Clear Sky Science · pl
Solidne rozpoznawanie miejsc przy zmianach oświetlenia z użyciem pseudo-LiDAR z obrazów omnidirectionalnych
Roboty, które nigdy się nie gubią po zmroku
Wyobraź sobie robota, który potrafi rozpoznać, gdzie znajduje się w budynku, niezależnie od tego, czy jest południe i słońce wpada przez okna, czy późna noc i świecą tylko pojedyncze lampy. W tej pracy zaprezentowano nowy sposób zapewnienia robotom tak niezawodnego zmysłu miejsca, używając tylko jednej, stosunkowo taniej kamery. Przekształcając płaskie obrazy w informacje 3D, badacze sprawiają, że nawigacja robota staje się znacznie mniej wrażliwa na cienie, olśnienia i inne trudne zmiany oświetlenia, które zwykle mylą systemy oparte na widzeniu.
Dlaczego znalezienie tego samego miejsca dwa razy jest trudne
Dla robota „rozpoznawanie miejsca” oznacza stwierdzenie „byłem tu wcześniej”, dzięki czemu może się zlokalizować na mapie i bezpiecznie poruszać. Tradycyjne systemy opierają się albo na zwykłych kamerach, albo na laserowych czujnikach zasięgu znanych jako LiDAR. Kamery są tanie i rejestrują bogate informacje o kolorze i teksturze, ale ich obraz zmienia się drastycznie między pochmurnym, słonecznym a nocnym oświetleniem. LiDAR jest dużo bardziej stabilny, bo mierzy bezpośrednio odległość, lecz jest masywny i kosztowny. Niektóre roboty łączą kilka czujników, ale to zwiększa cenę i złożoność systemu. Autorzy tej pracy obrały inną drogę: upraszczają sprzęt do jednej kamery omnidirectionalnej, która widzi dookoła robota, i wzmacniają oprogramowanie, żeby robot rozumiał strukturę 3D zamiast polegać na surowym wyglądzie sceny.
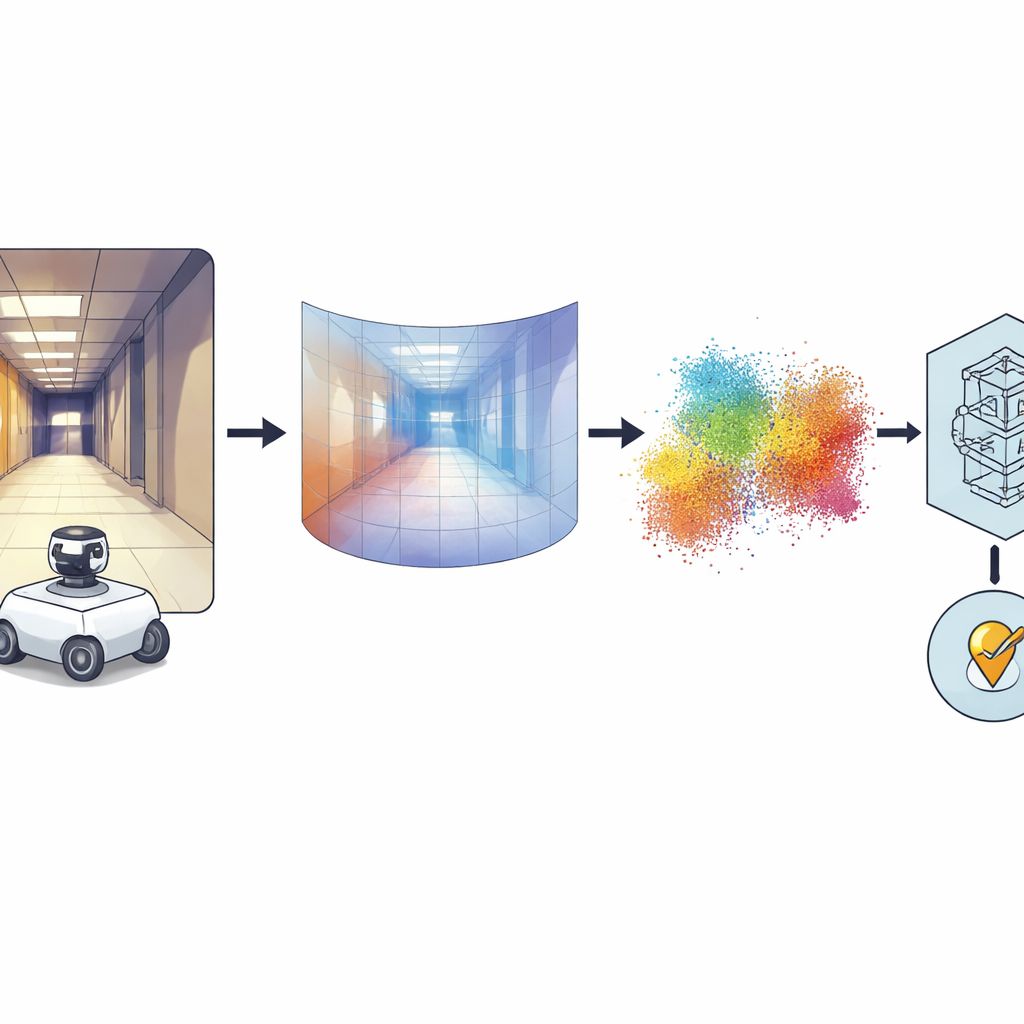
Z panoramicznych zdjęć do kształtów 3D
Kluczową ideą jest przekształcenie każdego obrazu panoramicznego w gęstą mapę głębi, gdzie każdy piksel koduje, jak daleko dany fragment sceny jest od kamery. W tym celu autorzy wykorzystują potężny „model bazowy” o nazwie Distill Any Depth, który nauczył się wnioskować głębię z ogromnych zbiorów obrazów. Powstała mapa głębi jest następnie przekształcana w chmurę punktów 3D — rodzaj wirtualnego LiDARu, czyli pseudo-LiDAR — bez potrzeby używania prawdziwego skanera laserowego. Dodatkowe przetwarzanie usuwa artefakty wprowadzone przez specjalne lustro używane w kamerze 360°, tak aby uzupełnić brakujące lub zasłonięte regiony. Na koniec sieć neuronowa o nazwie MinkUNeXt, zaprojektowana do działania bezpośrednio na chmurach punktów 3D, kompresuje każdą chmurę do zwartego odcisku, który oddaje ogólny układ miejsca.
Nauka systemu ignorowania sztuczek świetlnych
Estymacje głębi nie są doskonałe, zwłaszcza gdy oświetlenie zmienia się gwałtownie z chwili na chwilę. Aby uczynić system odpornym, badacze wprowadzają nowy trik treningowy zwany Distilled Depth Variations. Zamiast ufać pojedynczemu modelowi głębi, celowo mieszają prognozy głębi pochodzące z kilku mniejszych, mniej dokładnych wersji estymatora głębi. Ta kontrolowana „szumowa” perturbacja naśladuje zniekształcenia pojawiające się przy różnych warunkach oświetleniowych, zmuszając sieć 3D do nauki tego, co naprawdę istotne w geometrii miejsca, a co można bezpiecznie zignorować. Dodatkowo wzbogacają każdy punkt 3D informacjami o krawędziach obrazu i sile tekstury — cechach, które zazwyczaj pozostają bardziej stabilne przy zmianach oświetlenia niż surowy kolor.
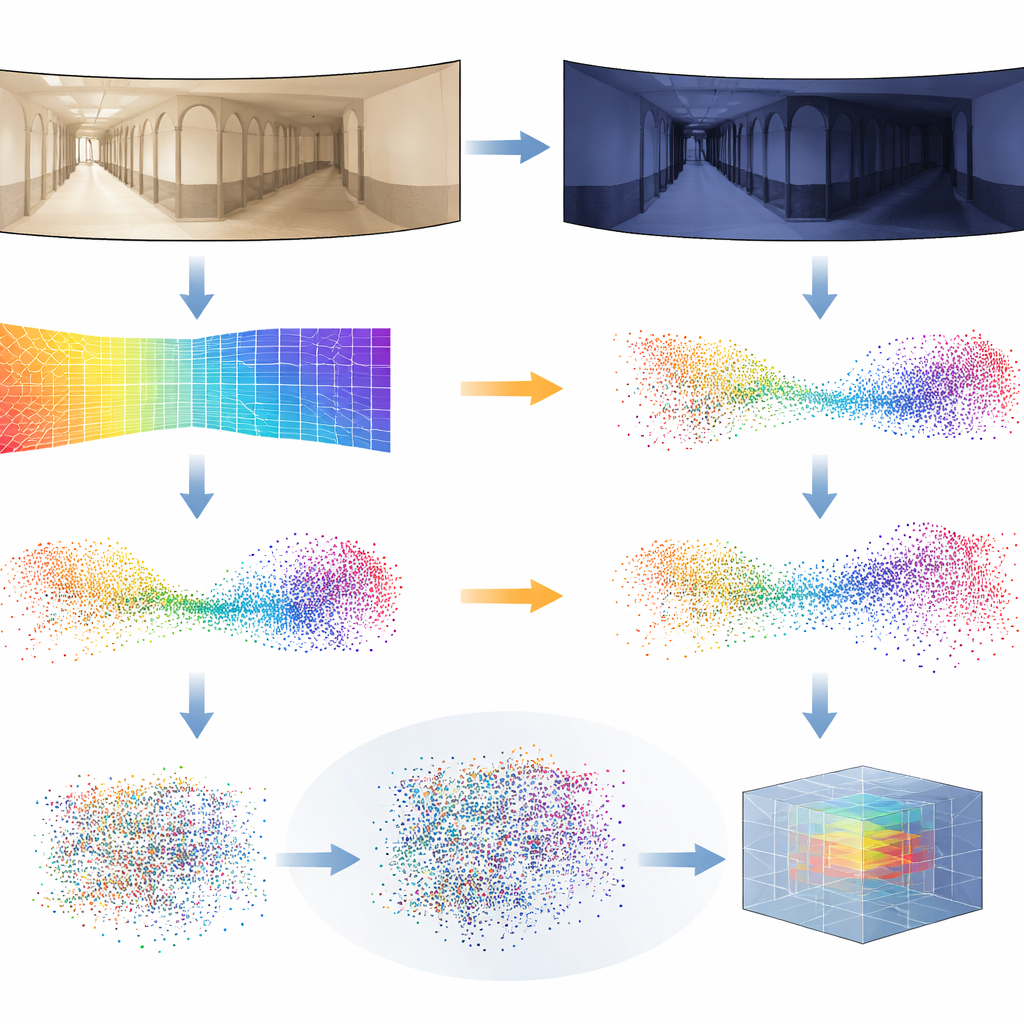
Dowód działania w rzeczywistym świecie
Aby przetestować swoje podejście, zespół sięgnął po wymagające publiczne zbiory danych z wewnętrznych tras robotów. W tych kolekcjach robot wielokrotnie przemierza korytarze i pomieszczenia w warunkach pochmurnego dnia, jasnego słońca i nocy, podczas gdy meble i ludzie się przemieszczać. Autorzy trenowali swój system używając tylko obrazów z pochmurnego dnia z jednego budynku, a następnie oceniali go we wszystkich budynkach i warunkach oświetleniowych, włącznie ze scenami, których nigdy wcześniej nie widział. Ich metoda pseudo-LiDAR stale dorównywała lub przewyższała wiodące techniki oparte na obrazach 2D oraz inne systemy 3D, szczególnie w najtrudniejszych przypadkach, takich jak nocne przejazdy czy przenoszenie do zupełnie nowych środowisk. Pokazali również, że ta sama linia przetwarzania działa z zwykłymi kamerami skierowanymi do przodu, nie tylko panoramicznymi, dokonując odpowiedniej projekcji z głębi do 3D.
Co to oznacza dla przyszłych robotów
Mówiąc prościej, praca ta pokazuje, że robot może uzyskać świadomość otoczenia zbliżoną do LiDAR-u, używając tylko jednej kamery i sprytnego oprogramowania. Skupiając się na strukturze 3D zamiast zmiennych detali oświetlenia i koloru, system potrafi rozpoznawać miejsca niezawodnie w dzień, w nocy i przy zmianach pogodowych, przy jednoczesnym zachowaniu prostoty i przystępności sprzętu. To może uczynić solidną nawigację wewnętrzną bardziej dostępną dla robotów serwisowych, pojazdów magazynowych i urządzeń wspomagających, a także otwiera drogę do przyszłych systemów łączących głębię z wyższopoziomowym rozumieniem sceny dla jeszcze bardziej niezawodnej autonomii.
Cytowanie: Cabrera, J.J., Alfaro, M., Gil, A. et al. Robust place recognition under illumination changes using pseudo-LiDAR from omnidirectional images. Sci Rep 16, 8817 (2026). https://doi.org/10.1038/s41598-026-39848-y
Słowa kluczowe: lokalizacja robota, widzenie 3D, rozpoznawanie miejsca, estymacja głębi, kamery omnidirectionalne