Clear Sky Science · pl
Analiza porównawcza wydajności kwantowych map cech dla uczenia maszynowego opartego na jądrach kwantowych
Dlaczego to ma znaczenie poza laboratorium
W miarę jak nasze dane i problemy stają się coraz bardziej złożone, nawet najlepsze współczesne narzędzia uczenia maszynowego mogą mieć trudności ze znalezieniem wyraźnych wzorców. Komputery kwantowe obiecują nowe sposoby rozwiązywania takich problemów, ale wciąż nie jest jasne, kiedy i w jaki sposób rzeczywiście mogą pomóc. Niniejszy artykuł bada praktyczny element tej układanki: jak projektować i stroić klasyfikatory oparte na kwantach, aby mogły konkurować z dobrze ugruntowanymi metodami klasycznymi, a czasem je przewyższać, zarówno na zadaniach zabawkowych, jak i na rzeczywistym zbiorze danych medycznych.
Przekształcanie podobieństwa w moc kwantową
Wiele skutecznych metod uczenia, takich jak maszyny wektorów nośnych (SVM), opiera się na „jądrach”, które mierzą, jak podobne są dwa punkty danych po niewidocznej transformacji do bogatszej przestrzeni cech. Komputery kwantowe potrafią naturalnie realizować takie transformacje przez kodowanie danych w stanach kwantowych, a następnie porównywanie, jak bardzo dwa stany nachodzą na siebie. Autorzy koncentrują się na tych jądrach kwantowych oraz na „mapach cech”, które określają, jak obwód kwantowy przekształca zwykłe liczby w stany kwantowe. Dobra mapa cech ułatwia separację splątanych danych; słaba marnuje zasoby sprzętu kwantowego. Badanie stawia dwa kluczowe pytania: które mapy cech działają najlepiej i jak dużo może zyskać się dzięki starannemu strojeniu?
Testowanie kilku kwantowych przepisów
Naukowcy wprowadzają nową mapę cech wysokiego rzędu i porównują ją z pięcioma projektami stanowiącymi stan wiedzy z wcześniejszych prac. Każda mapa wykorzystuje prosty obwód dwukubitowy stosujący rotacje pojedynczych kubitów oraz bramkę splatającą, lecz formuły matematyczne sterujące tymi rotacjami różnią się. Aby utrzymać fokus badania, struktura obwodu kwantowego, ustawienia maszyny wektorów nośnych i procedura ewaluacji pozostają stałe, podczas gdy jedynie mapa cech i jej wewnętrzna „siła rotacji” są zmieniane. Pozwala to przypisać poprawę wydajności bezpośrednio sposobowi kodowania danych w stanach kwantowych, a nie dodatkowym modyfikacjom klasycznego algorytmu uczącego.
Od wzorców zabawkowych po diagnozę raka
Zespół ocenia jądra kwantowe na trzech klasycznych dwuwymiarowych zadaniach testowych — koncentrycznych okręgach, księżycowatych półksiężycach i wzorze XOR — oraz na zredukowanej wersji zbioru Wisconsin Breast Cancer Diagnostic. Dla danych medycznych dwie najbardziej informacyjne cechy oparte na obrazowaniu wybierane są za pomocą standardowej metody selekcji cech. Wszystkie wejścia są następnie przeskalowane do tego samego zakresu i podawane do płytkich obwodów dwukubitowych, co utrzymuje eksperymenty w realistycznym zakresie dla dzisiejszych hałaśliwych układów kwantowych średniej skali. Wyniki porównuje się z szerokim zestawem modeli klasycznych, w tym liniowymi i z funkcją radialną SVM, drzewami decyzyjnymi, lasami losowymi, boostingiem, naiwnym Bayesem, liniową analizą dyskryminacyjną oraz perceptronami wielowarstwowymi, wykorzystując dokładność i współczynnik korelacji Matthewsa, aby uchwycić zarówno poprawność, jak i równowagę klas.
Co ujawniły porównania
W prostszych zestawach benchmarkowych ulepszone jądra kwantowe — zwłaszcza te zbudowane na bazie nowej mapy cech i dwóch istniejących — osiągają niemal doskonałą klasyfikację, dorównując lub przewyższając większość klasycznych konkurentów. W bardziej wymagających danych o raku piersi najlepsze mapy cech kwantowych pozostają konkurencyjne wobec silnych klasycznych baz, takich jak jądra z funkcją radialną i sieci neuronowe. Kluczowym pokrętłem jest współczynnik rotacji skalujący, jak silnie wartości wejściowe wpływają na rotacje kwantowe. Przez przebieg tego współczynnika przez kilka wartości autorzy pokazują, że jego dobre dobranie może znacząco poprawić wydajność, a optymalna wartość zależy od zbioru danych. Wizualizacje przestrzeni cech i wynikających granic decyzyjnych wyraźnie pokazują, że niektóre mapy wycinają drobiazgowe, dobrze wycentrowane regiony separujące, podczas gdy inne pozostawiają zniekształcone lub źle umieszczone granice, co tłumaczy rozrzut wyników.
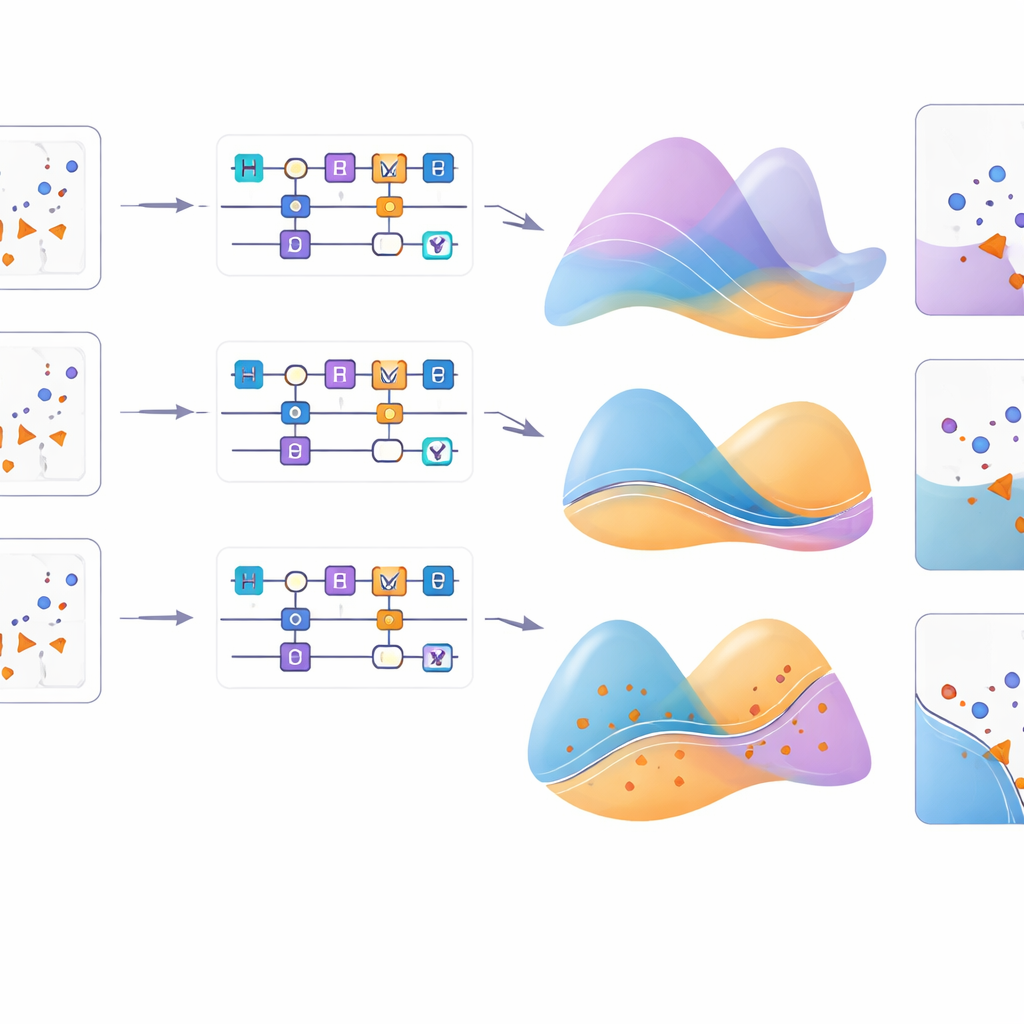
Zbliżenie: jak to działa
Aby lepiej zrozumieć te efekty, badanie wizualizuje, jak każda mapa cech przekształca siatkę punktów wejściowych dla różnych problemów. Dla wzoru kołowego większość map poprawnie odtwarza strukturę leżącą u podstaw, ale dla półksiężyców i rzeczywistych danych o raku tylko podzbiór map dobrze zgadza się z prawdziwym rozkładem. Dodatkowe eksperymenty zmieniają typ rotacji pojedynczego kubitu i potwierdzają, że dla pewnych wzorców, takich jak XOR, wybór osi rotacji może mieć znaczenie równie duże jak szczegóły formuły kodującej. Ogólnie rzecz biorąc, nowa mapa cech konsekwentnie należy do najlepszych, szczególnie w połączeniu z odpowiednim współczynnikiem rotacji, co uwypukla subtelną interakcję między bramkami kwantowymi, formułami kodowania a ustawieniami hiperparametrów.
Co to oznacza na przyszłość
Dla osoby niebędącej specjalistą główny przekaz jest taki, że przewaga kwantowa w uczeniu maszynowym nie pojawi się „za darmo” tylko przez uruchomienie standardowych modeli na sprzęcie kwantowym. Sukces zależy od stworzenia właściwego sposobu podawania danych do obwodów kwantowych oraz od stroj enia kilku krytycznych ustawień, tak aby stany kwantowe uchwyciły strukturę rozważanego problemu. Artykuł dostarcza mapy drogowej do osiągnięcia tego z metodami jądrowymi kwantowymi, pokazując, że przemyślane zaprojektowane i strojone mapy cech kwantowych mogą dawać mocne, czasem lepsze wyniki nawet przy bardzo małych obwodach. Jednocześnie autorzy zauważają, że ich wyniki opierają się na symulacjach bez szumów sprzętowych i na stosunkowo niewielkich zbiorach danych, więc pełne zrealizowanie tych zysków na rzeczywistych maszynach kwantowych i na większą skalę pozostaje istotnym wyzwaniem na przyszłość.
Cytowanie: Jha, R.K., Kasabov, N., Bhattacharyya, S. et al. Comparative performance analysis of quantum feature maps for quantum kernel-based machine learning. Sci Rep 16, 8142 (2026). https://doi.org/10.1038/s41598-026-39392-9
Słowa kluczowe: kwantowe uczenie maszynowe, jądra kwantowe, mapy cech, strojenie hiperparametrów, klasyfikacja