Clear Sky Science · pl
Efektywny pod względem danych trójwymiarowy model wizja‑język dla medycyny wykorzystujący wyłącznie enkoder 2D
Mądrzejsza pomoc dzięki skanom 3D
Gdy lekarze analizują skany CT lub MRI, nie patrzą tylko na pojedyncze obrazy — mentalnie składają setki przekrojów, by zrozumieć problem w trzech wymiarach. Nauczenie komputerów tego samego mogłoby wspierać szybsze, bardziej spójne diagnozy i jaśniejsze raporty dla pacjentów. Jednak obecne systemy sztucznej inteligencji obsługujące skany 3D są bardzo „żarłoczne” pod względem danych, wymagając ogromnych, starannie oznakowanych zbiorów, których wiele szpitali po prostu nie posiada. Artykuł przedstawia sposób, by uzyskać zrozumienie na poziomie 3D przy użyciu istniejącej technologii 2D, obiecując potężne narzędzia łatwiejsze i tańsze w budowie oraz wdrożeniu.
Dlaczego skany 3D są trudne dla AI
Współczesne systemy „wizja–język” już potrafią spojrzeć na obraz medyczny 2D i odpowiedzieć na pytania lub sporządzić raport w prostym języku. Rozszerzenie tej zdolności na wolumeny 3D pozwoliłoby AI rozumieć pełne narządy i subtelne zmiany, które stają się widoczne dopiero przy analizie wielu przekrojów razem. Problem w tym, że większość istniejących systemów 3D opiera się na specjalnych enkoderach 3D trenowanych od podstaw na ogromnych zbiorach oznakowanych skanów. Takie zbiory są rzadkie, drogie w anotowaniu i często związane z dobrze finansowanymi ośrodkami, co ogranicza, kto może z nich korzystać. Równocześnie traktowanie każdego przekroju jako osobnego obrazu 2D pozbawia dane naturalnej ciągłości między przekrojami i zalewa model powtarzalną informacją.
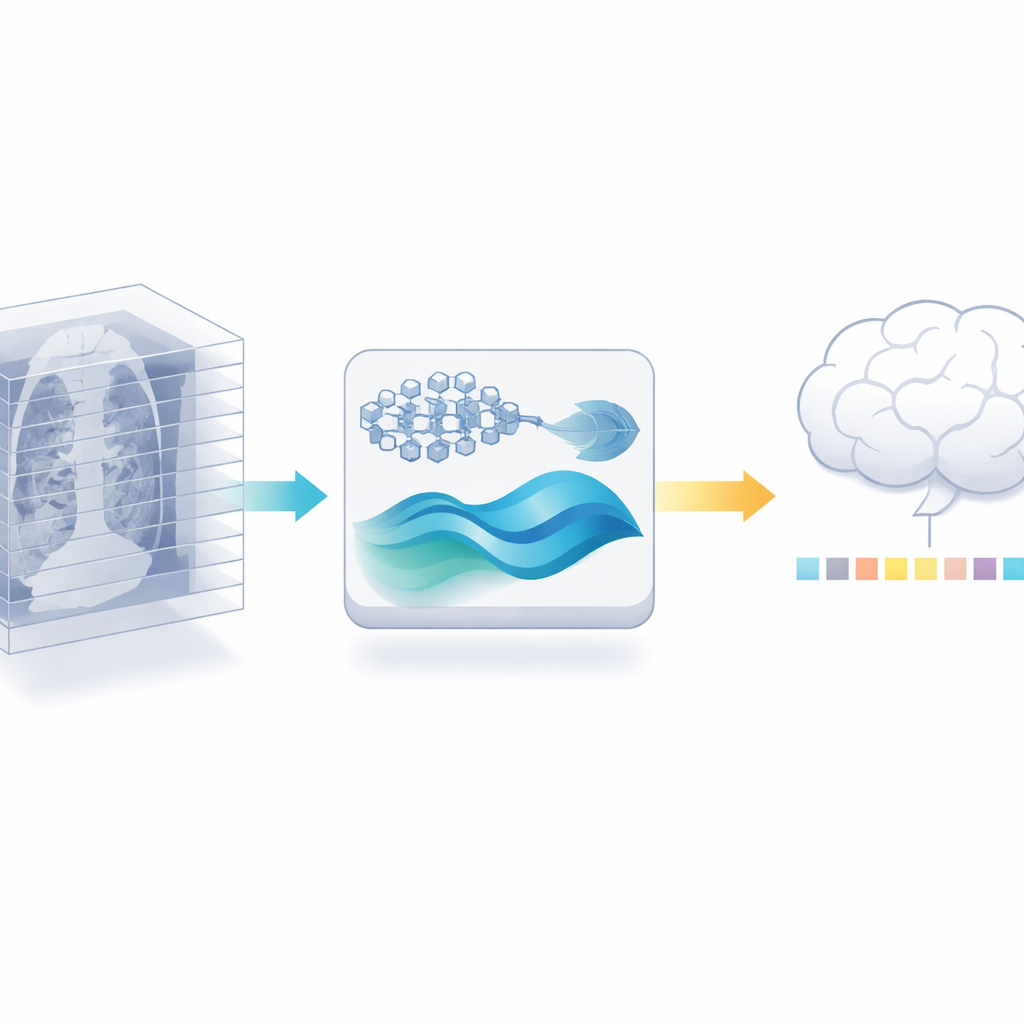
Wykorzystanie eksperta 2D do pracy 3D
Autorzy proponują inną ścieżkę: zamiast trenować nowy enkoder 3D, ponownie wykorzystują silny model obrazów medycznych 2D, który już został wytrenowany na milionach oznakowanych obrazów z literatury medycznej. Najpierw dzielą każdy skan 3D na pojedyncze przekroje i pozwalają temu modelowi 2D wydobyć szczegółowe cechy z każdego przekroju. Następnie starannie redukują redundancję: ponieważ sąsiadujące przekroje często wyglądają niemal identycznie, kontrola podobieństwa może odrzucić wiele niemal‑duplikatów, zachowując najbardziej informacyjne widoki. Ten krok sam w sobie zmniejsza ilość danych, które muszą przetwarzać dalsze etapy, bez potrzeby pozyskiwania dodatkowo oznakowanych skanów.
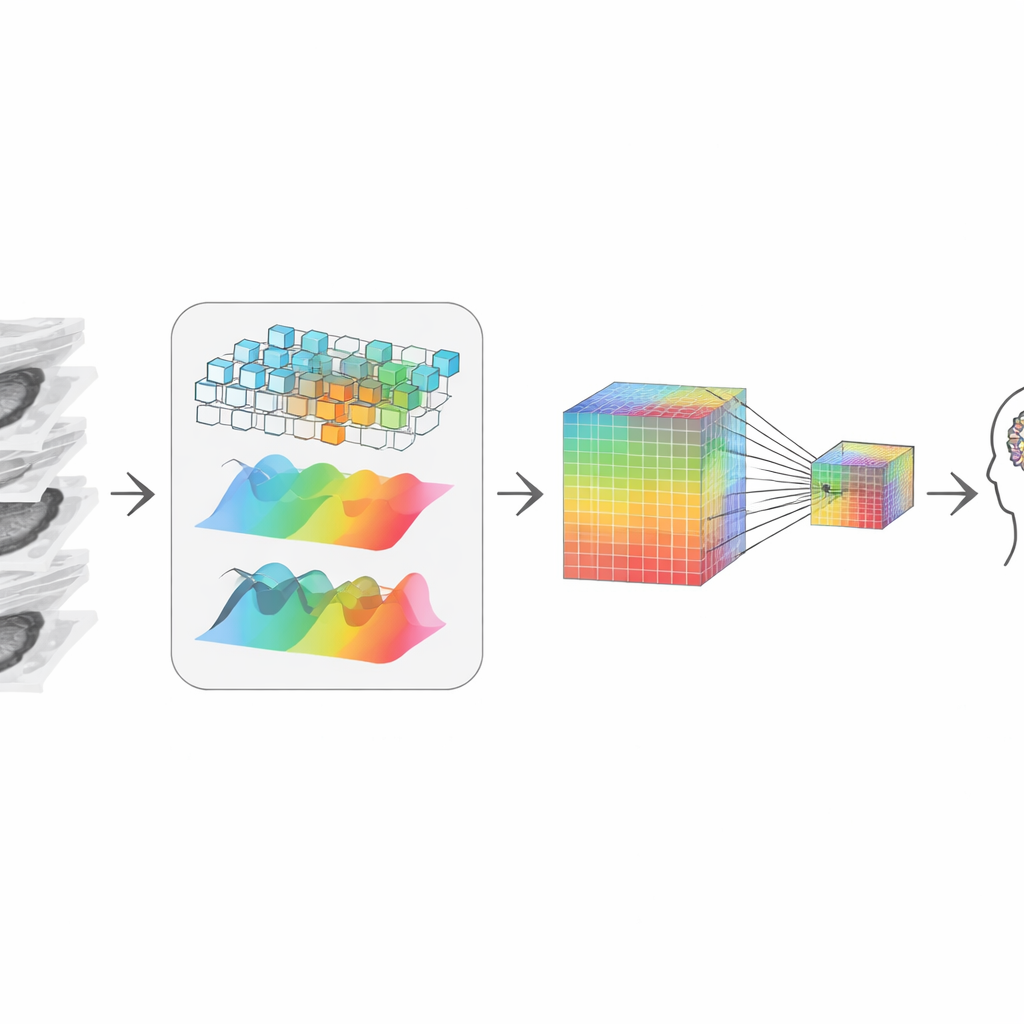
Odbudowanie trójwymiarowej opowieści z kawałków
Po przycięciu system musi „zszyć” pozostałe przekroje w spójną strukturę 3D. Autorzy osiągają to, łącząc dwa komplementarne spojrzenia na dane. Jedna ścieżka bada lokalne kształty i krawędzie, jak lupa przesuwająca się przez wolumen, wrażliwa na ostre granice i tekstury. Druga ścieżka przekształca dane do widoku częstotliwościowego, który lepiej wychwytuje szerokie wzorce i strukturę na dużą skalę pomiędzy przekrojami — jak guz się rozciąga albo jak zbudowany jest narząd w całości. Adaptacyjny etap łączenia uczy się, ile ufać każdemu widokowi w danym miejscu, dając reprezentację uwzględniającą zarówno drobne detale, jak i kontekst globalny, mimo że wszystko zaczęło się od przekrojów 2D.
Zachowanie drobnych śladów przy kompresji
Aby komunikować się z dużym modelem językowym — częścią odpowiadającą na pytania i piszącą raporty — informacje wizualne muszą zostać skompresowane do umiarkowanej liczby tokenów, czy „wizualnych słów”. Prosta redukcja rozdzielczości zatarłaby drobne, ale krytyczne sygnały, takie jak małe zwapnienia czy subtelne zmiany tekstury istotne dla diagnozy. Aby tego uniknąć, autorzy tworzą reprezentację dwutorową: jedna ścieżka utrzymuje wysoką rozdzielczość bogatą w detale, druga jest mniejsza i tańsza obliczeniowo. Mechanizm uwagi pozwala każdemu punktowi w mniejszej wersji selektywnie „spojrzeć wstecz” na wersję większą i pobrać najostrzejsze dostępne szczegóły. Efektem jest zwarty wizualny skrót, który nadal przenosi wskazówki ważne dla radiologa, a następnie jest przekazywany do modelu językowego w celu wnioskowania.
Dowód na rzeczywistych zadaniach medycznych
Aby przetestować swoje rozwiązanie, badacze ocenili je na publicznych benchmarkach 3D, które stawiają dwa główne zadania: czy system potrafi napisać dokładne opisy w stylu radiologicznym skanów 3D oraz czy potrafi odpowiedzieć na pytania o to, co jest na nich widoczne. Ich podejście, mimo że nigdy nie trenowano specjalnego enkodera 3D, przewyższyło kilka silnych modeli opartych na 3D w obu zadaniach. Generowało bardziej precyzyjne, klinicznie bogate raporty i odpowiadało na pytania dokładniej, również w trudnych kwestiach dotyczących konkretnego narządu, nieprawidłowości czy lokalizacji. Działało też szybciej, wymagało znacznie mniej danych 3D do treningu i dobrze generalizowało na różne typy skanów, takie jak MRI czy PET.
Co to oznacza dla przyszłej opieki
Mówiąc prosto, praca ta pokazuje, że nie trzeba zaczynać od zera z modelami 3D wymagającymi wielkich zbiorów danych, aby uzyskać wysokiej jakości wsparcie AI w analizie wolumenowych skanów. Dzięki inteligentnemu ponownemu wykorzystaniu silnego eksperta 2D, starannemu doborowi informacyjnych przekrojów i odbudowie obrazu 3D przy zachowaniu drobnych detali, autorom udało się osiągnąć wyniki na poziomie stanu wiedzy przy znacznie mniejszych nakładach danych i obliczeń. Jeśli podejście to zostanie szeroko przyjęte, mogłoby udostępnić zaawansowaną pomoc AI — lepsze raporty, jaśniejsze wyjaśnienia i bardziej niezawodną triage — szpitalom i klinikom pozbawionym ogromnych zasobów danych, przybliżając złożoną analizę obrazów do rutynowej praktyki klinicznej.
Cytowanie: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Słowa kluczowe: obrazowanie medyczne 3D, modele wizja‑język, AI w radiologii, uczenie efektywne danych, analiza CT i MRI