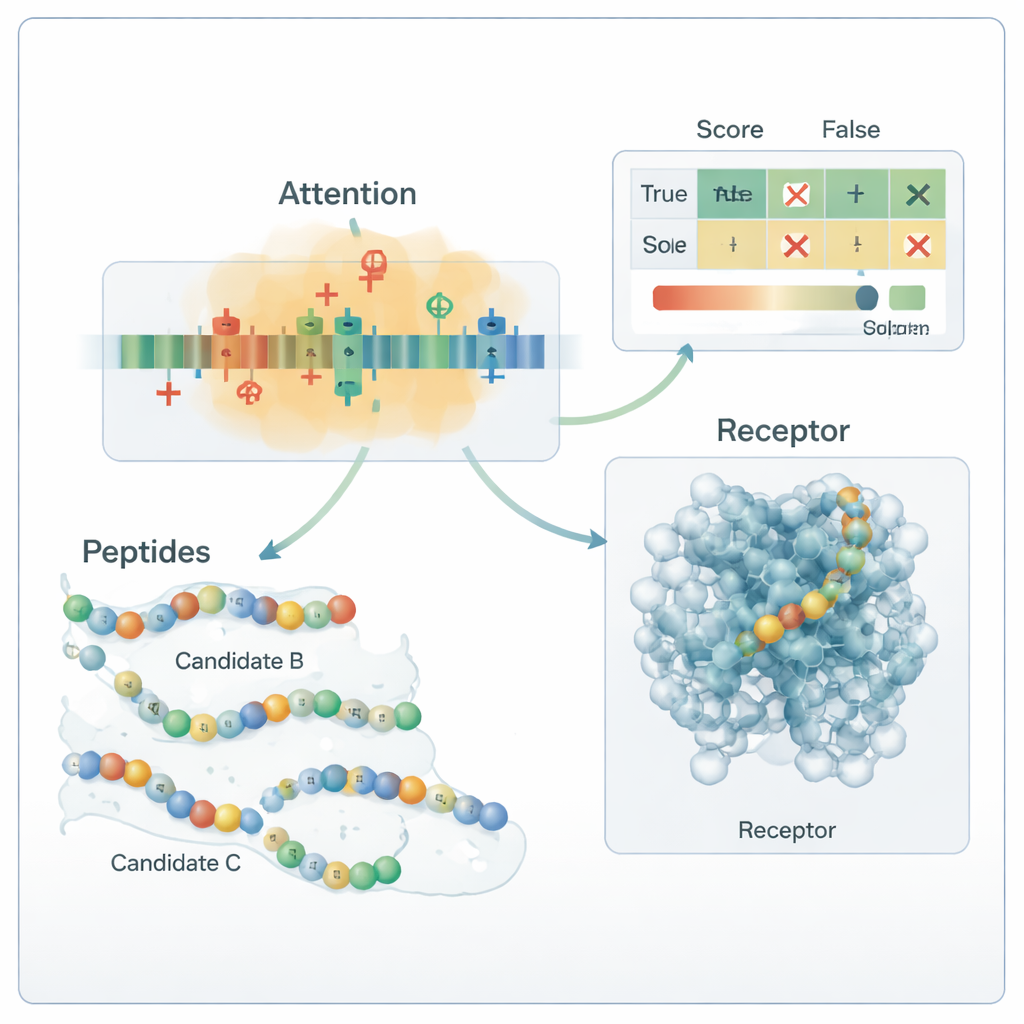
Rdzeniem pipeline’u jest hybrydowy model głębokiego uczenia. Sieć konwolucyjna (CNN) skanuje sekwencję peptydu, poszukując krótkich motywów, które mają tendencję pojawiać się w aktywnych peptydach, podobnie jak filtry w systemie rozpoznawania obrazów. Ponad tym, warstwa attention uczy się, które pozycje w sekwencji są najistotniejsze, uchwytując związki długiego zasięgu między odległymi resztami. Wyjście tego modułu sekwencyjnego jest łączone z globalnymi deskryptorami chemicznymi i przekazywane do kilku standardowych klasyfikatorów maszynowych — maszyn wektorów nośnych, drzew decyzyjnych, k-najbliższych sąsiadów oraz drzew wzmocnionych gradientowo. Specjalizowana metoda optymalizacji, nazwana OptimizedTPE, automatycznie dostraja ich ustawienia, równoważąc dokładność i ryzyko przeuczenia. Mechanizm attention daje też mapy „ważności” na poziomie reszt, pomagając naukowcom zobaczyć, które fragmenty każdego peptydu wpływają na decyzje modelu.
Tworzenie nowych kandydatów przy jednoczesnym unikaniu przecieku danych
Aby przezwyciężyć niewielką liczbę znanych peptydów przeciwcukrzycowych, zespół dodał etap generacji, który zasila jedynie proces treningowy. Użyli mieszanki strategii — kierowanej mutacji, rekombinacji motywów i wariacyjnego autoenkodera — aby zaproponować nowe sekwencje przypominające, ale nie kopiujące, znane aktywne peptydy. Te kandydatury były następnie filtrowane przez surowe „bramki deskryptorów”, które wymuszają realistyczne wartości ładunku, rozmiaru i skłonności do wiązania, oraz przez zewnętrzne narzędzia oceniające podobieństwo do znanych bioaktywnych peptydów. Tylko sekwencje, które przechodziły te filtry i pozostawały wyraźnie odrębne od wszystkich peptydów testowych, były zachowywane jako słabo etykietowane pozytywy do treningu; żadna z nich nigdy nie była wykorzystywana do oceny modelu. To podejście rozszerzyło zbiór treningowy, zachowując jednocześnie czysty, nieobciążony zbiór testowy.
Jak dobrze działa system i co to oznacza
Gdy poddano go próbie na zupełnie niezależnej puli 180 peptydów badanych eksperymentalnie, zebranych z niedawnej literatury, framework poprawnie oznaczył około 99 na 100 sekwencji, z precyzją i czułością bliskimi 0,99. W praktyce oznacza to, że rzadko przeoczy prawdziwy peptyd przeciwcukrzycowy i rzadko uzna nieaktywny peptyd za obiecujący. Analizy map attention i testy mutacyjne wykazały, że model nauczył się chemicznie rozsądnych reguł: silnie polega na resztach naładowanych dodatnio oraz na niektórych resztach hydrofobowych, które są znane jako istotne dla wiązania z celami związanymi z cukrzycą. Symulacje dokowania molekularnego dodatkowo zasugerowały, że niektóre z nowo wygenerowanych peptydów mogą nawiązywać prawdopodobne kontakty z ludzkim receptorem GLP-1. Choć te przewidywania wciąż wymagają potwierdzenia w laboratorium, badanie demonstruje powtarzalny, biologicznie ugruntowany sposób eksploracji ogromnej przestrzeni możliwych leków peptydowych i priorytetyzacji nielicznych, które najbardziej prawdopodobnie pomogą w kontroli cukrzycy.
Cytowanie: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
Słowa kluczowe: peptydy przeciwcukrzycowe, głębokie uczenie, odkrywanie leków, projektowanie peptydów, receptor GLP-1