Clear Sky Science · pl
R-GAT: klasyfikacja dokumentów o nowotworach z wykorzystaniem grafowej sieci rezydualnej w scenariuszach z ograniczonymi danymi
Dlaczego sortowanie artykułów o nowotworach ma znaczenie
Każdego dnia naukowcy publikują setki nowych prac o raku, od wczesnego wykrywania po obiecujące leki. Większość z tych publikacji najpierw pojawia się w postaci krótkich streszczeń, zwanych abstraktami. Lekarze, badacze i decydenci nie są w stanie przeczytać ich wszystkich, a przeoczenie ważnej pracy może spowolnić postęp. W tym badaniu zadano proste, ale istotne pytanie: czy można zbudować szybki, lekki system komputerowy, który automatycznie sortuje abstrakty związane z rakiem według typu nowotworu, nawet gdy dostępna jest tylko niewielka ilość oznakowanych danych i ograniczone moce obliczeniowe?
Mądrzejszy sposób czytania badań nad rakiem
Autorzy skupili się na czterech rodzajach abstraktów znajdujących się w bazie PubMed: dotyczących raka tarczycy, raka jelita grubego, raka płuca oraz bardziej ogólnych tematów biomedycznych. Stworzyli starannie sprawdzony zbiór 1 875 niedawnych abstraktów, w przybliżeniu równomiernie rozłożonych między tymi czterema grupami. Taka równowaga pomaga uniknąć uprzedzeń faworyzujących którykolwiek typ nowotworu. Przed modelowaniem teksty zostały oczyszczone: podzielone na tokeny, sprawdzono pisownię, znormalizowano pokrewne formy wyrazów i usunięto mało informatywne terminy. Oczyszczone abstrakty przekształcono następnie w postać numeryczną przy użyciu kilku standardowych metod, tak aby różne typy modeli mogły być porównane w uczciwy sposób.
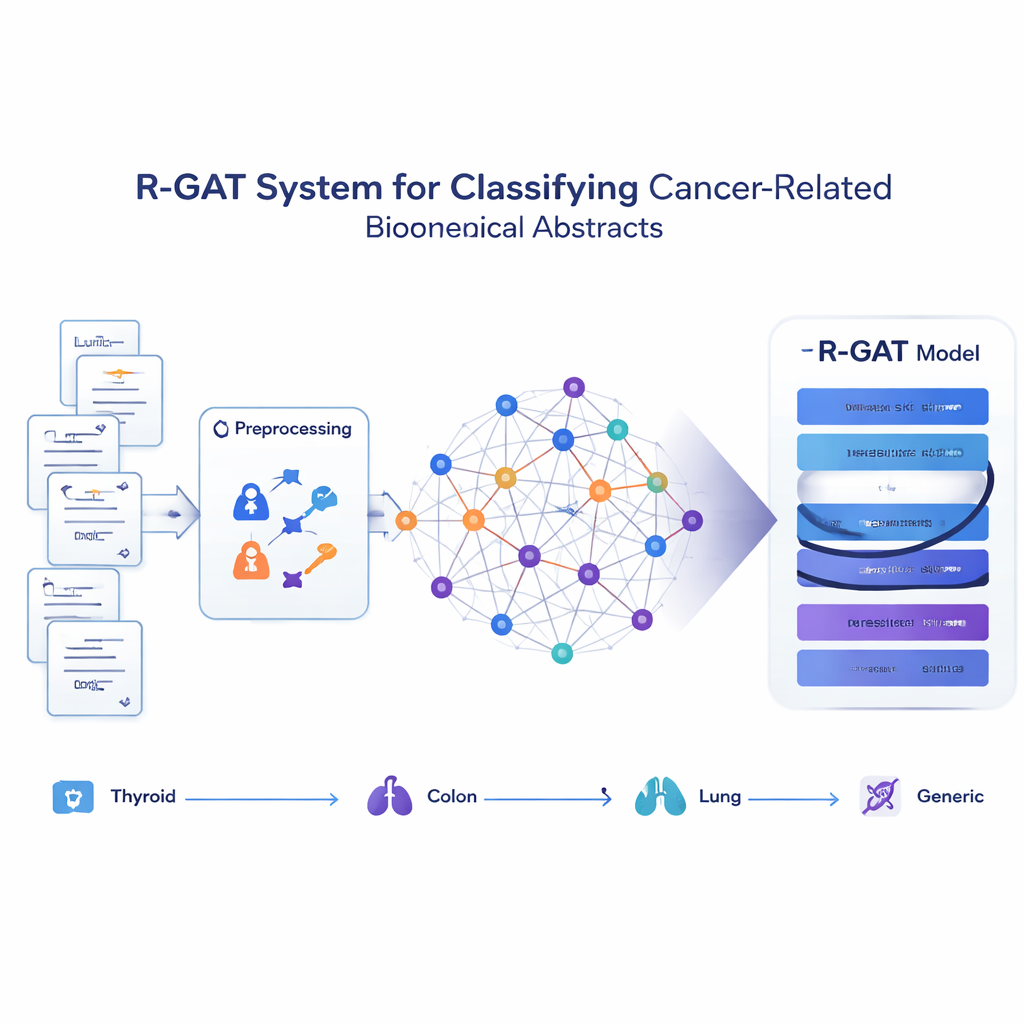
Przekształcanie artykułów w sieć idei
Zamiast traktować każdy abstrakt jako izolowany ciąg słów, proponowana metoda, nazwana R-GAT (Residual Graph Attention Network), postrzega całą kolekcję jako sieć. W tej sieci każdy abstrakt jest węzłem, a połączenia reprezentują, jak podobne są dwa abstrakty pod względem treści. Jeśli dwie prace omawiają bliskie tematy, łącze między nimi jest silne; jeśli nie, jest słabe lub nieobecne. To pozwala modelowi analizować abstrakt w kontekście jego sąsiadów, naśladując sposób, w jaki czytelnik może lepiej zrozumieć jedno badanie, znając powiązane prace.
Jak nowy model uczy się od sąsiadów
R-GAT opiera się na dwóch kluczowych pomysłach współczesnej sztucznej inteligencji: uwadze (attention) i połączeniach rezydualnych. Mechanizm uwagi pozwala modelowi skupić się bardziej na najbardziej istotnych sąsiednich abstraktach w sieci, zamiast traktować wszystkich sąsiadów jednakowo. Wiele „głów” uwagi poszukuje jednocześnie różnych rodzajów wzorców. Połączenia rezydualne działają jak skróty, które przekazują informacje przez głębsze warstwy sieci, pomagając modelowi uniknąć utraty ważnych sygnałów podczas uczenia. Po przetworzeniu grafu przez kilka warstw uwagi i tych ścieżek-skrótów system kondensuje informacje z całej sieci do zwartego podsumowania, które trafia do końcowego klasyfikatora przewidującego, do której z czterech kategorii należy dany abstrakt.
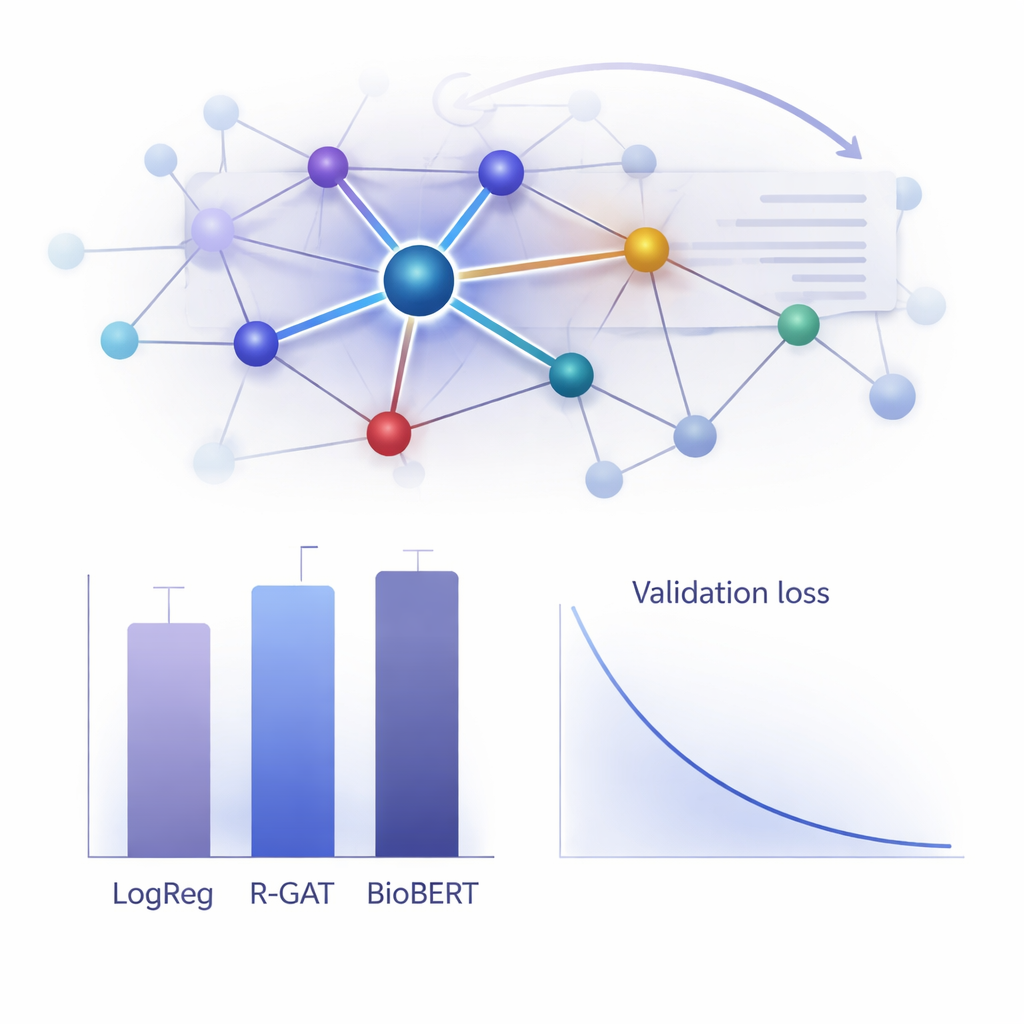
Jak to działa w praktyce?
Aby ocenić wartość R-GAT, autorzy porównali go z szerokim zakresem alternatyw, od klasycznych modeli liniowych po nowoczesne systemy transformatorowe, takie jak BioBERT, które są popularne, lecz obciążające obliczeniowo. Co zaskakujące, prosty model regresji logistycznej korzystający z cech opartych na zliczaniu słów osiągnął najwyższy surowy wynik na tym konkretnym zbiorze danych, a BioBERT również wypadł bardzo dobrze — jednak oba podejścia miały wady, w tym zależność od określonych wyborów cech lub potrzebę znacznych zasobów obliczeniowych. R-GAT osiągnął makro F1 około 0,96, blisko najlepszych modeli, przy jednoczesnym wykazywaniu bardzo stabilnych wyników w różnych podziałach na zbiory treningowe i testowe. Starannie przeprowadzone testy, w których usunięto mechanizmy uwagi lub połączenia rezydualne, pokazują wyraźny spadek wydajności, potwierdzając, że obie składowe są kluczowe dla odporności modelu przy ograniczonych danych.
Co to oznacza dla przyszłych badań nad rakiem
Dla osoby niezwiązanej z tematem wniosek jest prosty: R-GAT to praktyczne narzędzie, które pomaga sortować prace naukowe o raku według typu nowotworu z wysoką i spójną dokładnością, bez konieczności dysponowania gigantycznymi zbiorami danych czy drogim sprzętem. Nie zastępuje najsilniejszych modeli językowych dostępnych na rynku, ale oferuje solidny kompromis — szczególnie przydatny dla szpitali, zespołów badawczych czy służb zdrowia publicznego, które potrzebują niezawodnych, powtarzalnych wyników przy ograniczonym budżecie i danych. Udostępniając zarówno swój model, jak i skuratowany zestaw danych, autorzy dostarczają też wspólny punkt odniesienia, którego inni mogą użyć do budowy i testowania ulepszonych systemów. W dłuższej perspektywie takie narzędzia mogą ułatwić ekspertom śledzenie literatury onkologicznej i przekuwanie nowych odkryć w lepszą opiekę.
Cytowanie: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
Słowa kluczowe: informatyka onkologiczna, biomedyczne wydobywanie tekstu, klasyfikacja dokumentów, grafowe sieci neuronowe, uczenie przy ograniczonych danych