Clear Sky Science · pl
Ulepszanie ekstrakcji dróg z obrazów teledetekcyjnych za pomocą DS-Unet z komplementarną atencją i zastępczymi gradientami
Bardziej precyzyjne mapy ze space
Współczesne mapy cyfrowe w dużej mierze opierają się na zdjęciach satelitarnych i lotniczych, lecz automatyczne wyznaczanie dróg na tych obrazach okazuje się zadaniem trudnym. Cienie, drzewa, drogi gruntowe i sezonowe zmiany potrafią zmylić algorytmy, prowadząc do przerwanych lub fałszywych odcinków dróg na mapie. Niniejszy artykuł przedstawia nową metodę analizy obrazów, nazwaną DS-Unet, której celem jest tworzenie czystszych, bardziej kompletnych sieci drogowych z obrazów teledetekcyjnych, co zwiększa niezawodność map wykorzystywanych do nawigacji, planowania i działań ratunkowych.
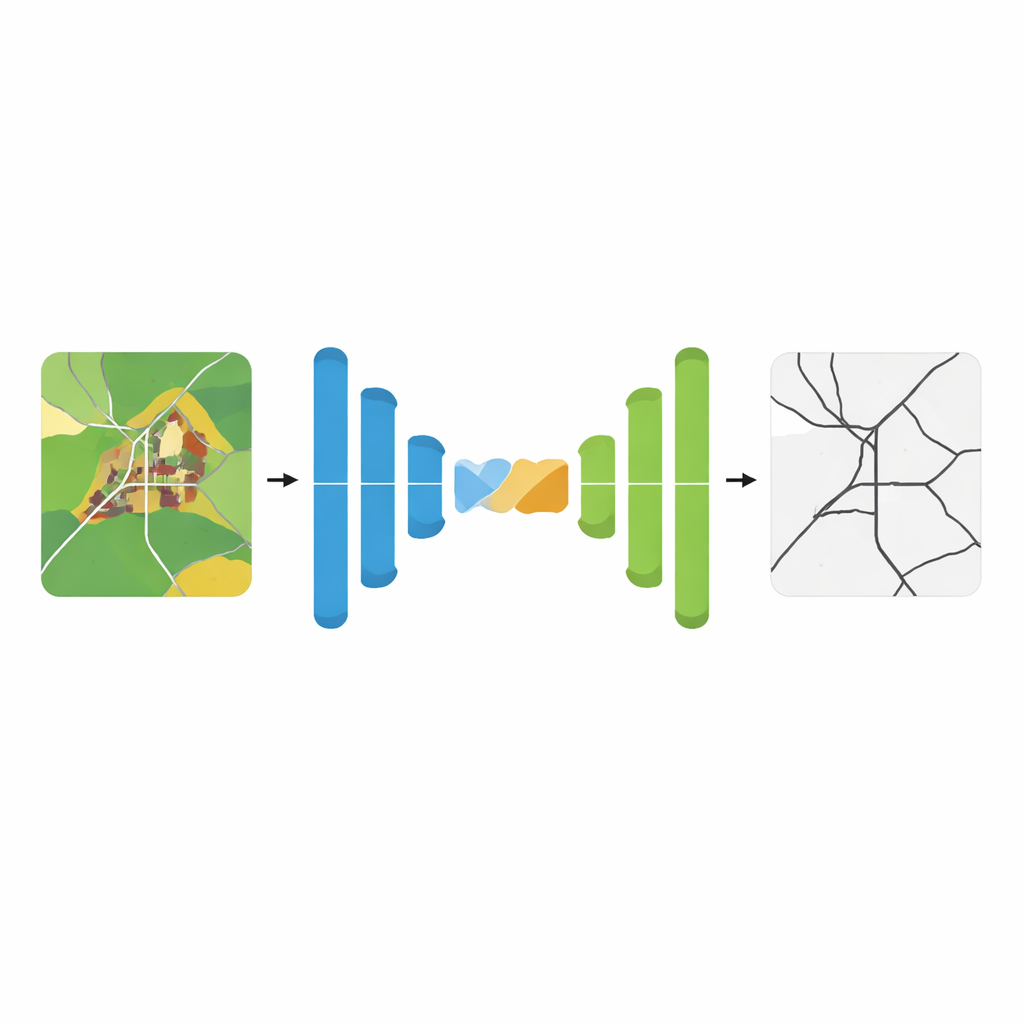
Dlaczego wykrywanie dróg jest tak trudne
Z dużej wysokości drogi wplatają się przez miasta, pola i zakłady przemysłowe, często ukryte za budynkami, roślinnością i zmieniającym się oświetleniem. Tradycyjne systemy głębokiego uczenia, które napędzają wiele usług mapowych, analizują obraz kawałek po kawałku. Dobrze wykrywają lokalne wzorce, takie jak pas asfaltu, ale mają problem ze zrozumieniem, jak odległe fragmenty łączą się w ciągłą drogę. W efekcie mogą przeoczyć wąskie uliczki w gęsto zabudowanych wsiach, rozdzielać długie autostrady na fragmenty albo mylić podobnie wyglądające obiekty, jak ścieżki gruntowe czy oznaczenia na parkingach, z prawdziwymi drogami.
Nowy sposób łączenia tego, co widzi sieć
DS-Unet opiera się na popularnej architekturze sieci, która przetwarza obraz przez ścieżkę kontrakcyjną (podsumowującą szczegóły) i ścieżkę ekspansyjną (odtwarzającą predykcję w pełnej rozdzielczości). Klasyczne rozwiązania łączą te ścieżki prostymi skrótami przekazującymi wczesne informacje wizualne. Autorzy argumentują, że takie skróty mieszają informacje w prymitywny sposób, często łącząc użyteczne krawędzie dróg z rozpraszającymi wzorcami tła. DS-Unet zastępuje je inteligentniejszym łącznikiem — Modułem Komplementarnej Fuzji Atencji, który stara się podkreślić właściwe detale, jednocześnie zachowując szerszy kontekst obrazu.
Pozwalając sieci skupić się i spojrzeć szeroko
Nowy moduł fuzji działa w dwóch uzupełniających się etapach. Najpierw etap „dyskryminacyjny” koncentruje się na tym, co wyróżnia drogi na tle otoczenia. Skutecznie odejmuje szerokie, niskozróżnicowane wzorce tła z map cech, działając jak filtr górnoprzepustowy, który wyostrza krawędzie i tekstury dróg przy jednoczesnym tłumieniu zaszumienia, takiego jak pola czy dachy. Następnie etap „kontekstu globalnego” zbiera informacje z całego obrazu, aby odległe odcinki drogi mogły być rozpoznawane jako część jednej sieci. Poprzez połączenie tych dwóch perspektyw model lepiej zachowuje wąskie, kratowe uliczki we wsiach i utrzymuje ciągłość pętli oraz zakrętów w obszarach przemysłowych.
Utrzymywanie procesu uczenia przy życiu
Głębokie sieci uczą się przez dostosowywanie wielu wewnętrznych „neuronów”, lecz powszechna funkcja aktywacji, ceniona za prostotę i szybkość, może sprawić, że niektóre neurony przestaną się w ogóle aktualizować. Gdy zbyt wiele z nich „milknie”, trening staje się niestabilny, a końcowe przewidywania tracą drobne szczegóły. Aby temu zapobiec, autorzy przyjmują technikę nazwaną SUGAR, która zachowuje prostą regułę do obliczeń w przód, ale używa bardziej gładkiego, sztucznego gradientu w tle podczas aktualizacji modelu. Ten zabieg utrzymuje przepływ sygnałów gradientowych nawet przy słabych wejściach, dzięki czemu więcej neuronów pozostaje aktywnych i może przyczyniać się do nauki subtelnych wzorców drogowych.
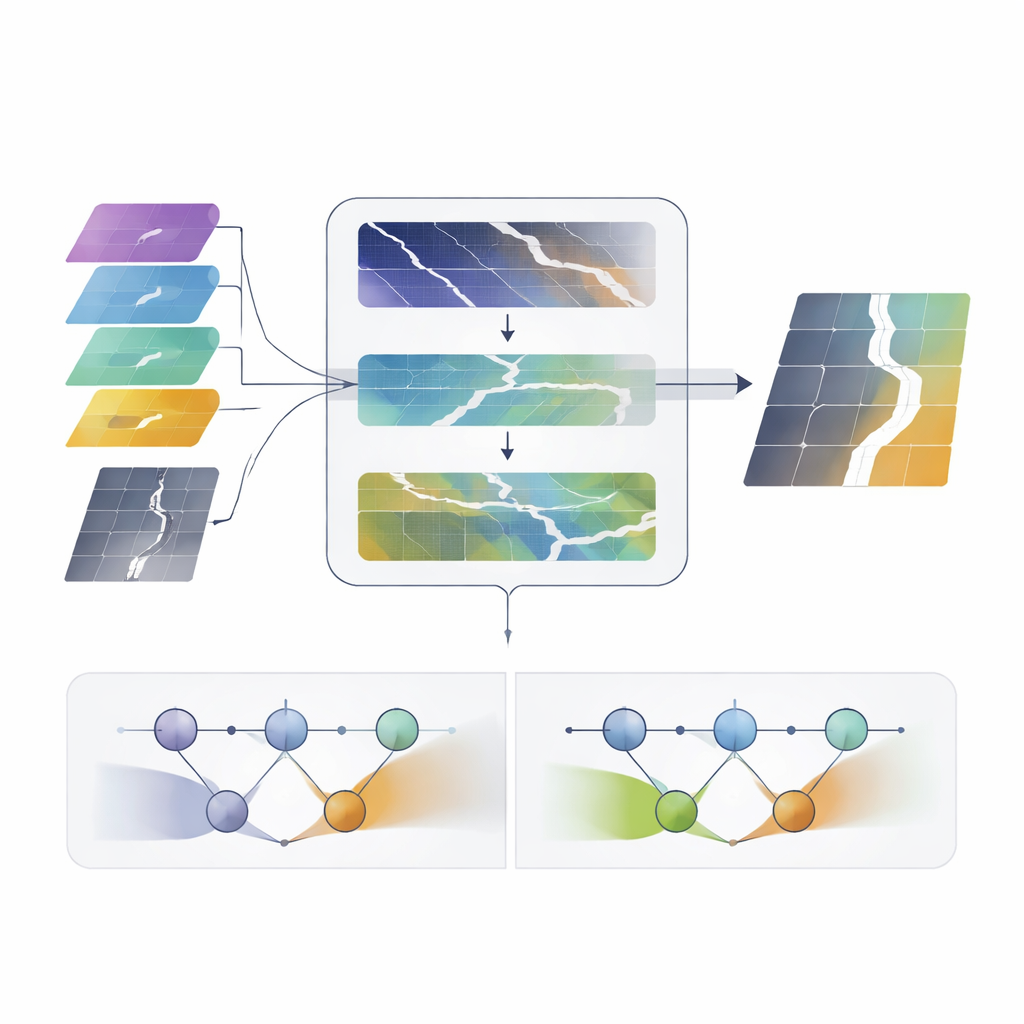
Dowód skuteczności w praktyce
Aby przetestować DS-Unet, zespół użył dwóch dobrze znanych zbiorów satelitarnych obrazów dróg z różnych regionów i krajobrazów. Podzielili duże obrazy na przystępne kafelki, zastosowali realistyczne modyfikacje jasności, barwy i orientacji, a następnie trenowali swój system równocześnie z 17 wiodącymi metodami ekstrakcji dróg i segmentacji, obejmującymi zarówno klasyczne sieci konwolucyjne, jak i nowsze architektury oparte na transformerach. We wszystkich kluczowych miarach dokładności — ile rzeczywistego obszaru drogi jest uchwycone, jak często unika się fałszywych dróg oraz jak dobrze przewidywana mapa drogi pokrywa się z prawdziwą — DS-Unet konsekwentnie zwyciężał, przy jednoczesnym utrzymaniu wystarczającej prędkości działania, by być praktycznym dla mapowania na dużą skalę.
Co to oznacza dla lepszych map
Mówiąc w prostych słowach, praca ta pokazuje, że nauczenie sieci neuronowej zarówno wyostrzać tło, jak i rozumieć szerszy układ sceny, może dostarczyć czystsze, bardziej połączone mapy dróg z obrazów satelitarnych. W połączeniu z bardziej stabilną regułą uczenia, która utrzymuje aktywność wewnętrznych jednostek modelu, DS-Unet lepiej odwzorowuje wąskie wiejskie uliczki, unika mylenia ścieżek gruntowych z drogami oraz łączy rozproszone fragmenty dróg w spójne sieci niż istniejące systemy. W miarę jak agencje kartograficzne i firmy technologiczne dążą do w pełni zautomatyzowanych, często aktualizowanych map, podejścia takie jak DS-Unet mogą odegrać kluczową rolę w przekształcaniu surowych obrazów w dokładne, użyteczne informacje drogowe dla codziennego użytku.
Cytowanie: Wang, J., Huang, Z., Ren, C. et al. Enhancing remote sensing road extraction via DS-Unet with complementary attention and surrogate gradients. Sci Rep 16, 9044 (2026). https://doi.org/10.1038/s41598-026-39811-x
Słowa kluczowe: drogi z teledetekcji, mapowanie satelitarne, segmentacja z użyciem głębokiego uczenia, sieci oparte na atencji, analiza zdjęć lotniczych